Jak działa sieć
On 15 października, 2021 by adminInternet jest wszędzie!
Używamy go bardziej niż kiedykolwiek wcześniej – również w wielu miejscach, w których możesz go nie zauważyć. Ponieważ „sieć” to coś więcej niż tylko strony internetowe, które odwiedzasz wpisując adres URL w przeglądarce.
Nieważne, czy sprawdzasz pocztę elektroniczną w telefonie komórkowym, czy wysyłasz tweeta – korzystasz z internetu (czyli „sieci”).
Jak to wszystko działa? Które technologie są zaangażowane i czego musisz się nauczyć (i w jakim stopniu), jeśli chcesz zostać programistą WWW?
W tym artykule i wideo (zobacz powyżej), nie będę się zagłębiał we wszystkie szczegóły techniczne. To ma być dobry przegląd funkcjonalności stron internetowych.

CSS – The Complete Guide
Dołącz do tego kompleksowego kursu 20h+, aby opanować CSS i nauczyć się tworzyć piękne strony internetowe.

JavaScript – Kompletny przewodnik
Naucz się JavaScript od podstaw, aby budować wysoce interaktywne i dynamiczne strony internetowe w tym praktycznym kursie!
# Jak działają strony internetowe
Zacznijmy od najbardziej oczywistego sposobu korzystania z Internetu: Odwiedzasz stronę internetową, taką jak academind.com.
W momencie, gdy wpisujesz ten adres w przeglądarce i naciskasz ENTER, dzieje się wiele różnych rzeczy:
- Adres URL zostaje rozwiązany
- Zapytanie zostaje wysłane do serwera witryny
- Odpowiedź serwera jest parsowana
- Strona zostaje wyrenderowana i wyświetlona

Właściwie, każdy pojedynczy krok mógłby być podzielony na wiele innych kroków, ale dla dobrego przeglądu tego, jak to wszystko działa, jest to coś, co możemy tutaj zignorować. Spójrzmy na wszystkie cztery kroki.
Krok 1 – URL Gets Resolved
Kod strony internetowej nie jest oczywiście przechowywany na twojej maszynie i dlatego musi być pobrany z innego komputera, gdzie jest przechowywany. Ten „inny komputer” jest nazywany „serwerem”. Ponieważ służy on jakiemuś celowi, w naszym przypadku służy on stronie internetowej.
Wprowadzasz „academind.com” (to się nazywa „domena”), ale tak naprawdę serwer, który hostuje kod źródłowy strony internetowej, jest identyfikowany poprzez adresy IP (= Internet Protocol). Przeglądarka wysyła „żądanie” (patrz krok 2) do serwera z adresem IP, który wpisałeś (pośrednio – oczywiście wpisałeś „academind.com”).
W rzeczywistości często wpisujesz również "academind.com/learn" lub cokolwiek podobnego. "academind.com" to domena, "/learn" to tak zwana ścieżka. Razem tworzą one „URL” („Uniform Resource Locator”).
W dodatku, możesz odwiedzić większość stron internetowych poprzez "www.academind.com" lub tylko "academind.com". Technicznie, "www" jest subdomeną, ale większość stron internetowych po prostu przekierowuje ruch do "www" na stronę główną.
Adres IP zazwyczaj wygląda tak: 172.56.180.5 (choć istnieje też bardziej „nowoczesna” forma zwana IPv6 – ale na razie ją zignorujmy). Możesz dowiedzieć się więcej o adresach IP w Wikipedii.
Jak domena „academind.com” jest tłumaczona na adres IP?
W Internecie istnieje specjalny typ serwera – nie jeden, ale wiele serwerów tego typu. Tak zwany „serwer nazw” lub „serwer DNS” (gdzie DNS = „Domain Name System”).
Zadaniem tych serwerów DNS jest tłumaczenie domen na adresy IP. Możesz sobie wyobrazić te serwery jako ogromne słowniki, które przechowują tabele tłumaczeń: Domena => Adres IP.
Gdy wpisujesz „academind.com”, przeglądarka pobiera więc najpierw adres IP z takiego serwera DNS.
