Hur man använder Tesseract på Windows
On januari 14, 2022 by admin
Tesseract är en programvara för optisk teckenigenkänning som utvecklats av Google. Det är ett OCR-verktyg med öppen källkod. Det finns många versioner av Tesseract men vi kommer att använda version 4.0.
I version 4 har Tesseract implementerat en LSTM-baserad igenkänningsmotor (Long Short Term Memory). LSTM är ett slags Recurrent Neural Network (RNN). Den LSTM-baserade igenkänningen fungerar mycket effektivare än de gamla (CNN-baserade) igenkänningsprocesserna.
Tack vare tesseract kommer vi att kunna spara innehållet i våra bilder som textfiler.
Installation
Den isntallation är beror på ditt operativsystem. Nu ska vi gå igenom fönstren. Först laddar vi ner och installerar tesseract via den här länken. (Den laddar ner en exe-fil.) Vi installerar exe-filen enkelt.
Därefter bör vi lägga till en PATH till windows systemvariabler. Det är faktiskt ett enkelt steg. Först letar vi upp och kopierar rotmappen för tesseract-installationen. Det ska vara så här :
C:\Program Files\Tesseract-OCR
Och sedan i sökfältet i windows Avancerade systeminställningar
Avancerade systeminställningar > Avancerat > Miljövariabler > PATH > Nytt
Vi klistrar in den källsökväg som kopierats och vi sparar denna konfigurationer. Efter detta steg måste datorn startas om för att konfigurationer ska kunna tillämpas.
Tesseract-installationen slutförd. Du kan bekräfta installationen från kommandoraden. När vi kör kommandot tesseract på kommandoraden bör det ge oss information om programmet.
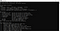
Nu kan vi gå vidare till pythondelen. För att använda tesseract på python bör vi ladda ner biblioteket pytesseract. Detta bibliotek kan laddas ner via pip till den miljö du använder.
pip install pytesseract
Nu är tesseract redo att användas!!
Kodning
Det är riktigt enkelt att använda tesseract. Det svåra är att optimera inställningarna.
Om du vill göra en lyckad oCR måste du vara försiktig i bildbehandlingssteget och ocr-inställningarna.
Låt oss tillämpa OCR på kvittot.

Importera biblioteken
import pytesseract
from PIL import Image
import cv2
import numpy as np
Inställning av bildens DPI-värde
Punkter per tum (DPI, eller dpi) är ett mått på video- eller bildskannerns punkttäthet. DPI-värdet är en viktig sak för att köra OCR. För om DPI-värdet är lägre än 300 kan det minska framgången för OCR.
file_path= 'receipt.jpg'
im = Image.open(file_path)
im.save('ocr.png', dpi=(300, 300))
Använda några tekniker för att göra bilden renare
Först skalar vi vår bild med x2. Om tecknen är små måste vi skala bilden för att kunna känna igen dem. Därefter tillämpar vi en enkel tröskelteknik. Det är ett binärt tröskelvärde. Först bör man prova med 127-värdet, därefter kan man prova olika variabler. Tröskelvärdet ändrar pixeln med svart om pixelvärdet överstiger tröskelvärdet. Om vi gör bilden gråskalig kommer vi att få en svartvit bild.
Det finns olika tröskeltekniker. Du kan kolla källwebbplatsen med den här länken.

Körning av Tesseract
Nu kan vi köra Tesseract. Den har en image_to_string()-funktion. Den ger oss en sträng som utdata.
text = pytesseract.image_to_string(treshold)
Spara utdata
Vi kan spara utdata med följande kod.
with open("Output.txt", "w",5 ,"utf-8") as text_file:
text_file.write(text)
Utdatan av OCR:
Resultatet är mycket lyckat. Om större framgång önskas kan olika operationer tillämpas på bilden.
Lämna ett svar