Cum se utilizează Tesseract pe Windows
On ianuarie 14, 2022 by admin
Tesseract este un software de recunoaștere optică a caracterelor, dezvoltat de Google. Este un instrument OCR cu sursă deschisă. Există mai multe versiuni ale lui Tesseract, dar noi vom folosi versiunea 4.0.
În versiunea 4, Tesseract a implementat un motor de recunoaștere bazat pe memorie pe termen scurt (LSTM). LSTM este un fel de rețea neuronală recurentă (RNN). Recunoașterea bazată pe LSTM funcționează mult mai eficient decât vechile procese de recunoaștere (bazate pe CNN).
Grație lui Tesseract, vom putea salva conținutul imaginilor noastre ca fișiere text.
Instalare
Instalarea depinde de sistemul dumneavoastră de operare. Acum vom trece prin ferestre. În primul rând, să descărcăm și să instalăm tesseract thorugh acest link. (Se descarcă un fișier exe.) Instalăm fișierul exe cu ușurință.
După aceea ar trebui să adăugăm un PATH la variabilele de sistem Windows. De fapt este un pas ușor. În primul rând găsim și copiem folderul rădăcină al instalației tesseract. Acesta va trebui să fie așa :
C:\Program Files\Tesseract-OCR
Și apoi în bara de căutare din Windows Advanced System Settings
Advanced system settings > Advanced > Environment variables > PATH > New
Împrăștiem calea sursă pe care am copiat-o și salvăm aceste configurații. După acest pas, calculatorul trebuie repornit pentru a aplica configurațiile.
Instalarea tesseract s-a încheiat. Puteți confirma instalarea din linia de comandă. Când executăm comanda tesseract în linia de comandă, aceasta ar trebui să ne ofere informații despre program.
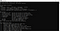
Acum putem trece la partea de python. Pentru a utiliza tesseract pe python, ar trebui să descărcăm biblioteca pytesseract. Această bibliotecă poate fi descărcată prin pip în mediul pe care îl folosiți.
pip install pytesseract
Acum tesseract este gata de utilizare!!!
Codare
Este foarte simplu să folosești tesseract. Partea dificilă este optimizarea setărilor.
Pentru că dacă doriți să faceți un OCR de succes, trebuie să fiți atenți la etapa de procesare a imaginii și la setările OCR.
Să aplicăm OCR la chitanță.

Importul bibliotecilor
import pytesseract
from PIL import Image
import cv2
import numpy as np
Setarea valorii DPI a imaginii
Punctele pe inch (DPI, sau dpi) este o măsură a densității de puncte a scanerului video sau de imagine. Valoarea DPI este un lucru important pentru a rula OCR. Pentru că dacă valoarea DPI este mai mică de 300, se poate reduce succesul OCR.
file_path= 'receipt.jpg'
im = Image.open(file_path)
im.save('ocr.png', dpi=(300, 300))
Aplicarea unor tehnici pentru a face imaginea mai curată
În primul rând, redimensionăm imaginea noastră cu x2. Dacă caracterele sunt mici, atunci trebuie să redimensionăm imaginea pentru a o recunoaște. După aceea, aplicăm o tehnică simplă de prag. Este vorba de Binary Threshold (prag binar). Mai întâi ar trebui să încercați cu o valoare de 127, după care se pot încerca diferite variabile. Pragul schimbă pixelul cu negru dacă valoarea pixelului depășește valoarea de prag. Dacă facem o imagine în tonuri de gri, vom obține o imagine alb-negru.
Există diferite tehnici de prag. Puteți verifica site-ul sursă cu acest link.

Executarea Tesseract
Acum putem executa Tesseract. Acesta are o funcție image_to_string(). Aceasta ne oferă un șir de caractere ca ieșire.
text = pytesseract.image_to_string(treshold)
Salvarea ieșirii
Potem salva ieșirea cu următorul cod.
with open("Output.txt", "w",5 ,"utf-8") as text_file:
text_file.write(text)
Ieșirea OCR-ului este următoarea:
Rezultatul este foarte reușit. Dacă se dorește un succes mai mare, se pot aplica diferite operații asupra imaginii.
Lasă un răspuns