Na wypadek, gdybyś się zastanawiał: Przeglądarka zna adresy tych serwerów domen na pamięć, są one, że tak powiem, zaprogramowane w przeglądarce.
Gdy adres IP jest już znany, przechodzimy do kroku 2.
Krok 2 – Request Is Sent
Mając rozwiązany adres IP, przeglądarka idzie dalej i kieruje żądanie do serwera z tym adresem IP.
„Żądanie” nie jest tylko terminem. To naprawdę jest techniczna rzecz, która dzieje się za kulisami.
Przeglądarka łączy w sobie garść informacji (Jaki jest dokładny adres URL? Jaki rodzaj żądania powinien być wykonany? Czy należy dołączyć metadane) i wysyła ten pakiet danych na adres IP.
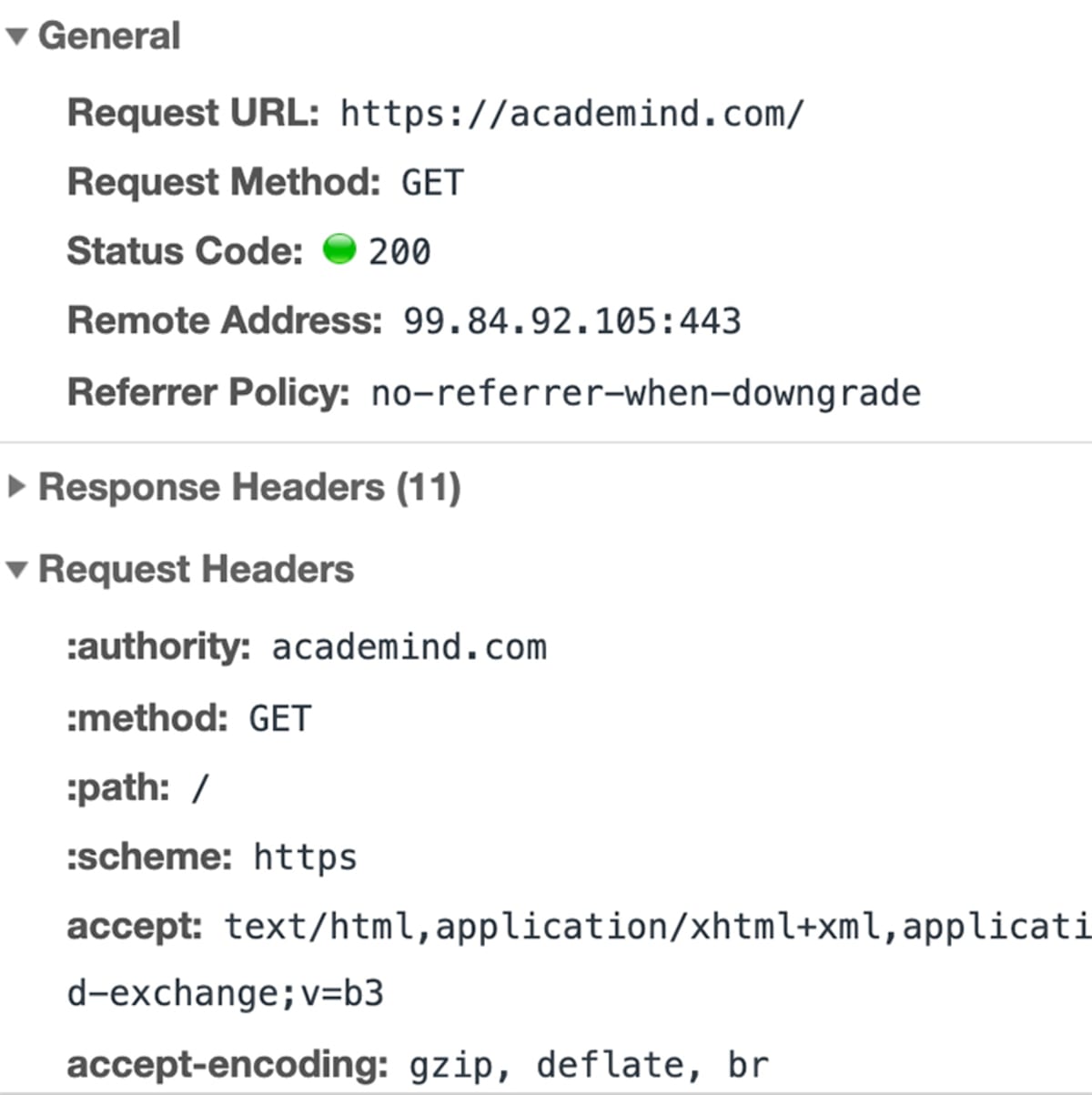
Dane są wysyłane za pośrednictwem „HyperText Transfer Protocol” (znanego jako „HTTP”) – znormalizowanego protokołu, który określa, jak ma wyglądać żądanie (i odpowiedź), jakie dane mogą być zawarte (i w jakiej formie) oraz w jaki sposób żądanie zostanie przesłane. Możesz dowiedzieć się więcej o HTTP tutaj.
