SQL CHIT CHAT … Blogg om Sql Server
On november 29, 2021 by adminSammanfattning
Common Table Expressions introducerades i SQL Server 2005. De utgör en av flera typer av tabelluttryck som finns tillgängliga i Sql Server. Ett rekursivt CTE är en typ av CTE som refererar till sig själv. Den används vanligtvis för att lösa hierarkier.
I det här inlägget kommer jag att försöka förklara hur CTE-rekursion fungerar, var den befinner sig i gruppen av tabelluttryck som är tillgängliga i Sql Server och några fallscenarier där rekursionen briljerar.
Tabelluttryck
Ett tabelluttryck är ett namngivet frågeuttryck som representerar en relationell tabell. Sql Server stöder fyra typer av tabelluttryck;
- Avledda tabeller
- Vyer
- ITVF (Inline Table Valued Functions aka parameteriserade vyer)
- CTE (Common Table Expressions)
- Rekursiv CTE
I allmänhet materialiseras inte tabelluttryck på disken. De är virtuella tabeller som endast finns i RAM-minnet (de kan spridas till disken till följd av t.ex. minnestryck, storleken på en virtuell tabell etc.). Tabelluttryckens synlighet kan variera, dvs. vyer och ITVF är db-objekt som är synliga på databasnivå, medan deras räckvidd alltid är på SQL-uttalsnivå – tabelluttryck kan inte verka i olika SQL-uttalanden inom en batch.
Fördelarna med tabelluttryck är inte relaterade till prestanda i fråga om utförande av frågor, utan till den logiska aspekten av koden !
Avledda tabeller
Avledda tabeller är tabelluttryck, som också kallas för underfrågor. Uttrycken definieras i FROM-klausulen i en yttre fråga. Omfattningen av härledda tabeller är alltid den yttre frågan.
Följande kod representerar en härledd tabell som heter AUSCust.
Transact-SQL
|
1
2
3
3
4
5
6
7
8
|
SELECT AUSCust.*
FROM (
SELECT custid
,companyname
FROM dbo.Customers
WHERE country = N’Australia’
) AS AUSCust;
–AUSCust är en härledd tabell
|
Den härledda tabellen AUSCust är endast synlig för den yttre frågan och räckvidden är begränsad till sql-angivelsen.
Vyer
Vyer (ibland kallade virtuella relationer) är återanvändbara tabelluttryck. En vydefinition lagras som ett Sql Server-objekt tillsammans med objekt som t.ex. användardefinierade tabeller, triggers, funktioner, lagrade procedurer etc.
Den största fördelen med vyer jämfört med andra typer av tabelluttryck är att de kan återanvändas, dvs. härledda frågor och CTE har en räckvidd som är begränsad till ett enda uttalande.
Vyer materialiseras inte, vilket innebär att de rader som produceras av vyer inte lagras permanent på disken. Indexerade vyer är Sql Server (liknande men inte samma som materialiserade vyer i andra databaser) är en speciell typ av vyer som kan ha sin resultatuppsättning permanent lagrad på disken – mer om indexerade vyer finns här.
Bara några grundläggande riktlinjer för hur man definierar SQL Views.
-
SELECT * i samband med en View-definition uppför sig annorlunda än när den används som ett frågeelement i en batch.
Transact-SQL
12345CREATE VIEW dbo.vwTestASSELECT *FROM dbo.T1…Vyns definition kommer att inkludera alla kolumner från den underliggande tabellen dbo.T1 vid tidpunkten för skapandet av vyn. Detta innebär att om vi ändrar tabellschemat (dvs. lägger till och/eller tar bort kolumner) kommer ändringarna inte att vara synliga för vyn – vyns definition kommer inte automatiskt att ändras för att stödja tabelländringarna. Detta kan orsaka fel i situationer när en vy försöker välja icke-existerande kolumner från en underliggande tabell.
För att åtgärda problemet kan vi använda en av de två systemprocedurerna: sys.sp_refreshview eller sys.sp_refreshsqlmodule.
För att förhindra detta beteende bör man följa bästa praxis och uttryckligen namnge kolumnerna i definitionen av vyn. - Vyer är tabellauttryck och kan därför inte beställas. Vyer är inte markörer! Det är dock möjligt att ”missbruka” TOP/ORDER BY-konstruktionen i vydefinitionen för att försöka tvinga fram en sorterad utskrift, t.ex.
