Wat zijn Autoencoders?
On november 11, 2021 by adminEen voorzichtige introductie tot Autoencoders en de verschillende toepassingen ervan. Ook maken deze tutorials gebruik van tf.keras,TensorFlow’s Python API op hoog niveau voor het bouwen en trainen van deep learning-modellen.
常常見到 Autoencoder 的變形以及應用,打算花幾篇的時間好好的研究一下,順便練習 Tensorflow.keras 的 API 使用。
- Wat is Autoencoder
- Types van Autoencoder
- Toepassing van Autoencoder
- Implementatie
- Grote voorbeelden
- Conclusie
Moeilijkheidsgraad: ★ ☆ ☆
後記: 由於 Tensorflow 2.0 alpha 已於 3/8號釋出,但此篇是在1月底完成的,故大家可以直接使用安裝使用看看,但需要更新至相對應的 CUDA10。
Wat is Autoencoder?
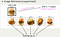
首先,什麼是 Autoencoder 呢? 不囉唆,先看圖吧!

Het oorspronkelijke concept van Autoencoder is zeer eenvoudig, het is het inbrengen van invoergegevens en het verkrijgen van exact dezelfde gegevens als de invoergegevens door middel van een neuraal netwerk.De encoder neemt eerst de invoergegevens op, comprimeert ze tot een vector met kleinere afmetingen Z, en voert de Z dan in de decoder in om de Z weer zijn oorspronkelijke grootte te geven.Dit klinkt eenvoudig, maar laten we eens nader bekijken of het ook zo eenvoudig is.

Encoder:
Encoder is verantwoordelijk voor het comprimeren van de oorspronkelijke invoergegevens tot een laag-dimensionale vector C. Deze C, die wij gewoonlijk code, latente vector of feature vector noemen, maar ik ben gewend het latente ruimte te noemen, omdat C een verborgen kenmerk vertegenwoordigt.Encoder kan de originele gegevens in een zinvolle laag-dimensionele vector comprimeren, wat betekent dat Autoencoder dimensionaliteitsreductie heeft, en de verborgen laag heeft niet-lineaire transformatie activeringsfunctie, zodat deze Encoder is als een krachtige versie van PCA, omdat Encoder niet-lineaire kan doen
Decoder:
Wat Decoder doet, is de latente ruimte zoveel mogelijk terugbrengen naar de invoergegevens, hetgeen een transformatie is van de feature-vectoren van de lagere dimensionale ruimte naar de hogere dimensionale ruimte.
Dus hoe meet je hoe goed Autoencoder werkt ! Simpelweg door de gelijkenis van de twee oorspronkelijke invoergegevens te vergelijken met de gereconstrueerde gegevens.Onze verliesfunctie kan dus worden geschreven als ….
Verliesfunctie:

Omdat we het verschil tussen deAutoEncoder wordt getraind met behulp van backpropagatie om de gewichten bij te werken, net als een normaal neuraal netwerk.de gewichten bijwerken.
Samenvattend, Autoencoder is ….
1. een zeer gebruikelijke modelarchitectuur, ook vaak gebruikt voor leren zonder toezicht
2. kan worden gebruikt als methode voor dimensiereductie voor niet-lineaire
3. kan worden gebruikt om gegevensrepresentatie te leren, representatieve kenmerktransformatie
Op dit punt zou het gemakkelijk moeten zijn om te begrijpen wat Autoencoder is, de architectuur is zeer eenvoudig, dus laten we eens kijken naar zijn transformaties!
Types van Autoencoder
Na het uitleggen van de basisprincipes van Autoencoder, is het tijd om het uitgebreide en geavanceerde gebruik van Autoencoder eens te bekijken!
2-1. Unet:
Unet kan worden gebruikt als een van de middelen voor beeldsegmentatie, en de Unet-architectuur kan worden gezien als een variant van Autoencoder.

