Vihjeitä L1- ja L2-säännöstelystä
On 20 syyskuun, 2021 by admin0) Mitä ovat L1 ja L2?
L1- ja L2-säännöstely on saanut nimensä vektorin w L1- ja L2-normista. Tässä on alkuopas normeista:
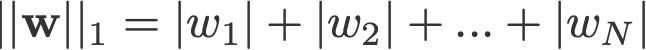


<muutos log: missed out taking the absolutes for 2-norm and p-norm>
Lineaarista regressiomallia, joka toteuttaa L1-normin regularisointia varten, kutsutaan lasso-regressioksi, ja mallia, joka toteuttaa (neliöllisen) L2-normin regularisointia varten, kutsutaan ridge-regressioksi. Näiden kahden toteuttamiseksi on huomattava, että lineaarinen regressiomalli pysyy samana:
mutta häviöfunktion laskenta sisältää nämä regularisointitermit:

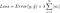
.

Huom: Tarkkaan ottaen viimeinen yhtälö (harjuregressio) on häviöfunktio, jossa painojen L2-normi on neliö (huomaa neliöjuuren puuttuminen). (Kiitos Max Pechyonkin tämän korostamisesta!)
Regularisointiehdot ovat ”rajoitteita”, joita optimointialgoritmin on ”noudatettava” minimoidessaan häviöfunktiota, sen lisäksi, että sen on minimoitava todellisen y:n ja ennustetun ŷ:n välinen virhe.
1) Malli
Määritellään malli, jotta nähdään, miten L1 ja L2 toimivat. Yksinkertaisuuden vuoksi määrittelemme yksinkertaisen lineaarisen regressiomallin ŷ, jossa on yksi riippumaton muuttuja.
Tässä olen käyttänyt syväoppimisen konventioita w (’weight’) ja b (’bias’).
Käytännössä yksinkertaiset lineaariset regressiomallit eivät ole alttiita ylisovitukselle. Kuten johdannossa mainittiin, syväoppimismallit ovat alttiimpia tällaisille ongelmille mallin monimutkaisuuden vuoksi.
Huomaa siis, että tässä artikkelissa käytetyt ilmaisut ovat helposti laajennettavissa monimutkaisempiin malleihin, jotka eivät rajoitu lineaariseen regressioon.
2) Häviöfunktiot
L1- ja L2-regularisoinnin vaikutuksen havainnollistamiseksi sovitetaan lineaarinen regressiomallimme käyttäen kolmea erilaista häviöfunktiota/tavoitetta:
- L
- L1
- L1
- L2
Tavoitteemme on minimoida nämä erilaiset häviöt.
2.1) Häviöfunktio ilman regularisointia
Määrittelemme häviöfunktion L neliövirheeksi, jossa virhe on y:n (todellinen arvo) ja ŷ:n (ennustettu arvo) välinen erotus.
>>
Emme oleta, että mallimme tulee ylisopeutetuksi tätä häviöfunktiota käyttäen.
2.2) Häviöfunktio L1-regularisoinnilla
Yllä olevan häviöfunktion perusteella L1-regularisointitermin lisääminen siihen näyttää seuraavalta:

>
jossa regularisointitekijä λ λ > 0 on manuaalisesti säädetty. Kutsutaan tätä häviöfunktiota L1:ksi. Huomaa, että |w| on differentioituva kaikkialla paitsi silloin, kun w=0, kuten alla on esitetty. Tarvitsemme tätä myöhemmin.

2.3) Häviöfunktio L2-regularisoinnilla
Vastaavasti L:ään lisättävä L2-regularisointitermi näyttää seuraavalta:

jossa taas λ > 0.
3) Gradienttilaskeutuminen
Ratkotaan nyt lineaarinen regressiomalli käyttämällä gradienttilaskeutumisoptimointia, joka perustuu edellä määriteltyihin kolmeen tappiofunktioon. Muistutetaan, että parametrin w päivittäminen gradienttilaskeutumisessa tapahtuu seuraavasti:
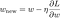
Substituoidaan yllä olevan yhtälön viimeinen termi L:n, L1:n ja L2:n gradientilla w:n suhteen.
L:

L1:

L2:

4) Miten ylisovittaminen estetään?
Tehdään tästä eteenpäin seuraavat korvaukset yllä oleville yhtälöille (paremman luettavuuden vuoksi):
- η = 1,
- H = 2x(wx+b-y)
jotka antavat meille
L:

L1:
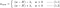
L2:
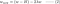
4.1) Säännöstelyn kanssa vs. ilman säännöstelyä
Huomaa erot painojen päivitysten välillä säännöstelyparametrin λ kanssa ja ilman sitä. Seuraavassa on joitakin intuitioita.
Intuition A:
Sitotaan, että yhtälöllä 0 laskemalla w-H saadaan w-arvo, joka johtaa ylisovittamiseen. Silloin intuitiivisesti yhtälöt {1.1, 1.2 ja 2} vähentävät ylisovituksen mahdollisuutta, koska λ:n käyttöönotto saa meidät siirtymään pois juuri siitä w:stä, joka edellisessä lauseessa aikoi aiheuttaa meille ylisovitusongelmia.
Toteamus B:
Sitotaan, että ylisovitettu malli tarkoittaa sitä, että meillä on w:n arvo, joka on mallillemme täydellinen. ’Täydellinen’ tarkoittaa, että jos korvaisimme datan (x) takaisin malliin, ennusteemme ŷ olisi hyvin, hyvin lähellä todellista y:tä. Toki se on hyvä, mutta emme halua täydellistä. Miksi? Koska tämä tarkoittaa, että mallimme on tarkoitettu vain sille datajoukolle, johon olemme kouluttaneet. Tämä tarkoittaa, että mallimme tuottaa ennusteita, jotka ovat kaukana todellisesta arvosta muissa tietokokonaisuuksissa. Tyydymme siis vähempään kuin täydelliseen siinä toivossa, että mallimme pystyy saamaan läheisiä ennusteita myös muilla aineistoilla. Tätä varten ”tahraamme” tämän täydellisen w:n yhtälössä 0 rangaistustermillä λ. Näin saamme yhtälöt {1.1, 1.2 ja 2}.
Toteamus C:
Huomaa, että H (sellaisena kuin se on määritelty tässä) on riippuvainen mallista (w ja b) ja datasta (x ja y). Painojen päivittäminen vain mallin ja datan perusteella yhtälössä 0 voi johtaa ylisovittamiseen, mikä johtaa huonoon yleistettävyyteen. Toisaalta yhtälöissä {1.1, 1.2 ja 2} w:n lopulliseen arvoon eivät vaikuta ainoastaan malli ja data, vaan myös ennalta määritelty parametri λ, joka on riippumaton mallista ja datasta. Siten voimme estää ylisovittamisen, jos asetamme λ:lle sopivan arvon, vaikka liian suuri arvo aiheuttaakin mallin pahasti alisovittamisen.
Intuition D:
Edden Gerber (kiitos!) on antanut intuition siitä, mihin suuntaan ratkaisumme on siirtymässä. Käykää katsomassa kommenteissa: https://medium.com/@edden.gerber/thanks-for-the-article-1003ad7478b2
4.2) L1 vs. L2
Keskeytämme nyt huomiomme L1:een ja L2:een ja kirjoitamme yhtälöt {1.1, 1.2 ja 2} järjestämällä niiden λ- ja H-termit uudelleen seuraavasti:
L1:
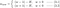
L2:
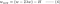
Vertaile kunkin yllä olevan yhtälön toista termiä. H:n lisäksi w:n muutos riippuu ±λ-termistä tai -2λw-termistä, jotka korostavat seuraavien tekijöiden vaikutusta:
- virran w:n merkki (L1, L2)
- virran w:n suuruus (L2)
- regularisointiparametrin kaksinkertaistuminen (L2)
Mikäli L1:n avulla tehtäviin painojen päivityksiin vaikuttaa ensimmäinen kohta, niin L2:n avulla tehtäviin painojen päivityksiin vaikuttavat kaikki kolme kohtaa. Vaikka olen tehnyt tämän vertailun vain iteratiivisen yhtälön päivityksen perusteella, huomaa, että tämä ei tarkoita, että toinen olisi ”parempi” kuin toinen.
Katsotaan seuraavassa, miten L1:llä saavutetaan regularisointivaikutus pelkästään nykyisen w:n merkin avulla.
4.3) L1:n vaikutus työntymiseen kohti 0:aa (harvinaisuus)
Katsotaan L1:tä yhtälössä 3.1. Jos w on positiivinen, regularisointiparametri λ>0 työntää w:tä vähemmän positiiviseksi vähentämällä λ:n w:stä. Vastaavasti yhtälössä 3.2, jos w on negatiivinen, λ lisätään w:hen, mikä työntää sitä vähemmän negatiiviseksi. Näin ollen tämä vaikuttaa siten, että w:tä työnnetään kohti 0:a.
Tämä on tietysti turhaa yhden muuttujan lineaarisessa regressiomallissa, mutta se osoittautuu päteväksi hyödyttömien muuttujien ”poistamisessa” monimuuttujaisissa regressiomalleissa. Voit myös ajatella L1:n vähentävän ominaisuuksien määrää mallissa kokonaan. Tässä mielivaltainen esimerkki siitä, kuinka L1 yrittää ’työntää’ joitakin muuttujia monimuuttujaisessa lineaarisessa regressiomallissa:
Miten siis w:n työntäminen kohti 0:aa auttaa L1-regularisoinnissa ylisovittamisessa? Kuten edellä mainittiin, kun w menee kohti 0:a, vähennämme piirteiden määrää vähentämällä muuttujien tärkeyttä. Yllä olevasta yhtälöstä näemme, että x_2, x_4 ja x_5 ovat lähes ”hyödyttömiä” niiden pienten kertoimien vuoksi, joten voimme poistaa ne yhtälöstä. Tämä puolestaan vähentää mallin monimutkaisuutta, mikä tekee mallistamme yksinkertaisemman. Yksinkertaisempi malli voi vähentää ylisovituksen mahdollisuutta.
Huomautus
Kun L1 vaikuttaa painojen työntämiseen kohti 0:aa ja L2 ei, tämä ei tarkoita, etteivätkö painot pääsisi lähelle 0:aa L2:n ansiosta.
Vastaa