Transact-SQL
12345CREATE VIEW dbo.MyCursorViewASSELECT TOP(100 PERCENT) *FROM dbo.SomeTableORDER BY column1 DESCQuery Optimizer kommer att kasta TOP/ORDER BY eftersom resultatet av ett tabelluttryck alltid är en tabell – att välja TOP(100 PERCENT) är ändå meningslöst. Idén bakom tabellstrukturer härstammar från ett begrepp i relationell databasteknik som kallas Relation.
-
Vid behandling av en fråga som hänvisar till en vy, blir frågan från vydefinitionen utbredd eller expanderad och implementerad i samband med huvudfrågan. Den konsoliderade koden (frågan) optimeras och utförs sedan.
ITVF (Inline Table Valued Functions)
ITVF:er är återanvändbara tabelluttryck som har stöd för inmatningsparametrar. Funktionerna kan behandlas som parametriserade vyer.
CTE (Common Table Expressions)
Common table expressions liknar härledda tabeller men har flera viktiga fördelar;
En CTE definieras med hjälp av en WITH-angivelse, följt av en definition av ett tabelluttryck. För att undvika tvetydighet (TSQL använder nyckelordet WITH för andra ändamål, t.ex. WITH ENCRYPTION etc.) MÅSTE det uttalande som föregår CTE:s WITH-klausul avslutas med en halvkolumn. Detta är inte nödvändigt om WITH-klausulen är det allra första uttalandet i en batch, dvs. i en VIEW/ITVF-definition)
OBSERVERA: Halvkolumnen som avslutar uttalandet stöds av ANSI-standarden och det rekommenderas starkt att den används som en del av TSQL-programmeringspraxis.
Rekursiv CTE
SQL Server har stöd för rekursivt sökande som implementeras med hjälp av rekursiva CTE:er sedan version 2005 (Yukon).
Element i en rekursiv CTE
- Ankarmedlemmar – Frågedefinitioner som;
- återger en giltig relationell resultattabell
- utförs ENDAST EN GÅNG i början av frågeutförandet
- placeras alltid före den första definitionen av en rekursiv medlem
- Den sista ankarmedlemmen måste följas av UNION ALL-operatören. Operatören kombinerar den sista ankarmedlemmen med den första rekursiva medlemmen
- UNION ALL multi-set operator. Operatören verkar på
- Rekursiva medlemmar – Frågedefinitioner som;
- återger en giltig relationell resultattabell
- har en hänvisning till CTE-namnet. Referensen till CTE-namnet representerar logiskt sett den föregående resultatuppsättningen i en sekvens av utföranden, dvs. den första ”föregående” resultatuppsättningen i en sekvens är det resultat som ankarmedlemmen returnerade.
- CTE-invokation – Slutanvisning som åberopar rekursion
- Failsafe-mekanism – MAXRECURSION-alternativet förhindrar databassystemet från oändliga slingor. Detta är ett valfritt element.
Terminationskontroll
CTE:s rekursiva medlem har ingen uttrycklig rekursionsavslutningskontroll.
I många programmeringsspråk kan vi utforma en metod som anropar sig själv – en rekursiv metod. Varje rekursiv metod måste avslutas när vissa villkor är uppfyllda. Detta är explicit rekursionsavslutning. Efter denna punkt börjar metoden returnera värden. Utan termineringspunkt kan rekursion sluta med att kalla sig själv ”i all oändlighet”.
CTE:s rekursiva medlems termineringskontroll är implicit , vilket innebär att rekursionen slutar när inga rader returneras från den föregående CTE-utförandet.
Här är ett klassiskt exempel på en rekursion i imperativ programmering. Koden nedan beräknar faktorn av ett heltal med hjälp av ett rekursivt funktions(metod)anrop.
Komplett kod för konsolprogrammet finns här.
MAXRECURSION
Som nämnts ovan kan rekursiva CTE:er liksom alla rekursiva operationer orsaka oändliga slingor om de inte utformas på rätt sätt. Denna situation kan ha en negativ inverkan på databasens prestanda. Sql Server-motorn har en felsäker mekanism som inte tillåter oändliga utföranden.