2-2. Recursieve autoencoders:
Dit is een netwerk dat nieuwe invoertekst combineert met latente ruimte van andere ingangen, het doel van dit netwerk is sentimentsclassificatie.Dit kan ook worden gezien als een variant van Autoencoder, die de spaarzame tekst extraheert terwijl deze wordt getypt en de latente ruimte vindt die van belang is.

2Seq2Seq:
Sequence to Sequence is een generatief model dat al een tijdje erg populair is. Het is een prachtige oplossing voor het dilemma van RNN-types die niet kunnen omgaan met onbepaalde koppelingen, en heeft goed gepresteerd op onderwerpen als chatbot- en tekstgeneratie.Dit kan ook worden gezien als een soort Autoencoder-architectuur.

Toepassingen van Autoencoder
Na de vele en gevarieerde variaties van Autoencoder bekeken te hebben, laten we eens kijken waar Autoencoder nog meer voor gebruikt kan worden!
3-1. Model pretrained gewicht
Autoencoder kan ook gebruikt worden voor pretrain van gewicht, wat betekent dat het model een betere startwaarde vindt.Bijvoorbeeld, wanneer we willen het doel model te voltooien, zoals doel. verborgen laag is:, dus in het begin gebruiken we het concept van autoencoder om de input 784 dimensies, en de latente ruimte in het midden is 1000 dimensies om de pretrain eerst doen, zodat deze 1000 dimensies kan goed behouden de inputDan verwijderen we de oorspronkelijke uitvoer en voegen de tweede laag toe, enzovoort.Op die manier krijgt het hele model een betere startwaarde.
Huh! Er is een vreemd deel… als je 1000 neuronen gebruikt om 784 inputdimensies te vertegenwoordigen, betekent dat dan niet dat het netwerk helemaal opnieuw moet worden gekopieerd? Wat is het nut van trainen? Ja, daarom voegen we in een pre-training als deze meestal de L1 norm regularizer toe, zodat de verborgen laag niet helemaal opnieuw wordt gekopieerd.

Volgens de heer Li HongyiIn het verleden was het gebruikelijker een dergelijke methode te gebruiken voor de vooropleiding, maar nu, door de toename van de opleidingsvaardigheden, is het niet meer nodig deze methode te gebruiken.Maar als u heel weinig labelgegevens hebt, maar een heleboel ongelabelde gegevens, kunt u deze methode gebruiken om het gewicht voor te trainen, omdat Autoencoder zelf een methode zonder supervisie is, we gebruiken eerst de ongelabelde gegevens om het gewicht voor te trainen.We gebruiken eerst de ongelabelde gegevens om de gewichten voor te trainen, en gebruiken dan de gelabelde gegevens om de gewichten bij te stellen, zodat we een goed model krijgen.Voor meer details, zie de video van de heer Li, het is zeer goed uitgelegd!
3-2. Beeldsegmentatie
Het Unet-model dat we zojuist zagen, laten we er nog eens naar kijken, want het is in feite het meest voorkomende probleem bij het opsporen van defecten in de Taiwanese maakindustrie.
Eerst moeten we de invoergegevens labelen, die onze uitvoer zullen zijn. Wat we moeten doen is een netwerk construeren, de oorspronkelijke afbeelding invoeren (links, röntgenfoto’s van tanden) en de uitvoer genereren (rechts, classificatie van de tandstructuur).In dit geval zal de encoder & decoder een convolutielaag zijn met een sterk grafisch oordeel, die zinvolle kenmerken extraheert en deconvolutie terugvoert in de decoder om het segmentatie-resultaat te verkrijgen.

3-3. Video naar tekst
Voor een beeldbijschriftprobleem als dit gebruiken we het sequentie-naar-sequentie model, waarbij de invoer een stel foto’s is en de uitvoer een tekst die de foto’s beschrijft.Het sequentie-naar-sequentie model gebruikt LSTM + Conv net als encoder & decoder, die een opeenvolging van opeenvolgende acties & kan beschrijven met behulp van de CNN kernel om de benodigde latente ruimte in het beeld te extraheren.maar deze taak is erg moeilijk te doen, dus ik laat het je proberen als je geïnteresseerd bent!

