Jak używać programu Tesseract w systemie Windows
On 14 stycznia, 2022 by admin
Tesseract to oprogramowanie do optycznego rozpoznawania znaków, które zostało opracowane przez firmę Google. Jest to narzędzie OCR typu open source. Istnieje wiele wersji tesseracta, ale my użyjemy wersji 4.0.
W wersji 4, Tesseract zaimplementował silnik rozpoznawania oparty na długiej pamięci krótkotrwałej (LSTM). LSTM jest rodzajem rekurencyjnej sieci neuronowej (RNN). Rozpoznawanie oparte na LSTM działa dużo bardziej efektywnie niż stare (oparte na CNN) procesy rozpoznawania.
Dzięki tesseract, będziemy mogli zapisać zawartość naszych obrazów jako pliki tekstowe.
Instalacja
Instalacja zależy od systemu operacyjnego. Teraz przejdziemy przez okna. Po pierwsze, pobierzmy i zainstalujmy tesseract przez ten link. (To pobiera plik exe.) Ustawiamy plik exe w prosty sposób.
Po tym powinniśmy dodać PATH do zmiennych systemowych Windows. Właściwie jest to prosty krok. Po pierwsze znajdujemy i kopiujemy główny folder instalacji tesseract. Powinien on wyglądać tak :
C:\Program Files\Tesseract-OCR
A następnie w pasku wyszukiwania Windows Zaawansowane ustawienia systemowe
Zaawansowane ustawienia systemowe > Zaawansowane >Zmienne środowiskowe > PATH > Nowy
Wklejamy ścieżkę źródłową, którą skopiowaliśmy i zapisujemy tę konfigurację. Po tym kroku komputer musi być zrestartowany aby zastosować konfiguracje.
Instalacja tesseract zakończona. Można potwierdzić instalację z linii poleceń. Gdy uruchomimy komendę tesseract w wierszu poleceń, powinna ona podać nam informacje o programie.
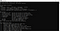
Teraz możemy przejść do części pythonowej. Aby używać tesseract w pythonie, powinniśmy pobrać bibliotekę pytesseract. Ta biblioteka może być pobrana przez pip do środowiska, którego używasz.
pip install pytesseract
Teraz tesseract jest gotowy do użycia!!
Kodowanie
Używanie tesseract jest naprawdę proste. Najtrudniejszą częścią jest optymalizacja ustawień.
Bo jeśli chcesz zrobić udany ocr, musisz być ostrożny w kroku przetwarzania obrazu i ustawieniach ocr.
Zastosujmy OCR do paragonu.

Importowanie bibliotek
import pytesseract
from PIL import Image
import cv2
import numpy as np
Ustawianie wartości DPI obrazu
Dots per inch (DPI, lub dpi) jest miarą gęstości punktów skanera wideo lub obrazu. Wartość DPI jest ważną rzeczą do uruchomienia OCR. Ponieważ jeśli wartość DPI jest niższa niż 300, może zmniejszyć sukces OCR.
file_path= 'receipt.jpg'
im = Image.open(file_path)
im.save('ocr.png', dpi=(300, 300))
Applying Some Techniques to Make Image Cleaner
Po pierwsze skalujemy nasz obraz z x2. Jeśli znaki są małe to musimy przeskalować obraz aby je rozpoznać. Po tym stosujemy prostą technikę progowania. Jest to Próg Binarny. Najpierw powinieneś spróbować z wartością 127 po tym różne zmienne mogą być wypróbowane. Próg zmienia piksel na czarny, jeśli wartość piksela przekracza wartość progową. Jeśli zrobimy obraz w skali szarości, to da nam czarno-biały obraz.
Istnieją różne techniki progowe. Możesz sprawdzić stronę źródłową z tym linkiem.

Running Tesseract
Teraz możemy uruchomić tesseract. Posiada on funkcję image_to_string(). Daje nam ona ciąg znaków jako wyjście.
text = pytesseract.image_to_string(treshold)
Zapisywanie wyjścia
Możemy zapisać wyjście za pomocą następującego kodu.
with open("Output.txt", "w",5 ,"utf-8") as text_file:
text_file.write(text)
Wyjście OCR jest następujące:
Wynik jest bardzo udany. Jeśli pożądany jest większy sukces, można zastosować różne operacje na obrazie.
Dodaj komentarz