Som standard är antalet gånger som rekursiv medlem kan åberopas begränsat till 100 (detta räknar inte den enstaka ankarutförandet). Koden kommer att misslyckas vid den 101:a exekveringen av den rekursiva medlemmen.
Msg 530, Level 16, State 1, Line xxx
Uttalandet avslutades. Den maximala rekursionen 100 har uttömts innan uttalandet avslutades.
Antalet rekursioner styrs av MAXRECURSION n-frågealternativet. Alternativet kan åsidosätta standardantalet av maximalt tillåtna rekursioner. Parametern (n) representerar rekursionsnivån. 0<=n <=32767
Viktig anmärkning:: MAXRECURSION 0 – inaktiverar rekursionsgränsen!
Figur 1 visar ett exempel på en rekursiv CTE med dess element

Figur 1, rekursiva CTE-element
Deklarativ rekursion är något helt annat än traditionell, imperativ rekursion. Förutom den annorlunda kodstrukturen kan vi observera skillnaden mellan den explicita och den implicita termineringskontrollen. I exemplet CalculateFactorial definieras den explicita termineringspunkten tydligt av villkoret: if (number == 0) then return 1.
I fallet med rekursiv CTE ovan definieras termineringspunkten implicit av INNER JOIN-operationen, närmare bestämt av resultatet av det logiska uttrycket i dess ON-klausul: ON e.MgrId = c.EmpId. Resultatet av tabelloperationen styr antalet rekursioner. Detta kommer att bli tydligare i följande avsnitt.
Använd rekursiv CTE för att lösa hierarkin för anställda
Det finns många scenarier när vi kan använda rekursiva CTE:er, t.ex. för att separera element osv. Det vanligaste scenariot som jag har stött på under många år av sekvensering har varit att använda rekursiva CTE för att lösa olika hierarkiska problem.
Trädhierarkin för anställda är ett klassiskt exempel på ett hierarkiskt problem som kan lösas med hjälp av rekursiva CTE:er.
Exempel
Säg att vi har en organisation med 12 anställda. Följande affärsregler gäller;
- En anställd måste ha ett unikt id, EmpId
- förstärkt av: En anställd kan hanteras av 0 eller 1 chef.
- Detta gäller enligt följande: Primärnyckelbegränsning på kolumnen EmpId
- En anställd kan hanteras av 0 eller 1 chef.
- Detta gäller enligt följande: En anställd har en specifik identitet, EmpId: PK på EmpId, FK på MgrId och kolumnen MgrId som kan vara ogiltig
- En chef kan hantera en eller flera anställda.
- förstärkt av: PK på EmpId, FK på MgrId och kolumn MgrId som kan vara ogiltig
- En chef kan hantera en eller flera anställda: Foreign Key constraint(self referenced) on MgrId column
- förstärkt av: En anställd kan hanteras av 0 eller 1 chef.
- En chef kan inte hantera sig själv.
- förstärkt av: CHECK-begränsning på kolumnen MgrId
Trädhierarkin implementeras i en tabell som heter dbo.Employees. Skripten finns här.

Figur 2, tabellen Employees
Vi presenterar hur rekursiva CTE fungerar genom att besvara frågan:
Från hierarkiträdet i figur 2 kan vi tydligt se att Manager (EmpId = 3) direkt leder anställda; EmpId=7, EmpId=8 och EmpId=9 och indirekt leder; EmpId=10, EmpId=11 och EmpId=12.
Figur 3 visar hierarkin för EmpId=3 och det förväntade resultatet. Koden finns här.

Figur 3, EmpId=3 direkt och indirekt underställda
Hur fick vi då fram slutresultatet.