Ponieważ używany jest protokół HTTP, pełny adres URL w rzeczywistości wygląda tak: http://academind.com. Przeglądarka automatycznie uzupełnia go dla ciebie.
I jest też HTTPS – jest jak HTTP ale zaszyfrowany. Większość nowoczesnych stron (w tym academind.com) używa go zamiast HTTP. Pełny adres URL staje się wtedy: https://academind.com.
Ponieważ cały proces i format jest ustandaryzowany, nie ma zgadywania, jak to żądanie musi być odczytane przez serwer.
Serwer następnie odpowiednio obsługuje żądanie i zwraca tak zwaną „odpowiedź”. Ponownie, „odpowiedź” jest rzeczą techniczną i w pewnym sensie podobną do „żądania”. Można powiedzieć, że jest to w zasadzie „żądanie” w przeciwnym kierunku.
Jak żądanie, odpowiedź może zawierać dane, metadane itp. Kiedy żądamy strony takiej jak academind.com, odpowiedź będzie zawierać kod, który jest wymagany do wyrenderowania strony na ekranie.
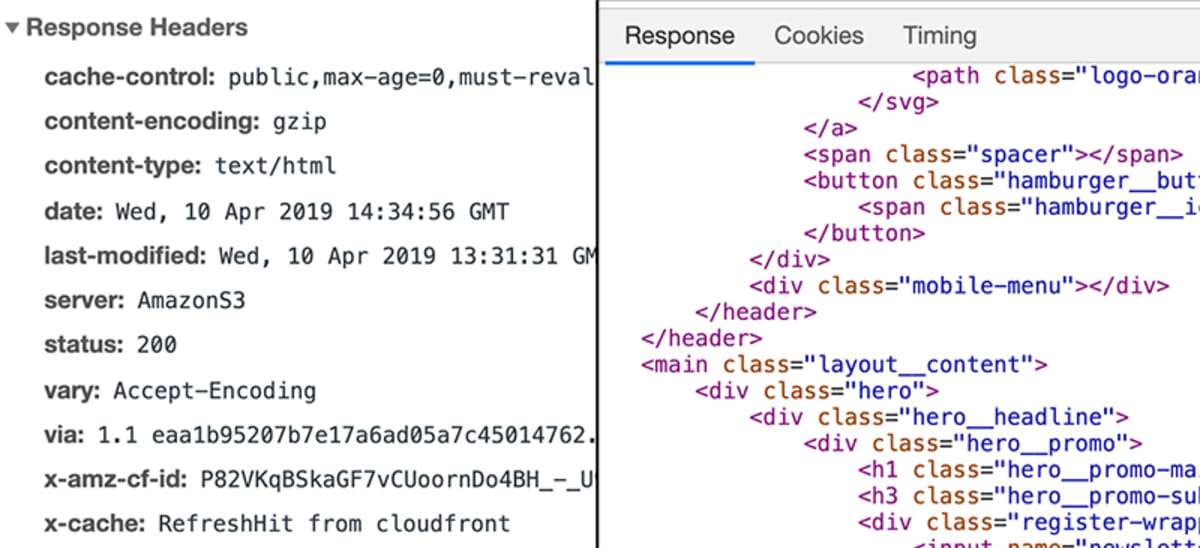
Co dzieje się na serwerze?
