W tym artykule omawiamy granicę Chebysheva dla statystycznej analizy danych. W przypadku braku jakiegokolwiek pojęcia o normalności danego zbioru danych, granica ta może być użyta do pomiaru koncentracji danych wokół średniej.
Wprowadzenie
To jest tydzień Halloween, a między sztuczkami i smakołykami, my, maniacy danych, jesteśmy chuckling nad tym uroczym memem w mediach społecznościowych.
Myślisz, że to żart? Pozwólcie, że wam powiem, że to nie jest śmieszne. To jest przerażające, zgodne z duchem Halloween!
Jeśli nie możemy założyć, że większość naszych danych (pochodzenia biznesowego, społecznego, ekonomicznego lub naukowego) jest przynajmniej w przybliżeniu „Normalna” (tzn. są one generowane przez proces gaussowski lub przez sumę wielu takich procesów), to jesteśmy skazani na zagładę!
Oto niezwykle krótka lista rzeczy, które nie będą obowiązywać,
Cała koncepcja six-sigma
Słynna reguła 68-95-99,7
Święte” pojęcie p=0,05 (pochodzi od przedziału 2 sigma) w analizie statystycznej
Wystarczająco straszne? Porozmawiajmy o tym więcej…
Wszechmocny i wszechobecny rozkład normalny
Niech ta sekcja będzie krótka i słodka.
Rozkład normalny (gaussowski) jest najbardziej znanym rozkładem prawdopodobieństwa. Oto kilka linków do artykułów opisujących jego moc i szerokie zastosowanie,
Dlaczego Data Scientists kochają Gaussian
How to Dominate the Statistics Portion of Your Data Science Interview
What’s So Important about the Normal Distribution?
Z powodu pojawienia się w różnych domenach i Centralnego Twierdzenia Granicznego (CLT), rozkład ten zajmuje centralne miejsce w nauce o danych i analityce.
Więc, w czym tkwi problem?
Jest to prawie zakorzenione w naszym podświadomym umyśle.
Powiedzmy, że jesteś poproszony o wykrycie sprawdzenia, czy nowa partia danych z jakiegoś procesu (inżynierii lub biznesu) ma sens. Przez 'sensowność’ rozumiesz, czy nowe dane należą do siebie, tzn. czy mieszczą się w 'oczekiwanym zakresie’.
Co to jest to 'oczekiwanie’? Jak określić ilościowo ten zakres?
Automatycznie, jakby kierowani przez podświadomy napęd, mierzymy średnią i odchylenie standardowe przykładowego zbioru danych i sprawdzamy, czy nowe dane mieszczą się w pewnym zakresie odchyleń standardowych.
Jeśli musimy pracować z 95% przedziałem ufności, to cieszymy się, gdy dane mieszczą się w 2 odchyleniach standardowych. Jeśli potrzebujemy ściślejszej granicy, sprawdzamy 3 lub 4 odchylenia standardowe. Obliczamy Cpk, lub postępujemy zgodnie z wytycznymi Six Sigma dla poziomu jakości ppm (parts-per-million).
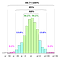
Wszystkie te obliczenia opierają się na dorozumianym założeniu, że dane populacji (NIE próbki) podążają za rozkładem gaussowskim i.Tzn. podstawowy proces, z którego wszystkie dane zostały wygenerowane (w przeszłości i obecnie), jest regulowany przez wzór po lewej stronie.
A co się stanie, jeśli dane są zgodne z rozkładem po prawej stronie?
Albo to, i… tamto?
Czy istnieje bardziej uniwersalna granica, gdy dane NIE są normalne?
Na koniec dnia nadal będziemy potrzebować matematycznie solidnej techniki do ilościowego określenia naszej granicy zaufania, nawet jeśli dane nie są normalne. Oznacza to, że nasze obliczenia mogą się nieco zmienić, ale nadal powinniśmy być w stanie powiedzieć coś takiego-
„Prawdopodobieństwo zaobserwowania nowego punktu danych w pewnej odległości od średniej jest takie i takie…”
Oczywiście, musimy szukać bardziej uniwersalnej granicy niż cenione gaussowskie granice 68-95-99.7 (odpowiadające odległości 1/2/3 odchyleń standardowych od średniej).