Den rekursiva delen i den aktuella iterationen refererar alltid till sitt tidigare resultat från föregående iteration. Resultatet är ett tabelluttryck (eller en virtuell tabell) som heter cte1 (tabellen på höger sida av INNER JOIN). Som vi kan se innehåller cte1 även ankardelen. I den allra första körningen(den första iterationen) kan den rekursiva delen inte referera till sitt tidigare resultat eftersom det inte fanns någon tidigare iteration. Det är därför som i den första iterationen endast ankardelen exekveras och endast en gång under hela processen. Resultatmängden för ankarfrågan ger den rekursiva delen dess tidigare resultat i den andra iterationen. Ankaret fungerar som ett svänghjul om man så vill 🙂
Det slutliga resultatet byggs upp genom iterationer, dvs. resultat från ankaret + resultat från iteration 1 + resultat från iteration 2 …
Den logiska exekveringssekvensen
Testfrågan exekveras genom att följa nedanstående logiska sekvens:
- SELECT-anvisningen utanför cte1-uttrycket åberopar rekursionen. Ankarfrågan exekveras och returnerar en virtuell tabell som heter cte1. Den rekursiva delen returnerar en tom tabell eftersom den inte har något tidigare resultat. Kom ihåg att uttrycken i set based approach utvärderas alla på en gång.
 Figur 4, cte1-värdet efter 1:a iterationen
Figur 4, cte1-värdet efter 1:a iterationen - Den andra iterationen börjar. detta är den första rekursionen. Ankardelen spelade sin roll i den första iterationen och returnerar från och med nu endast tomma mängder. Den rekursiva delen kan dock nu referera till sitt tidigare resultat (cte1-värdet efter den första iterationen) i INNER JOIN-operatören. Tabelloperationen ger resultatet av den andra iterationen enligt figuren nedan.
 FIgure 5, cte1 value after 2nd iteration
FIgure 5, cte1 value after 2nd iteration - Den andra iterationen ger en icke-tom mängd, så processen fortsätter med den tredje iterationen – den andra rekursionen. Det rekursiva elementet hänvisar nu till cte1-resultatet från den andra iterationen.
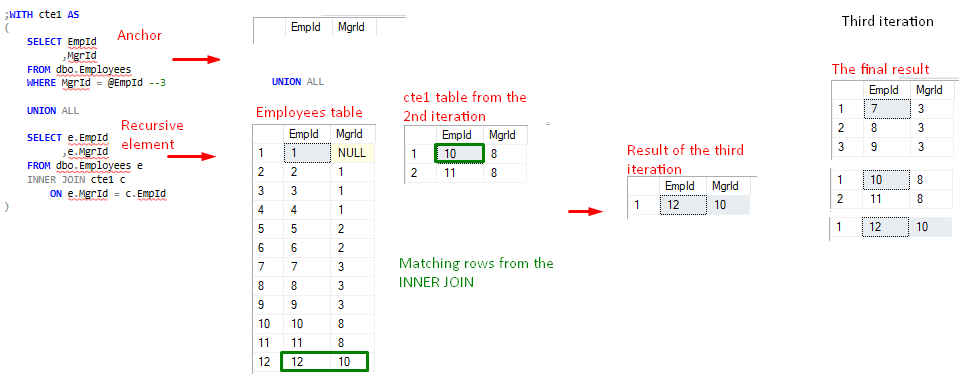
FIgure 6, cte1-värde efter den tredje iterationen - En intressant sak händer i den fjärde iterationen – det tredje rekursionsförsöket. Enligt det tidigare mönstret använder det rekursiva elementet cte1-resultatet från föregående iteration. Den här gången finns det dock inga rader som returneras som ett resultat av INNER JOIN-operationen, och det rekursiva elementet returnerar en tom mängd. Detta är den implicita avbrottspunkt som nämndes tidigare. I det här fallet dikterar INNER JOIN:s logiska uttrycksutvärdering antalet rekursioner.
Då det sista cte1-resultatet är en tom resultatuppsättning ”avbryts” den fjärde iterationen (eller den tredje rekursionen) och processen avslutas framgångsrikt.
Figur 7, Den sista iterationen
Den logiska annulleringen av den tredje rekursionen (den sista rekursionen som gav en tom resultatuppsättning räknas inte) kommer att bli tydligare i det följande avsnittet om analys av rekursiva CTE-utförandeplaner.Vi kan lägga till alternativet OPTION(MAXRECURSION 2) i slutet av frågan, vilket begränsar antalet tillåtna rekursioner till 2. Frågan kommer att ge det korrekta resultatet, vilket visar att endast två rekursioner krävs för den här uppgiften.Obs: Från det fysiska exekveringsperspektivet skickas resultatmängden successivt (i takt med att rader bubblar upp) till nätverksbuffertarna och tillbaka till klientprogrammet.