To jest definiowane przez twórców stron internetowych. W końcu, odpowiedź musi zostać wysłana. Ta odpowiedź nie musi zawierać „strony internetowej”. Może zawierać dowolne dane – w tym pliki lub obrazy.
Niektóre serwery są zaprogramowane do dynamicznego generowania stron internetowych na podstawie żądania (np. strona profilu, która zawiera twoje dane osobowe), inne serwery zwracają wstępnie wygenerowane strony HTML (np. strona z wiadomościami). Albo robi się jedno i drugie – dla różnych części strony. Istnieje również trzecia alternatywa: Strony internetowe, które są wstępnie wygenerowane, ale zmieniają swój wygląd i dane w przeglądarce.
Różne rodzaje stron internetowych nie są tak naprawdę przedmiotem zainteresowania tego artykułu. Jeśli chcesz dowiedzieć się więcej na ten temat, sprawdź ten artykuł + wideo.
Dla naszego prostego przypadku mamy serwer, który zwraca kod, aby wyświetlić stronę internetową. Kontynuujmy więc krok 3.
Krok 3 – Response Is Parsed
Przeglądarka otrzymuje odpowiedź wysłaną przez serwer. Samo to nie powoduje jednak wyświetlenia czegokolwiek na ekranie.
Następnym krokiem jest parsowanie odpowiedzi przez przeglądarkę. Tak samo jak serwer zrobił to z żądaniem. Ponownie, standaryzacja wymuszona przez HTTP oczywiście pomaga.
Przeglądarka sprawdza dane i metadane, które są zawarte w odpowiedzi. I na tej podstawie decyduje, co zrobić.
Mogłeś mieć przypadki, w których PDF otworzył się w przeglądarce. Stało się tak, ponieważ odpowiedź poinformowała przeglądarkę, że dane nie są stroną internetową, ale dokumentem PDF. A przeglądarka próbuje wybrać najlepszy mechanizm obsługi dla każdego typu danych, który wykryje.
Wracając do naszego scenariusza strony internetowej.
W tym przypadku odpowiedź zawierałaby określony fragment metadanych, który mówi przeglądarce, że dane odpowiedzi są typu text/html.
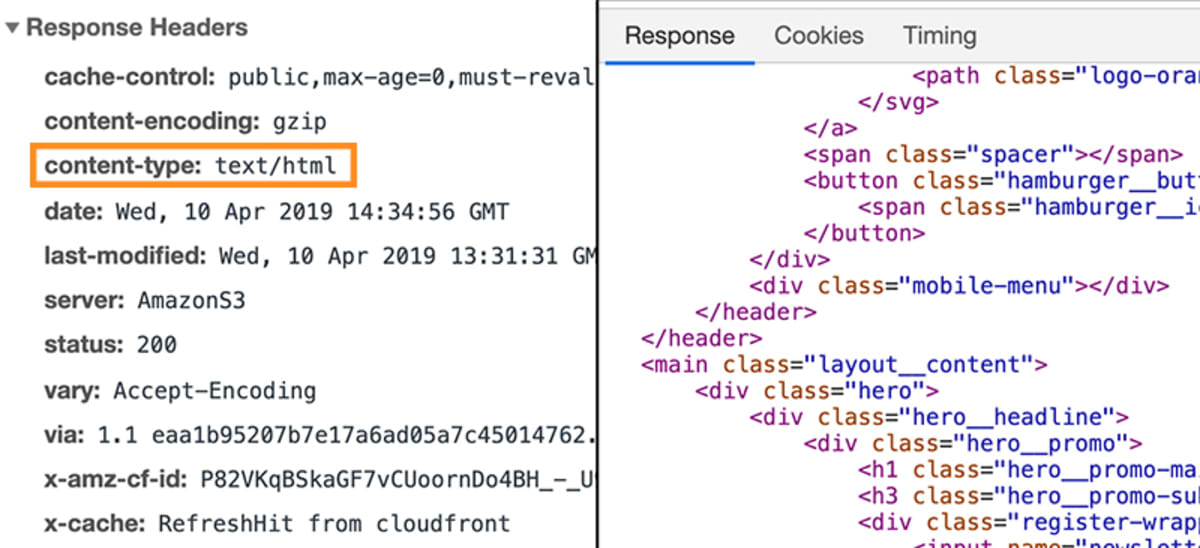
To pozwala przeglądarce na przetworzenie rzeczywistych danych, które są dołączone do odpowiedzi jako kod HTML.
