SQL CHIT CHAT … Blog over Sql Server
On november 29, 2021 by adminSamenvatting
Common Table Expressions werden geïntroduceerd in SQL Server 2005. Zij vormen een van de verschillende soorten tabeluitdrukkingen die in Sql Server beschikbaar zijn. Een recursieve CTE is een type CTE dat naar zichzelf verwijst. Het wordt meestal gebruikt om hiërarchieën op te lossen.
In deze post zal ik proberen uit te leggen hoe CTE recursie werkt, waar het zit binnen de groep van tabel expressies beschikbaar in Sql Server en een paar case scenario’s waar de recursie schittert.
Tabel Expressies
Een tabel expressie is een benoemde query expressie die een relationele tabel vertegenwoordigt. Sql Server ondersteunt vier soorten tabeluitdrukkingen;
- Afgeleide tabellen
- Views
- ITVF (Inline Table Valued Functions aka parameterised views)
- CTE (Common Table Expressions)
- Recursieve CTE
In het algemeen worden tabeluitdrukkingen niet op de schijf gematerialiseerd. Het zijn virtuele tabellen die alleen in het RAM-geheugen aanwezig zijn (ze kunnen naar de schijf worden overgebracht als gevolg van bijvoorbeeld geheugendruk, de grootte van een virtuele tabel enzovoort). De zichtbaarheid van de tabel expressies kan variëren d.w.z. views en ITVF zijn db objecten zichtbaar op een database niveau, terwijl het toepassingsgebied altijd op een SQL-instructie niveau is – tabel expressies kunnen niet werken over verschillende sql verklaringen binnen een batch.
Voordelen van tabel expressies zijn niet gerelateerd aan query uitvoering prestaties, maar aan het logische aspect van de code !
Derived Tables
Derived tables zijn tabel expressies ook bekend als sub-queries. De expressies worden gedefinieerd in de FROM-clausule van een outer query. Het bereik van afgeleide tabellen is altijd de buitenste query.
De volgende code vertegenwoordigt een afgeleide tabel genaamd AUSCust.
Transact-SQL
|
1
2
3
4
5
6
7
8
|
SELECT AUSCust.*
FROM (
SELECT custid
,companyname
FROM dbo.Customers
WHERE country = N’Australia’
) AS AUSCust;
–AUSCust is een afgeleide tabel
|
De afgeleide tabel AUSCust is alleen zichtbaar voor de buitenste query en het bereik is beperkt tot het sql-statement.
Views
Views (soms virtuele relaties genoemd) zijn herbruikbare tabeluitdrukkingen. Een view definitie wordt opgeslagen als een Sql Server object samen met objecten zoals; door de gebruiker gedefinieerde tabellen, triggers, functies, stored procedures etc.
Het belangrijkste voordeel van Views ten opzichte van andere soorten tabel expressies is hun herbruikbaarheid, d.w.z. afgeleide queries en CTE hebben scope beperkt tot een enkel statement.
Views zijn niet gematerialiseerd, wat betekent dat de rijen geproduceerd door views niet permanent worden opgeslagen op schijf. Geïndexeerde views is Sql Server (vergelijkbaar, maar niet hetzelfde als de gematerialiseerde views in andere db platforms) zijn speciaal type views die kunnen hebben hun result-set permanent opgeslagen op schijf – meer over geïndexeerde views is hier te vinden.
Nog een paar basis richtlijnen over hoe SQL Views te definiëren.
-
SELECT * in de context van een View definitie gedraagt zich anders dan wanneer gebruikt als een query element in een batch.
Transact-SQL
12345CREATE VIEW dbo.vwTestASSELECT *FROM dbo.T1…De view-definitie zal alle kolommen uit de onderliggende tabel, dbo.T1, bevatten op het moment dat de view wordt aangemaakt. Dit betekent dat als we het schema van de tabel wijzigen (d.w.z. kolommen toevoegen en/of verwijderen), de wijzigingen niet zichtbaar zullen zijn voor de view – de view-definitie zal niet automatisch worden gewijzigd om de tabelwijzigingen te ondersteunen. Dit kan fouten veroorzaken in situaties waarin bijvoorbeeld een view niet bestaande kolommen uit een onderliggende tabel probeert te selecteren.
Om het probleem op te lossen kunnen we een van de twee systeem procedures gebruiken: sys.sp_refreshview of sys.sp_refreshsqlmodule.
Om dit gedrag te voorkomen volg de best practice en geef de kolommen expliciet een naam in de definitie van de view.- Views zijn tabel expressies en kunnen daarom niet worden geordend. Views zijn geen cursors! Het is echter mogelijk om de TOP/ORDER BY-constructie in de view-definitie te “misbruiken” in een poging gesorteerde uitvoer af te dwingen. bijv.
Transact-SQL
12345CREATE VIEW dbo.MyCursorViewASSELECT TOP(100 PERCENT) *FROM dbo.SomeTableORDER BY column1 DESCDe optimalisatie van de query zal de TOP/ORDER BY weglaten omdat het resultaat van een tabeluitdrukking altijd een tabel is – het selecteren van TOP(100 PERCENT) heeft hoe dan ook geen zin. Het idee achter tabelstructuren is afgeleid van een concept in de relationele databasetheorie dat bekend staat als Relation.
Tijdens het verwerken van een query die verwijst naar een view, wordt de query van de view-definitie ontvouwd of uitgebreid en geïmplementeerd in de context van de hoofdquery. De geconsolideerde code (query) wordt vervolgens geoptimaliseerd en uitgevoerd.