Slutligt är svaret på frågan ovan :
Det finns sex anställda som direkt eller indirekt rapporterar till Emp = 3. Tre anställda, EmpId= 7, EmpId=8 och EmpId=9 är direkt underordnade och EmpId=10, EmpId=11 och EmpId=12 är indirekt underordnade.
Med kännedom om mekaniken för rekursiv CTE kan vi enkelt lösa följande problem.
- sök alla anställda som är hierarkiskt över EmpId = 10 (kod här)
- sök EmpId=8 ’s direkta och andra nivåns underordnade (kod här)
I det andra exemplet kontrollerar vi hierarkins djup genom att begränsa antalet rekursioner.
Anchor-elementet ger oss den första nivån i hierarkin, i det här fallet de direkt underordnade. Varje rekursion flyttar sedan en hierarkinivå nedåt från den första nivån. I exemplet är utgångspunkten EmpId=8 och hans/hennes direkt underordnade. Den första rekursionen flyttar ytterligare en nivå nedåt i hierarkin där EmpId=8:s underordnade på andra nivån ”bor”.
Cirkelformigt referensproblem
En av de intressanta sakerna med hierarkier är att medlemmarna i en hierarki kan bilda en sluten slinga där det sista elementet i hierarkin refererar till det första elementet. Den slutna slingan är också känd som cirkulär referens.
I sådana fall kommer den implicita slutpunkten, som INNER JOIN-operationen som förklarades tidigare, helt enkelt inte att fungera eftersom den alltid kommer att returnera en resultatuppsättning som inte är tom för att nästa rekursion ska kunna fortsätta. Rekursionsdelen kommer att fortsätta rulla tills den träffar Sql Servers felsäkra, MAXRECURSION-frågealternativet.
För att demonstrera cirkulära referenssituationer med hjälp av den tidigare inställda testmiljön måste vi
- Föra bort primär- och främmande nyckelbegränsningar från dbo.Employees-tabellen för att möjliggöra slutna slingor.
- Skapa en cirkulär referens (EmpId=10 kommer att hantera sin indirekta chef , EmpId = 3)
- Utöka den testfråga som användes i de tidigare exemplen för att kunna analysera hierarkin hos elementen i den slutna slingan.
Den utökade testfrågan finns här.
För att fortsätta med exemplet med den cirkulära referensen, ska vi se hur den utökade testfrågan fungerar. Kommentera ut WHERE-klausulens predikat (de två sista raderna) och kör frågan mot den ursprungliga tabellen dbo.Employee
 Figur 8, Detektering av cirkulära slingor i hierarkier
Figur 8, Detektering av cirkulära slingor i hierarkier
Resultatet av den utökade frågan är exakt detsamma som det resultat som presenterades i det föregående experimentet i Figur 3. Utmatningen utökas med följande kolumner
- pth – representerar grafiskt den aktuella hierarkin. Inledningsvis, inom ankardelen, läggs helt enkelt den första underordnade till MgrId=3, den chef vi utgår från. Nu tar varje rekursiv del det föregående pth-värdet och lägger till nästa underordnade till det.
- recLvl – representerar den aktuella rekursionsnivån. Ankarutförande räknas som recLvl=0
- isCircRef – upptäcker förekomsten av en cirkulär referens i den aktuella hierarkin (raden). Som en del av det rekursiva elementet söker den efter förekomsten av en EmpId som tidigare ingick i pth-strängen.
i.Om den tidigare pth-strängen ser ut som 3->8->10 och den aktuella rekursionen lägger till ” ->3 ”, (3->8 >10 -> 3) vilket innebär att EmpId=3 inte bara är indirekt överordnad EmpId=10, utan också är EmpId=10:s underordnade – jag är chefen eller din chef, och du är min chef – en situation av det här slaget 😐
Låts oss nu göra nödvändiga ändringar i dbo.Employees för att se den utökade testfrågan i aktion.
För att tillåta cirkulära referenser tar vi bort PK- och FK-begränsningar och lägger till en ”bad boy circular ref” till tabellen.
