Vad är autoenkoder?
On november 11, 2021 by adminEn lätt introduktion till autoenkoder och dess olika användningsområden,TensorFlows Python-API på hög nivå för att bygga och träna modeller för djupinlärning.
常常見到 Autoencoder 的變形以及應用,打算花幾篇的時間好好的研究一下,順便練習 Tensorflow.keras 的 API 使用。
- Vad är autokodare
- Typer av autokodare
- Användning av autokodare
- Implementering
- Goda exempel
- Slutsats
Svårighetsgrad: ★ ★ ☆ ☆ ☆ ☆
後記: 由於 Tensorflow 2.0 alpha 已於 3/8號釋出,但此篇是在1月底完成的,故大家可以直接使用安裝使用看看,但需要更新至相對應的 CUDA10。
Vad är Autoencoder?
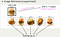
首先,什麼是 Autoencoder 呢? 不囉唆,先看圖吧!

Det ursprungliga konceptet för Autoencoder är mycket enkelt, det går ut på att kasta in en inmatningsdata och få exakt samma data som inmatningsdata genom ett neuralt nätverk.Kodaren tar först emot indata, komprimerar den till en mindre dimensionell vektor Z och matar sedan in Z i avkodaren för att återställa Z till sin ursprungliga storlek.Det låter enkelt, men låt oss ta en närmare titt och se om det är så enkelt.

Kodare:
Kodare ansvarar för att komprimera de ursprungliga indata till en lågdimensionell vektor C. Denna C, som vi vanligtvis kallar kod, latent vektor eller funktionsvektor, men jag brukar kalla den latent space, eftersom C representerar en dold funktion.Encoder kan komprimera originaldata till en meningsfull lågdimensionell vektor, vilket innebär att Autoencoder har dimensionalitetsreducering, och det dolda lagret har en icke-linjär transformationsaktiveringsfunktion, så denna Encoder är som en kraftfull version av PCA, eftersom Encoder kan göra icke-linjäraDimensionsminskning!
Decoder:
Vad Decoder gör är att återställa latent utrymme tillbaka till indata så mycket som möjligt, vilket är en omvandling av funktionsvektorerna från det lägre dimensionella utrymmet till det högre dimensionella utrymmet.
Så hur mäter du hur väl Autoencoder fungerar! Detta görs helt enkelt genom att jämföra likheten mellan de två ursprungliga indata och de rekonstruerade data.Så vår förlustfunktion kan skrivas som ….
Förlustfunktion:

Eftersom vi vill minimera skillnaden mellanAutoEncoder tränas med hjälp av backpropagation för att uppdatera vikterna, precis som ett normalt neuralt nätverk.uppdatera vikterna.
Sammanfattningsvis är Autoencoder ….
1. En mycket vanlig modellarkitektur, som också ofta används för oövervakad inlärning
2. Kan användas som en metod för dimensionsminskning för icke-linjära
3. Kan användas för att lära sig datarepresentation, representativ funktionstransformation.
Vid det här laget borde det vara lätt att förstå hur Autoencoder fungerar, arkitekturen är mycket enkel, så låt oss ta en titt på dess transformationer!
Typer av Autoencoder
Efter att ha förklarat de grundläggande principerna för AutoEncoder är det dags att ta en titt på den utökade och avancerade användningen av Autoencoder, så att du kan se den omfattande användningen av Autoencoder!
2-1. Unet:
Unet kan användas som ett sätt att segmentera bilder, och Unet-arkitekturen kan ses som en variant av Autoencoder.

2-2. Rekursiva autoenkoder:
Detta är ett nätverk som kombinerar ny inmatningstext med latent utrymme från andra inmatningar.Detta kan också ses som en variant av Autoencoder, som extraherar den glesa texten medan den skrivs och hittar det latenta utrymme som är viktigt.

2-Seq2Seq:
Sequence to Sequence är en generativ modell som har varit mycket populär ett tag nu. Det är en underbar lösning på dilemmat med RNN-typer som inte kan hantera obestämda parningar, och den har fungerat bra på ämnen som chatbot- och textgenerering.Detta kan också ses som ett slags Autoencoder-arkitektur.

Användningar av autokodare
Efter att ha tittat på de många och varierande varianterna av Autoencoder, låt oss se var Autoencoder annars kan användas!
3-1. Förinlärd vikt för modellen
Autoenkoder kan också användas för förinlärning av vikt, vilket innebär att modellen hittar ett bättre startvärde.När vi till exempel vill slutföra målmodellen, t.ex. mål, är det dolda lagret:, så i början använder vi begreppet autoencoder för att mata in 784 dimensioner, och det latenta utrymmet i mitten är 1000 dimensioner för att göra förträningen först, så att dessa 1000 dimensioner väl kan behålla inmatningen.Sedan tar vi bort den ursprungliga utgången och lägger till det andra lagret, och så vidare.På så sätt får hela modellen ett bättre startvärde.
Huh! Det finns en konstig del… om du använder 1000 neuroner för att representera 784 inmatningsdimensioner, betyder det då inte att nätverket bara måste kopieras på nytt? Vad är meningen med utbildningen? Ja, det är därför vi i en sådan här förträning brukar lägga till L1-normregleraren så att det dolda lagret inte kopieras om och om igen.

