Intuiții privind regularizarea L1 și L2
On septembrie 20, 2021 by admin0) Ce este L1 și L2?
Regularizarea L1 și L2 își datorează numele normei L1 și, respectiv, L2 a unui vector w. Iată o introducere în norme:
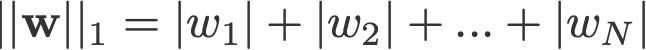


<modificați log: a omis să ia valorile absolute pentru 2-norm și p-norm>
Un model de regresie liniară care implementează norma L1 pentru regularizare se numește regresie lasso, iar unul care implementează norma L2 (la pătrat) pentru regularizare se numește regresie ridge. Pentru a le implementa pe acestea două, rețineți că modelul de regresie liniară rămâne același:
dar calculul funcției de pierdere este cel care include acești termeni de regularizare:

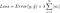
. 
Nota: Strict vorbind, ultima ecuație (regresie ridge) este o funcție de pierdere cu normă L2 pătrată a ponderilor (observați absența rădăcinii pătrate). (Mulțumim lui Max Pechyonkin pentru că a evidențiat acest lucru!)
Termenii de regularizare sunt „constrângeri” la care un algoritm de optimizare trebuie să „adere” atunci când minimizează funcția de pierdere, în afară de faptul că trebuie să minimizeze eroarea dintre adevăratul y și cel prezis ŷ.
1) Model
Să definim un model pentru a vedea cum funcționează L1 și L2. Pentru simplitate, definim un model simplu de regresie liniară ŷ cu o singură variabilă independentă.

Aici am folosit convențiile de învățare profundă w („weight”) și b („bias”).
În practică, modelele simple de regresie liniară nu sunt predispuse la supraadaptare. După cum s-a menționat în introducere, modelele de învățare profundă sunt mai susceptibile la astfel de probleme din cauza complexității modelului lor.
Ca atare, rețineți că expresiile utilizate în acest articol sunt ușor de extins la modele mai complexe, care nu se limitează la regresia liniară.
2) Funcții de pierdere
Pentru a demonstra efectul regularizării L1 și L2, să ajustăm modelul nostru de regresie liniară folosind 3 funcții de pierdere/obiective diferite:
- L
- L1
- L2
Obiectivul nostru este să minimizăm aceste pierderi diferite.
2.1) Funcția de pierdere fără regularizare
Definim funcția de pierdere L ca fiind eroarea la pătrat, unde eroarea este diferența dintre y (valoarea reală) și ŷ (valoarea prezisă).

Să presupunem că modelul nostru va fi supraadaptat folosind această funcție de pierdere.
2.2) Funcția de pierdere cu regularizare L1
Pe baza funcției de pierdere de mai sus, adăugarea unui termen de regularizare L1 la aceasta arată astfel:

unde parametrul de regularizare λ > 0 este reglat manual. Să numim această funcție de pierdere L1. Rețineți că |w| este diferențiabilă peste tot, cu excepția cazului în care w=0, așa cum se arată mai jos. Vom avea nevoie de acest lucru mai târziu.

2.3) Funcția de pierdere cu regularizare L2
În mod similar, adăugarea unui termen de regularizare L2 la L arată astfel:

unde din nou, λ > 0.
3) Gradient Descent
Acum, să rezolvăm modelul de regresie liniară utilizând optimizarea prin coborârea gradientului pe baza celor 3 funcții de pierdere definite mai sus. Reamintim că actualizarea parametrului w în gradient descent se face după cum urmează:
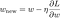
Să înlocuim ultimul termen din ecuația de mai sus cu gradientul lui L, L1 și L2 w.r.t. w.
L:

L1:

L2:

4) Cum se previne supraadaptarea?
De aici încolo, să efectuăm următoarele substituții asupra ecuațiilor de mai sus (pentru o mai bună lizibilitate):
- η = 1,
- H = 2x(wx+b-y)
care ne dau
L:

L1:
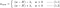
L2:
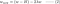
4.1) With vs. Without Regularisation
Observați diferențele dintre actualizările ponderilor cu parametrul de regularizare λ și fără acesta. Iată câteva intuiții.
Intuiția A:
Să spunem că, cu Ecuația 0, calculul w-H ne dă o valoare w care duce la supraajustare. Atunci, intuitiv, Ecuațiile {1.1, 1.2 și 2} vor reduce șansele de supraajustare, deoarece introducerea lui λ ne face să ne îndepărtăm chiar de w care urma să ne cauzeze probleme de supraajustare în propoziția anterioară.
Intuiția B:
Să spunem că un model supraajustat înseamnă că avem o valoare w care este perfectă pentru modelul nostru. ‘Perfectă’ înseamnă că dacă am înlocui datele (x) înapoi în model, predicția noastră ŷ va fi foarte, foarte aproape de adevăratul y. Sigur, este bună, dar nu vrem să fie perfectă. De ce? Pentru că acest lucru înseamnă că modelul nostru este menit doar pentru setul de date pe care ne-am antrenat. Acest lucru înseamnă că modelul nostru va produce predicții care sunt foarte departe de valoarea reală pentru alte seturi de date. Așa că ne mulțumim cu mai puțin decât perfect, cu speranța că modelul nostru poate obține predicții apropiate și cu alte date. Pentru a face acest lucru, „pătăm” acest w perfect din Ecuația 0 cu un termen de penalizare λ. Acest lucru ne dă Ecuațiile {1.1, 1.2 și 2}.
Intuiția C:
Atenție că H (așa cum este definit aici) depinde de model (w și b) și de date (x și y). Actualizarea ponderilor pe baza doar a modelului și a datelor din ecuația 0 poate duce la supraadaptare, ceea ce duce la o generalizare slabă. Pe de altă parte, în Ecuațiile {1.1, 1.2 și 2}, valoarea finală a lui w nu este influențată doar de model și de date, ci și de un parametru predefinit λ, care este independent de model și de date. Astfel, putem preveni supraadaptarea dacă stabilim o valoare adecvată a lui λ, deși o valoare prea mare va face ca modelul să fie grav subadaptat.
Intuiția D:
Edden Gerber (mulțumiri!) a oferit o intuiție cu privire la direcția spre care se deplasează soluția noastră. Aruncați o privire în comentarii: https://medium.com/@edden.gerber/thanks-for-the-article-1003ad7478b2
4.2) L1 vs. L2
Ne vom concentra acum atenția asupra lui L1 și L2 și vom rescrie ecuațiile {1.1, 1.2 și 2} prin rearanjarea termenilor lor λ și H după cum urmează:
L1:
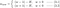
L2:
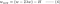
Comparați cel de-al doilea termen al fiecăreia dintre ecuațiile de mai sus. În afară de H, modificarea lui w depinde de termenul ±λ sau de termenul -2λw, care evidențiază influența următoarelor:
- semnul curentului w (L1, L2)
- magnitudinea curentului w (L2)
- dublarea parametrului de regularizare (L2)
În timp ce actualizările ponderilor folosind L1 sunt influențate de primul punct, actualizările ponderilor din L2 sunt influențate de toate cele trei puncte. Deși am făcut această comparație doar pe baza actualizării iterative a ecuației, vă rog să rețineți că acest lucru nu înseamnă că una este „mai bună” decât cealaltă.
Pentru moment, să vedem mai jos cum se poate obține un efect de regularizare din L1 doar prin semnul curentului w.
4.3) Efectul L1 asupra împingerii spre 0 (sparsity)
Aruncați o privire la L1 din Ecuația 3.1. Dacă w este pozitiv, parametrul de regularizare λ>0 va împinge w să fie mai puțin pozitiv, prin scăderea lui λ din w. Invers, în Ecuația 3.2, dacă w este negativ, λ va fi adăugat la w, împingându-l să fie mai puțin negativ. Prin urmare, acest lucru are ca efect împingerea lui w spre 0.
Acest lucru este, desigur, inutil într-un model de regresie liniară cu o singură variabilă, dar își va dovedi măiestria de a „elimina” variabilele inutile în modelele de regresie multivariate. De asemenea, vă puteți gândi la L1 ca la o reducere totală a numărului de caracteristici din model. Iată un exemplu arbitrar de L1 care încearcă să „împingă” unele variabile într-un model de regresie liniară multivariată:
Atunci cum ajută împingerea lui w spre 0 la supraadaptarea în regularizarea L1? După cum s-a menționat mai sus, pe măsură ce w se îndreaptă spre 0, reducem numărul de caracteristici prin reducerea importanței variabilelor. În ecuația de mai sus, vedem că x_2, x_4 și x_5 sunt aproape „inutile” din cauza coeficienților lor mici, prin urmare le putem elimina din ecuație. Acest lucru reduce, la rândul său, complexitatea modelului, ceea ce face ca modelul nostru să fie mai simplu. Un model mai simplu poate reduce șansele de supraadaptare.
Nota
În timp ce L1 are influența de a împinge ponderile spre 0, iar L2 nu, acest lucru nu implică faptul că ponderile nu sunt capabile să ajungă aproape de 0 datorită lui L2.
.
Lasă un răspuns