Kör den utökade testfrågan och analysera resultaten (glöm inte att avkommettera den tidigare kommenterade WHERE-klausulen i slutet av skriptet)
Skriptet kommer att utföra 100 rekursioner innan det blir avbrutet av standardvärdet MAXRECURSION. Slutresultatet kommer att begränsas till två rekursioner .. AND cte1.recLvl <= 2; vilket krävs för att lösa EmpId=3:s hierarki.
Figur 9 visar en hierarki med en sluten slinga, maximalt tillåtet antal rekursioner som är uttömda felet och utdata som visar den slutna slingan.
Figur 10, Cirkulär referens upptäckt
För några anteckningar om skriptet för cirkulär referens:
Skriptet är bara en idé om hur man hittar slutna slingor i hierarkier. Det rapporterar endast den första förekomsten av en cirkulär referens – försök att ta bort WHERE-klausulen och observera resultatet.
Jag anser att skriptet (eller liknande versioner av skriptet) kan användas i produktionsmiljö för felsökning eller för att förhindra att cirkulära referenser skapas i en befintlig hierarki. Det måste dock säkras med lämplig MAXRECURSION n, där n är det förväntade djupet på hierarkin.
Det här skriptet är icke-relationellt och bygger på en traversalteknik. Det är alltid bäst att använda deklarativa begränsningar (PK, FK, CHECK…) för att förhindra slutna slingor i data.
Analys av utförandeplan
Det här segmentet förklarar hur Sql Servers Query Optimizer (QO) implementerar en rekursiv CTE. Det finns ett vanligt mönster som QO använder när han konstruerar exekveringsplanen. Kör den ursprungliga testfrågan och inkludera den faktiska exekveringsplanen
Likt testfrågan har exekveringsplanen två grenar: ankargrenen och den rekursiva grenen. Operatorn Concatenation, som implementerar UNION ALL-operatorn, kopplar samman resultaten från de två delarna som bildar frågeresultatet.
Låt oss försöka förena den logiska exekveringssekvensen som nämndes tidigare och den faktiska implementeringen av processen.
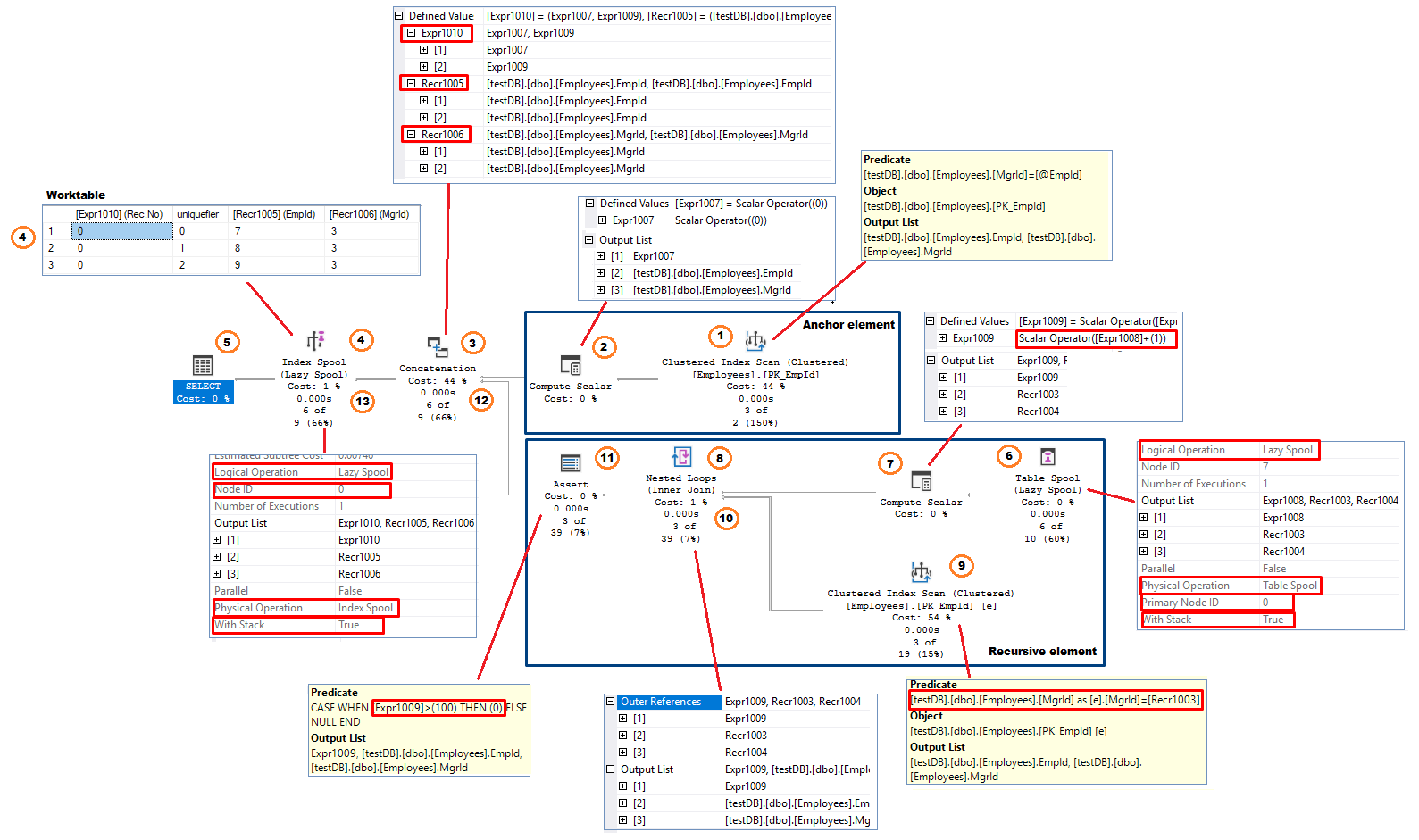
Figur 11, rekursiv CTE-utförandeplan
Följs dataflödet (från höger till vänster) ser processen ut så här:
Anchorelement (utförs endast en gång)
- Operatör för klustrad indexavläsning – systemet utför indexavläsning. I det här exemplet tillämpas uttrycket MgrId = @EmpId som ett kvarstående predikat. Valda rader (kolumnerna EmpId och MgrId) skickas (rad för rad) tillbaka till föregående operatör.