3-4. Image Retrieval
Image Retrieval Je kunt een afbeelding invoeren en proberen de beste overeenkomst te vinden, maar als je pixelgewijs vergelijkt, dan is het heel gemakkelijk omAls u Autoencoder gebruikt om het beeld eerst te comprimeren in de latente ruimte en dan de overeenkomst te berekenen op de latente ruimte van het beeld, zal het resultaat veel beter zijn.Het resultaat is veel beter omdat elke dimensie in de latente ruimte een bepaald kenmerk kan vertegenwoordigen.Als de afstand wordt berekend op de latente ruimte, is het redelijk om gelijksoortige beelden te vinden.In het bijzonder zou dit een geweldige manier zijn om zonder toezicht te leren, zonder gegevens te labelen!
Hier zijnHet paper van Georey E. Hinton, de beroemde Deep Learning god, toont de grafiek die je wilt zoeken in de linkerbovenhoek, terwijl de andere allemaal grafieken zijn waarvan de autoencoder denkt dat ze erg op elkaar lijken.7133>

Content-gebaseerdeImage Retrieval
3-5. Anomaly Detection
Kan geen goede afbeelding vinden, dus moest ik deze gebruiken LOL
Het vinden van anomalieën is ook een veelvoorkomend fabricageprobleem, dus dit probleem kan ook worden geprobeerd met AutoencoderWe kunnen het proberen met Autoencoder!Laten we het eerst eens hebben over het feitelijke optreden van anomalieën. Anomalieën treden gewoonlijk zeer zelden op, bijvoorbeeld abnormale signalen in de machine, plotselinge temperatuurpieken ……, enz.Dit gebeurt één keer per maand (als het er meer zijn, moet de machine met pensioen). Als de gegevens elke 10 seconden worden verzameld, dan worden er elke maand 260.000 stuks gegevens verzameld, maar slechts in één periode is er sprake van anomalieën, wat eigenlijk een zeer onevenwichtige hoeveelheid gegevens is.
Dus de beste manier om met deze situatie om te gaan is te gaan voor de oorspronkelijke gegevens, die immers de grootste hoeveelheid gegevens is die we hebben!Als we de goede gegevens kunnen nemen en een goede autoencoder kunnen trainen, dan zullen, als er anomalieën in komen, de gereconstrueerde afbeeldingen natuurlijk breken.Zo zijn we op het idee gekomen om autoencoders te gebruiken om anomalieën te vinden!

Implementatie
Hier gebruiken we Mnist als een speelgoedvoorbeeld en implementeren we een Autoencoder met behulp van de Tensorflow.keras high-level API! Aangezien het nieuwe pakket voor tf.keras binnenkort is vrijgegeven, oefenen we met het gebruik van de Model subclassing methode in het bestand
4-1. Maak een model – Vallina_AE:
Eerst, importeer tensorflow!7133>