HTML jest podstawowym „językiem programowania” (technicznie rzecz biorąc, nie jest to język programowania – nie można napisać w nim żadnej logiki) w sieci. HTML jest skrótem od „Hyper Text Markup Language” i opisuje strukturę strony internetowej.
Kod wygląda tak:
<h1>Breaking News!</h1><p>Websites work because browser understand HTML!</p><h1> i <p> są tak zwanymi „znacznikami HTML” i jeśli chcesz dowiedzieć się więcej o HTML, ta seria jest świetnym miejscem, aby to zrobić.
Każdy znacznik HTML ma jakieś semantyczne znaczenie, które przeglądarka rozumie, ponieważ HTML jest również ustandaryzowany. Stąd nie ma zgadywania, co oznacza znacznik <h1>.
Przeglądarka wie, jak parsować HTML i teraz po prostu przechodzi przez całe dane odpowiedzi (zwane również „ciałem odpowiedzi”), aby wyrenderować stronę internetową.
Krok 4 – Strona jest wyświetlana
Jak wspomniano, przeglądarka przechodzi przez dane HTML zwrócone przez serwer i buduje stronę internetową w oparciu o to.
Choć ważne jest, aby wiedzieć, że HTML nie zawiera żadnych instrukcji dotyczących tego, jak strona powinna wyglądać (tj. jak powinna być stylizowana). Tak naprawdę definiuje on tylko strukturę i mówi przeglądarce, która zawartość jest nagłówkiem, która obrazkiem, a która akapitem itd. Jest to szczególnie ważne dla dostępności – czytniki ekranu pobierają wszystkie użyteczne informacje ze struktury HTML.
Strona zawierająca tylko HTML wyglądałaby jednak tak:

Nie tak pięknie, prawda?
Dlatego istnieje inna ważna technologia (inny „język programowania”, który tak naprawdę nie jest językiem programowania): CSS („Cascading Style Sheets”).
CSS polega na dodawaniu stylizacji do strony internetowej. Odbywa się to za pomocą „reguł CSS”:
h1 { color: blue;}Ta reguła pokolorowałaby wszystkie znaczniki <h1> na niebiesko.
Reguły takie jak ta mogą być dodane wewnątrz kodu HTML, ale zazwyczaj są one częścią oddzielnych plików .css, które są wymagane oddzielnie.
Bez zagłębiania się w zbyt wiele szczegółów, ma to jedną ważną konsekwencję: Strona internetowa może składać się z czegoś więcej niż dane z pierwszej odpowiedzi, którą otrzymujemy.
W praktyce strony internetowe pobierają wiele dodatkowych danych (poprzez dodatkowe żądania i odpowiedzi), które są uruchamiane po tym, jak pierwsza odpowiedź dotarła.
Jak to działa?
Cóż, kod HTML pierwszej odpowiedzi zawiera po prostu instrukcje pobierania większej ilości danych poprzez nowe żądania – a przeglądarka rozumie te instrukcje:
<link rel="stylesheet" href="/page-styles.css" />
Jeszcze raz, nie będę się tutaj zagłębiał w więcej szczegółów. Jeśli chcesz dowiedzieć się więcej o CSS, nasz Kompletny Przewodnik będzie bardzo przydatny!
Wraz z CSS, przeglądarka jest w stanie wyświetlać strony internetowe w taki sposób:

W rzeczywistości zaangażowany jest jeszcze jeden język programowania (tym razem, to naprawdę jest język programowania!): JavaScript.
Nie zawsze jest to widoczne, ale cała dynamiczna zawartość, którą znajdziesz na stronie internetowej (np. zakładki, nakładki itp.) jest tak naprawdę możliwa tylko dzięki JavaScript. Pozwala on twórcom stron internetowych na zdefiniowanie kodu, który działa w przeglądarce (nie na serwerze), stąd JavaScript może być użyty do zmiany strony internetowej, podczas gdy użytkownik ją przegląda.