- Compute Scalar Operatören lägger till en kolumn till resultatet. I det här exemplet är namnet på den tillagda kolumnen . Detta representerar antalet rekurrenser. Kolumnen har initialvärdet 0; =0
- Samkörning – kombinerar indata från de två grenarna. I den första iterationen tar operatören emot rader endast från ankargrenen. Den ändrar också namnen på utdatakolumnerna. I det här exemplet är de nya kolumnnamnen:
- = eller * * * innehåller antalet rekursioner som tilldelats i den rekursiva grenen. Den har inget värde i den första iterationen.
- = EmpId(från ankardelen) eller EmpId(från den rekursiva delen)
- = MgrId(från ankardelen) eller MgrId (från den rekursiva delen)
- Index Spool (Lazy Spool) Med den här operatören lagras resultatet som mottagits från operatören Concatenation i en arbetsbord. Egenskapen ”Logical Operation” är inställd på ”Lazy Spool”. Detta innebär att operatören returnerar sina inmatade rader omedelbart och inte ackumulerar alla rader förrän den får den slutliga resultatuppsättningen (Eager Spool) . Arbetstabellen är strukturerad som ett klusterindex med nyckelkolumnen – rekursionsnumret. Eftersom indexnyckeln inte är unik lägger systemet till en intern 4-bytes unikifierare till indexnyckeln för att se till att alla rader i indexet är unikt identifierbara ur ett fysiskt genomförandeperspektiv. Operatören har också egenskapen ”With Stack” inställd på ”True”, vilket gör den här versionen av spooloperatören till en Stack Spool En Stack Spool-operatör har alltid två komponenter – en Index Spool som bygger indexstrukturen och en Table Spool som fungerar som en konsument av de rader som lagras i den arbetstabell som byggdes av Index Spool.
I detta skede returnerar Index Spool-operatören rader till SELECT-operatören och lagrar samma rader i arbetstabellen. - SELECT-operatören returnerar EmpId och MgrId ( , ). Den utesluter från resultatet. Raderna skickas till nätverksbufferten allteftersom de anländer från operatörerna nedströms
Efter att ha uttömt alla rader från Index Scan-operatören byter Concatenation-operatören kontext till den rekursiva grenen. Ankargrenen kommer inte att exekveras igen under processen.