Enligt Li HongyiTidigare var det vanligare att använda en sådan metod för förträning, men på grund av den ökade träningskompetensen finns det numera inget behov av att använda denna metod längre.Men om du har väldigt lite märkningsdata men en massa omärkta data kan du använda den här metoden för att göra viktförberedande träning eftersom Autoencoder i sig själv är en oövervakad inlärningsmetod, vi använder de omärkta data för att få viktförberedande träning först, och använder sedan de omärkta data för att få viktförberedande träning.Vi använder de omärkta uppgifterna för att först få fram en förträning av vikterna och använder sedan de märkta uppgifterna för att finjustera vikterna så att vi kan få en bra modell.För mer information, se Li’s video, den är mycket väl förklarad!
3-2. Bildsegmentering
Unet-modellen som vi just såg, låt oss titta på den igen, eftersom det i princip är det vanligaste problemet med att upptäcka defekter i Taiwans tillverkningsindustri.
Först måste vi märka inmatningsdata, som kommer att bli vårt resultat. Vi måste konstruera ett nätverk, mata in originalbilden (till vänster, tandröntgenbilder) och generera resultatet (till höger, klassificering av tandstrukturen).I det här fallet kommer kodaren & avkodaren att vara ett konvolutionslager med en stark grafisk bedömning, som extraherar meningsfulla egenskaper och dekonvolutionerar tillbaka till avkodaren för att erhålla segmenteringsresultatet.

3-3. Video till text
För ett bildtextproblem som detta använder vi sekvens till sekvens-modellen, där indata är ett antal foton och utdata är en text som beskriver fotona.Sekvens till sekvens-modellen använder LSTM + Conv net som kodare & avkodare, som kan beskriva en sekvens av sekventiella handlingar & med hjälp av CNN-kärnan för att extrahera det latenta utrymme som krävs i bilden.men denna uppgift är mycket svår att utföra, så jag låter dig prova om du är intresserad!

3-4. Bildhämtning
Bildhämtning Det man kan göra är att mata in en bild och försöka hitta den närmaste överensstämmelsen, men om man jämför pixelvis är det väldigt enkelt attOm du använder Autoencoder för att först komprimera bilden till latent utrymme och sedan beräkna likheten i bildens latenta utrymme blir resultatet mycket bättre.Resultatet blir mycket bättre eftersom varje dimension i det latenta utrymmet kan representera en viss egenskap.Om avståndet beräknas på det latenta utrymmet är det rimligt att hitta liknande bilder.Detta skulle i synnerhet vara ett utmärkt sätt att lära sig utan övervakning, utan att märka data!
Här finnsI artikeln av Georey E. Hinton, den berömda Deep Learning-gudinnan, visas grafen du vill söka efter i det övre vänstra hörnet, medan de andra graferna är grafer som autoenkodern anser vara mycket lika.7133>

innehållsbaseradeImage Retrieval
3-5. Anomaly Detection
Inte hitta någon bra bild, så jag var tvungen att använda den här LOL
Att hitta anomalier är också ett mycket vanligt tillverkningsproblem, så det här problemet kan också prövas med Autoencoder.Vi kan prova det med Autoencoder!Låt oss först och främst tala om den faktiska förekomsten av anomalier. Anomalier förekommer vanligtvis mycket sällan, till exempel onormala signaler i maskinen, plötsliga temperaturspikar …… osv.Detta sker en gång i månaden (om det sker oftare bör maskinen tvingas gå i pension). Om data samlas in var 10:e sekund kommer 260 000 data att samlas in varje månad, men endast en tidsperiod är avvikande, vilket faktiskt är en mycket obalanserad mängd data.
Så det bästa sättet att hantera den här situationen är att använda originaldata, som trots allt är den största mängden data vi har!Om vi kan ta bra data och träna en bra autoenkoder, kommer den rekonstruerade grafiken naturligtvis att brista om det kommer in anomalier.Det var så vi började med idén om att använda autoencoder för att hitta anomalier!