Na szczęście istnieje jedna taka granica zwana „Chebyshev Bound”.
Co to jest granica Czebyszewa i jak jest użyteczna?
Nierówność Czebyszewa (zwana też nierównością Bienaymégo-Czebyszewa) gwarantuje, że dla szerokiej klasy rozkładów prawdopodobieństwa nie więcej niż pewien ułamek wartości może być oddalony od średniej o więcej niż pewną odległość.
Szczególnie, nie więcej niż 1/k² wartości rozkładu może być więcej niż k odchyleń standardowych od średniej (lub równoważnie, co najmniej 1-1/k² wartości rozkładu jest w granicach k odchyleń standardowych od średniej).
Ma ona zastosowanie do praktycznie nieograniczonych typów rozkładów prawdopodobieństwa i działa na znacznie luźniejszych założeniach niż normalność.
Jak to działa?
Nawet jeśli nie wiesz nic o tajnym procesie stojącym za twoimi danymi, istnieje duża szansa, że możesz powiedzieć, co następuje,
„Jestem pewien, że 75% wszystkich danych powinno mieścić się w zakresie 2 odchyleń standardowych od średniej”,
Albo,
Jestem pewien, że 89% wszystkich danych powinno mieścić się w zakresie 3 odchyleń standardowych od średniej”.
Oto jak to wygląda dla dowolnie wyglądającego rozkładu,
Jak już się pewnie domyślasz, podstawowa mechanika analizy danych nie musi się ani trochę zmienić. Nadal będziesz zbierał próbkę danych (im większa tym lepiej), obliczał te same dwie wielkości, do których obliczania jesteś przyzwyczajony – średnią i odchylenie standardowe, a następnie zastosujesz nowe granice zamiast reguły 68-95-99.7.
Tabela wygląda następująco (tutaj k oznacza tyle odchyleń standardowych od średniej),
Demonstracja wideo jego zastosowania znajduje się tutaj,
W czym tkwi haczyk? Dlaczego ludzie nie używają tej „bardziej uniwersalnej” reguły?
To oczywiste, na czym polega haczyk, jeśli spojrzeć na tabelę lub definicję matematyczną. Reguła Chebysheva jest znacznie słabsza niż reguła Gaussa w kwestii nakładania granic na dane.
Podąża za wzorem 1/k² w porównaniu do wykładniczo malejącego wzoru dla rozkładu normalnego.
Na przykład, aby związać cokolwiek z 95% pewnością, musisz uwzględnić dane do 4,5 odchylenia standardowego vs. tylko 2 odchylenia standardowe (dla rozkładu normalnego). tylko 2 odchylenia standardowe (dla rozkładu normalnego).
Ale nadal może uratować dzień, gdy dane nie wyglądają jak rozkład normalny.
Czy jest coś lepszego?
Istnieje inna granica zwana, „Granica Chernoffa”/nierówność Hoeffdinga, która daje wykładniczo ostry rozkład ogonowy (w porównaniu do 1/k²) dla sum niezależnych zmiennych losowych.
To może być również stosowane w miejsce dystrybucji Gaussian, gdy dane nie wyglądają Normal, ale tylko wtedy, gdy mamy wysoki stopień zaufania, że podstawowy proces składa się z podprocesów, które są całkowicie niezależne od siebie.
Niestety, w wielu przypadkach społecznych i biznesowych, dane końcowe są wynikiem niezwykle skomplikowanej interakcji wielu podprocesów, które mogą mieć silne współzależności.
Podsumowanie
W tym artykule dowiedzieliśmy się o szczególnym typie granicy statystycznej, która może być zastosowana do najszerszego możliwego rozkładu danych niezależnie od założenia normalności. Jest to przydatne, gdy wiemy bardzo mało o prawdziwym źródle danych i nie możemy założyć, że są one zgodne z rozkładem gaussowskim. Granica podąża za prawem potęgowym zamiast za wykładniczą naturą (jak w przypadku Gaussiana) i dlatego jest słabsza. Ale jest to ważne narzędzie, które należy mieć w swoim repertuarze do analizy dowolnego rodzaju dystrybucji danych.

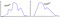



Dodaj komentarz