Jak poprzednio, jeśli chcesz dowiedzieć się więcej, sprawdź nasze zasoby JavaScript, na przykład nasz kompletny kurs.
To są cztery kroki, które są zawsze zaangażowane, kiedy wpisujesz adres strony jak academind.com i po tym widzisz zawartość strony w swojej przeglądarce.
# Server-side vs Browser-side
Z czterech kroków powyżej, dowiedziałeś się, że możemy rozróżnić dwie podstawowe „strony” kiedy mówimy o sieci: Server-side i Browser-side (lub: Client-side, ponieważ możemy również uzyskać dostęp do Internetu bez przeglądarki – patrz poniżej!).
Jeśli jesteś zainteresowany zostaniem web developerem, ważne jest, aby wiedzieć, że używasz różnych technologii i języków programowania dla tych stron.
Server-side
Potrzebujesz języków programowania server-side – tzn. języków, które nie działają w przeglądarce, ale które mogą być uruchomione na normalnym komputerze (serwer jest w końcu tylko normalnym komputerem).
Przykładami mogą być:
- Node.js
- PHP
- Python
Ważne: Z wyjątkiem PHP, możesz również używać tych języków programowania do innych celów niż tworzenie stron internetowych.
Podczas gdy Node.js jest rzeczywiście używany głównie do programowania po stronie serwera (choć technicznie nie jest do tego ograniczony), Python jest również bardzo popularny w nauce o danych i uczeniu maszynowym.
Browser-side
W przeglądarce są dokładnie trzy języki/technologie, których musisz się nauczyć. Ale podczas gdy języki po stronie serwera były alternatywami, te trzy języki po stronie przeglądarki są wszystkie obowiązkowe do poznania i zrozumienia:
- HTML (dla struktury)
- CSS (dla stylizacji)
- JavaScript (dla dynamicznej zawartości)
# „Behind the Scenes” Internet
Dotychczas omawialiśmy strony internetowe. Tzn. przypadek, w którym wpisujesz adres URL (np. „academind.com/learn”) do przeglądarki i dostajesz w zamian stronę internetową.
Ale Internet to coś więcej. Rzeczywiście, używasz go do czegoś więcej niż tylko tego każdego dnia!
Rdzeń idei żądań i odpowiedzi jest zawsze taki sam. Ale nie każda odpowiedź jest koniecznie stroną internetową. I nie każde żądanie chce strony internetowej.
Metadane, które są dołączone do żądań i odpowiedzi kontrolują, które dane są poszukiwane i zwracane. Oczywiście obie strony, które są zaangażowane (tj. klient i serwer) muszą obsługiwać żądania i wysyłane dane.
Nie możesz zażądać pliku PDF z "academind.com" na przykład. Możesz wysłać takie żądanie, ale nie otrzymasz z powrotem pliku PDF – po prostu dlatego, że nie obsługujemy tego rodzaju żądanych danych dla tego konkretnego adresu URL.
Jest jednak wiele serwerów, które specjalizują się w dostarczaniu adresów URL, które zwracają określone dane. Takie usługi są również określane jako „API” („Application Programming Interface”).
Na przykład, aplikacje mobilne wysyłają „niewidzialne” żądania HTTP do takich API (do konkretnych adresów URL, które są im znane), aby uzyskać lub przechowywać dane. Twitter pobiera na przykład kanał tweetów.
A nawet na stronach internetowych wysyłane są takie „niewidzialne” żądania. Jeśli zapiszesz się do naszego newslettera (co oczywiście powinieneś zrobić!), żadna nowa strona nie zostanie załadowana. Ponieważ dane są wymieniane za kulisami. Nawet jeśli klientem jest w tym przypadku przeglądarka, żądanie, które jest wysyłane, nie chce w zamian żadnej strony internetowej. A adres URL serwera, który go odbiera, nie oferuje żadnej strony – zamiast tego serwer wie, jak obsługiwać twój adres e-mail.
Moglibyśmy tu wejść w dużo więcej szczegółów, ale to już jest długi artykuł. Powinieneś teraz dobrze rozumieć, jak działa sieć i jakie podstawowe technologie są w nią zaangażowane.
Dodaj komentarz