Implementation
Här använder vi Mnist som ett leksaksexempel och implementerar en autokodare med hjälp av högnivå-API:et Tensorflow.keras! Eftersom det nya paketet för tf.keras släpptes inom kort övar vi på att använda underklassningsmetoden Model i filen
4-1. Skapa en modell – Vallina_AE:
Importera först tensorflow!7133>

Användningen av tf.keras är så enkel, skriv bara tf.keras!(Jag vet inte vad jag pratar om lol)
Lad data & model preprocess
Först tar vi Mnist-data från tf.keras.dataset och gör en liten preprocess
Nominalisering: komprimerar värdena till mellan 0 och 1, det blir lättare att konvergera vid träning
Binärisering: framhäver de tydligare områdena, träningen ger bättre resultat.
Skapa en modell – Vallina_AE:
Detta är den metod som tillhandahålls i Tensorflowdokumentet för att skapa modeller.mer komplexa.
Det jag har lärt mig hittills är att skapa lagret i __init __ och definiera forward pass i anropet.
Så vi använder två sekventiella modeller för att skapa Encoder & decoder. två är en symmetrisk struktur, encodern är ansluten till inmatningsskiktet som ansvarar för att bära inmatningsdata och sedan till de tre täta skikten. decodern är densamma.
Återigen, under anropet, måste vi sammanlänka kodaren & avkodaren, genom att först definiera det latenta utrymmet som utgångspunkt för self.encoder.som utgång från self.encoder, och sedan rekonstruktionen som resultatet av att avkodaren passeras.Vi använder sedan tf.keras.Model() för att koppla ihop de två modeller som vi definierade i __init__.AE_model = tf.keras.Model(inputs = self.encoder.input, outputs = reconstruction) anger input som ingång för kodaren och output som utgång för avkodaren, och det är allt!Sedan returnerar vi AE_modellen och du är klar!
Modellkompilering & träning
Innan Keras kan träna en modell måste den kompileras innan den kan läggas in i träningen.I kompileringen anger du vilken optimerare du vill använda och vilken förlust du vill beräkna.
För träning använder du VallinaAE.fit för att mata in data, men kom ihåg att vi återställer oss själva, så X och Y måste kastas in i samma data.
Låt oss ta en titt på resultaten av träningen av 100 epoker, det ser ut som om rekonstruktionsresultaten inte är så bra som vi trodde.

4-2. Skapa en modell- Conv_AE:
Som namnet antyder kan vi använda konvolutionslagret som ett dolt lager för att lära oss funktioner som kan rekonstrueras tillbaka.
När du har ändrat modellen kan du titta på resultaten för att se om de har förbättrats.

Det verkar som om resultaten av Rekonstruktion är mycket bättre, med ungefär 10 epoker av träning.
4-3. Skapa en modell – denoise_AE:
Den automatiska kodernan kan också användas för att avlägsna brus, så här
Först kan vi lägga till brus i originalbilden. Logiken för att lägga till brus är att göra en enkel förskjutning av originalpixeln och sedan lägga till slumpmässiga tal.Förbehandlingen av bilden kan göras genom att klippet helt enkelt blir 0 om det är mindre än 0 och 1 om det är större än 1. Som visas nedan kan vi efter bildbehandlingen av klippet göra bilden skarpare och de uppenbara områdena blir mer synliga.Detta ger oss ett bättre resultat när vi använder Autoencoder.

och själva modellen och Conv_AEDet finns ingen skillnad mellan själva modellen och Conv_AE, förutom att den under anpassningen måste ändras till
denoise_AE.fit(train_images_noise, train_images, epochs=100, batch_size=128, shuffle=True)
för att återställa de ursprungliga noise_data till de ursprungliga indata

.
Som du kan se kan en enkel autokodare på Mnist uppnå en mycket snabb denoising-effekt.
Goda exempel
Detta är en bra resurs för dem som är intresserade av att lära sig mer om det
- Building Autoencoders in Keras autoencoder-serien är tydligt skriven.
- Tensorflow 2.0 officiella dokumentation handledning, något mycket komplett, bara skriva lite svårt, att spendera en hel del tid att se (åtminstone jag dra XD)
3. Li Hongyi lärare i djupinlärning är också mycket rekommenderat, tala mycket tydligt och lätt att förstå, icke-
Slutsats
Använd den här artikeln för att snabbt fastställa grundkonceptet för Autoencoder, några varianter av Autoencoder och tillämpningen av Autoencoder.scenarier.4310>
De kommande artiklarna kommer att börja med generativa modeller och sträcka sig från begreppet autoencoder, VAE, till GAN och ytterligare utvidgningar och förändringar längs vägen.
Om du gillar artikeln kan du klicka några fler klappar (inte bara en gång) som en uppmuntran!
Läs hela koden för denna artikel:https://github.com/EvanstsaiTW/Generative_models/blob/master/AE_01_keras.ipynb
Lämna ett svar