Rekursivt element
- Table Spool (Lazy Spool). Operatören har inga ingångar och fungerar, som nämns i (4), som en konsument av de rader som produceras av Index Spool och lagras i en klustrad arbetstabell. Den har egenskapen ”Primary Node” satt till 0 som pekar på Index Spool Node Id. Detta visar att de två operatörerna är beroende av varandra. Operatören
- tar bort rader som den läste i föregående rekursion. Detta är den första rekursionen och det finns inga tidigare lästa rader som ska tas bort. Arbetstabellen innehåller tre rader (figur 4).
- Läs rader som är sorterade efter indexnyckeln + uniquifier i fallande ordning. I det här exemplet är den första lästa raden EmpId=9, MgrId=3.
Slutligt byter operatören namn på utdatakolumnernas namn. =, = och blir .
ANMÄRKNING: Operatören table spool kan observeras som cte1-uttrycket på höger sida av INNER JOIN (figur 4) - Compute Scalar Operatören lägger till 1 till det aktuella antalet rekursioner som tidigare lagrats i kolumnen .Resultatet lagras i en ny kolumn, . = + 1 = 0 + 1 = 1 = 1. Operatören matar ut tre kolumner, de två från Table Spool ( och ) och
- Operatören Nested Loop(I) tar emot rader från sin yttre ingång, som är Compute Scalar från föregående steg, och använder sedan – representerar EmpId från Table Spool-operatorn, som ett kvarstående predikat i Index Scan-operatören som är placerad i loopens inre ingång. Den inre ingången körs en gång för varje rad från den yttre ingången.
- Operatören Index Scan returnerar alla kvalificerade rader från tabellen dbo.Employees (två kolumner; EmpId och MgrId) till operatören för den inbäddade slingan.
- Inbäddad slinga(II): Operatören kombinerar från den yttre ingången och EmpId och MgrId från den inre ingången och skickar de tre kolumnraderna till nästa operatör.
- Operatören Assert används för att kontrollera villkor som kräver att frågan avbryts med ett felmeddelande. När det gäller rekursiva CTE:er implementerar assert-operatören alternativet ”MAXRECURSION n”. Den kontrollerar om den rekursiva delen har nått det tillåtna (n) antalet rekursioner eller inte. Om det aktuella antalet rekursioner (se steg 7) är större än (n) returnerar operatören 0 och orsakar ett körtidsfel. I det här exemplet använder Sql Server standardvärdet MAXRECURSION på 100. Uttrycket ser ut som följer: CASE WHEN WHEN > 100 THEN 0 ELSE NULL Om vi bestämmer oss för att utesluta felsäkerheten genom att lägga till MAXRECURSION 0, kommer assert-operatorn inte att inkluderas i planen.
- Samkörning kombinerar indata från de två grenarna. Den här gången tar den endast emot indata från den rekursiva delen och matar ut kolumner/rader enligt steg 3.
- Index Spool (Lazy Spool) lägger till utdata från concatenation-operatorn till arbetstabellen och skickar den sedan vidare till SELECT-operatören. Vid det här laget innehåller arbetstabellen totalt 4 rader: tre rader från ankarutförandet och en från den första rekursionen. Enligt arbetstabellens klustrade indexstruktur lagras den nya raden i slutet av arbetstabellen
-
Processen fortsätter nu från steg 6. Operatören table spool tar bort tidigare lästa rader (de tre första raderna) från arbetstabellen och läser den sista infogade raden, den fjärde raden.
Slutsats
CTE(Common table expressions) är en typ av tabelluttryck som finns tillgängliga i Sql Server. En CTE är ett oberoende tabelluttryck som kan namnges och refereras en eller flera gånger i huvudfrågan.
En av de viktigaste användningsområdena för CTE är att skriva rekursiva frågor. Rekursiva CTE:er följer alltid samma struktur – förankringsfråga, UNION ALL-operator med flera uppsättningar, rekursiv medlem och det uttalande som åberopar rekursion. Rekursiv CTE är deklarativ rekursion och har därför andra egenskaper än sin imperativa motsvarighet, t.ex. är deklarativ rekursions avslutningskontroll av implicit natur – rekursionsprocessen slutar när det inte finns några rader som returneras i den föregående cte.
Lämna ett svar