Het gebruik van tf.keras is zo simpel als wat, typ gewoon tf.keras!(Ik weet niet waar ik het over heb lol)
Load data & model preprocess
Eerst nemen we de Mnist data van tf.keras.dataset en doen een beetje preprocess
Nomalize: comprimeer de waarden tot tussen 0 en 1, de training zal gemakkelijker convergeren
Binarization: markeer de meer duidelijke gebieden, de training zal betere resultaten geven.
Model maken – Vallina_AE:
Dit is de methode die door het Tensorflow-document wordt geboden voor het maken van modellen.complexer.
Wat ik tot nu toe heb geleerd is om de laag in de __init __ plaats te maken en de forward pass in de aanroep te definiëren.
We gebruiken dus twee sequentiële modellen om de Encoder & decoder te maken. twee zijn een symmetrische structuur, de encoder is verbonden met de invoerlaag die verantwoordelijk is voor het dragen van de invoergegevens en vervolgens met de drie dichte lagen. de decoder is hetzelfde.
Opnieuw moeten we onder de oproep de encoder & decoder samenvoegen, waarbij we eerst de latente ruimte definiëren als de output van self.encoder.ruimte als de output van self.encoder, en dan de reconstructie als het resultaat van het passeren van de decoder.Vervolgens gebruiken we tf.keras.Model() om de twee modellen te verbinden die we in __init__ hebben gedefinieerd.AE_model = tf.keras.Model(inputs = self.encoder.input, outputs = reconstruction) specificeert input als de input van de encoder en output als de output van de decoder, en dat is het!Dan sturen we het AE_model terug en je bent klaar!
Model Compileren & training
Voordat Keras een model kan trainen, moet het worden gecompileerd voordat het in training kan worden gedropt.In het compileren geef je aan welke optimizer je wilt gebruiken en welk verlies je wilt berekenen.
Voor training gebruik je VallinaAE.fit om de data in te voeren, maar onthoud dat we onszelf aan het herstellen zijn, dus X en Y moeten in dezelfde data gegooid worden.
Laten we eens kijken naar de resultaten van het trainen van 100 epochs, het lijkt erop dat de reconstructieresultaten niet zo goed zijn als we dachten.

4-2. Een model maken- Conv_AE:
Zoals de naam al zegt, kunnen we de Convolutie-laag gebruiken als verborgen laag om kenmerken te leren die terug gereconstrueerd kunnen worden.
Na het veranderen van het model, kunt u de resultaten bekijken om te zien of er enige verbetering is.

Het lijkt erop dat de resultaten van Reconstructie veel beter zijn, met ongeveer 10 epochs van training.
4-3. Maak een model – denoise_AE:
Ook kan de autoencoder worden gebruikt voor het verwijderen van ruis, dus hier gaan we
Eerst kunnen we ruis toevoegen aan de originele afbeelding. De logica van het toevoegen van ruis is om een eenvoudige verschuiving uit te voeren op de originele pixel en dan willekeurige getallen toe te voegen.Het beeldvoorbewerkingsgedeelte kan worden gedaan door de clip eenvoudigweg 0 te maken als hij kleiner is dan 0 en 1 als hij groter is dan 1. Zoals hieronder te zien is, kunnen we na de beeldbewerking van de clip het beeld scherper maken en de duidelijke gebieden beter zichtbaar maken.Dit geeft ons een beter resultaat als we Autoencoder erin gooien.

en het model zelf en Conv_AEEr is geen verschil tussen het model zelf en Conv_AE, behalve dat het tijdens de fit moet worden veranderd in
denoise_AE.fit(train_images_noise, train_images, epochs=100, batch_size=128, shuffle=True)
om de oorspronkelijke ruis_gegevens te herstellen

Zoals u kunt zien, wordt op Mnist met een eenvoudige Autoencoder zeer snel een denoising-effect bereikt.
Goede voorbeelden
Dit is een goede bron voor degenen die geïnteresseerd zijn om er meer over te leren
- Autoencoders bouwen in Keras autoencoder serie is duidelijk geschreven.
- Tensorflow 2.0 officiële documentatie tutorial, iets heel compleet, gewoon schrijven een beetje moeilijk, om heel wat tijd te besteden om te zien (althans ik trek XD)
3. Li Hongyi leraar van deep learning is ook zeer aan te bevelen, spreken zeer duidelijk en gemakkelijk te begrijpen, niet-
Conclusie
Gebruik dit artikel om snel het basisconcept van Autoencoder, enkele variaties van Autoencoder en de toepassing vanscenario’s.4310>
De volgende artikelen zullen beginnen met generatieve modellen, die zich uitstrekken van het begrip autoencoder, VAE, tot GAN, en verdere uitbreidingen en morphs gaandeweg.
Als het artikel u bevalt, klapt u dan nog een paar keer (en niet één keer) als aanmoediging!
Lees de volledige code voor dit artikel:https://github.com/EvanstsaiTW/Generative_models/blob/master/AE_01_keras.ipynb
Geef een antwoord