ITVF (Inline Table Valued Functions)
ITVF’s zijn herbruikbare tabeluitdrukkingen die invoerparameters ondersteunen. De functies kunnen worden behandeld als geparametriseerde views.
CTE (Common Table Expressions)
Gemeenschappelijke tabeluitdrukkingen zijn vergelijkbaar met afgeleide tabellen, maar met een aantal belangrijke voordelen;
Een CTE wordt gedefinieerd met behulp van een WITH statement, gevolgd door een tabeluitdrukkingsdefinitie. Om dubbelzinnigheid te voorkomen (TSQL gebruikt het WITH sleutelwoord ook voor andere doeleinden, b.v. WITH ENCRYPTION etc) MOET het statement dat voorafgaat aan de WITH clausule van CTE worden afgesloten met een semi-kolom. Dit is niet nodig als de WITH clausule het allereerste statement in een batch is, d.w.z. in een VIEW/ITVF definitie)
NOOT: Semi-kolom, de statement terminator wordt ondersteund door ANSI standaard en het wordt sterk aanbevolen om te gebruiken als onderdeel van TSQL programmeer praktijk.
Recursieve CTE
SQL Server ondersteunt recursieve query mogelijkheden geïmplementeerd via Recursieve CTEs sinds versie 2005(Yukon).
Elementen van een recursieve CTE
- Ankerlid(en) – Query-definities die;
- een geldige relationele resultatentabel opleveren
- WORDT ENKEL aan het begin van de query-uitvoering uitgevoerd
- wordt altijd vóór het eerste recursieve lid-definitie geplaatst
- het laatste ankerlid moet worden gevolgd door UNION ALL operator. De operator combineert het laatste ankerlid met het eerste recursieve lid
- UNION ALL multi-set operator. De operator werkt op
- recursief lid (leden) – Querydefinities die;
- een geldige relationele resultatentabel
- opleveren, hebben een verwijzing naar de CTE-naam. De verwijzing naar de CTE-naam vertegenwoordigt logischerwijs de vorige resultatenverzameling in een reeks van uitvoeringen. d.w.z. de eerste “vorige” resultatenverzameling in een reeks is het resultaat dat het ankerlid heeft teruggegeven.
- CTE Invocation – Definitieve instructie die recursie oproept
- Faalveilig mechanisme – MAXRECURSION-optie voorkomt dat het databanksysteem oneindige lussen maakt. Dit is een optioneel element.
Termination check
CTE’s recursive member heeft geen expliciete recursion termination check.
In veel programmeertalen kunnen we methode ontwerpen die zichzelf aanroept – een recursieve methode. Elke recursieve methode moet worden beëindigd wanneer aan een bepaalde voorwaarde is voldaan. Dit is Expliciete recursie beëindiging. Na dit punt begint de methode waarden terug te geven. Zonder eindpunt kan recursie eindigen met zichzelf “eindeloos” aan te roepen.
CTE’s recursieve lid beëindiging controle is impliciet , wat betekent dat de recursie stopt wanneer er geen rijen worden geretourneerd van de vorige CTE uitvoering.Hier is een klassiek voorbeeld van een recursie in imperatief programmeren. De onderstaande code berekent de factoriaal van een geheel getal met behulp van een recursieve functie(methode)-aanroep.
De volledige code van het consoleprogramma vindt u hier.
MAXRECURSION
Zoals hierboven vermeld, kunnen recursieve CTE’s en elke recursieve bewerking oneindige lussen veroorzaken als ze niet goed zijn ontworpen. Deze situatie kan een negatieve invloed hebben op de prestaties van de database. Sql Server engine heeft een fail-safe mechanisme dat oneindige executies niet toestaat.
Het aantal keren dat een recursief lid kan worden aangeroepen is standaard beperkt tot 100 (dit is exclusief de eenmalige anker executie). De code zal mislukken bij de 101ste keer dat het recursieve lid wordt uitgevoerd.
Msg 530, Level 16, State 1, Line xxx
Het statement is beëindigd. Het maximum van 100 recursies is bereikt voordat het statement is voltooid.Het aantal recursies wordt geregeld door de MAXRECURSION n query optie. De optie kan het standaard aantal toegestane recursies overschrijven. Parameter (n) vertegenwoordigt het recursie niveau. 0<=n <=32767
Belangrijke opmerking:: MAXRECURSION 0 – schakelt de recursie limiet uit!
Figuur 1 toont een voorbeeld van een recursieve CTE met zijn elementen

Figuur 1, Recursieve CTE elementenDeclaratieve recursie is heel anders dan de traditionele, imperatieve recursie. Afgezien van de verschillende code structuur, kunnen we het verschil zien tussen de expliciete en de impliciete beëindiging controle. In het CalculateFactorial-voorbeeld wordt het expliciete eindpunt duidelijk gedefinieerd door de voorwaarde: if (number == 0) then return 1.
In het geval van de recursieve CTE hierboven wordt het eindpunt impliciet gedefinieerd door de INNER JOIN-bewerking, meer bepaald door het resultaat van de logische uitdrukking in de ON-clausule: ON e.MgrId = c.EmpId. Het resultaat van de tabelbewerking bepaalt het aantal recursies. Dit zal duidelijker worden in de volgende secties.Gebruik recursieve CTE om hiërarchie van werknemers op te lossen
Er zijn veel scenario’s waarin we recursieve CTE’s kunnen gebruiken, d.w.z. om elementen enz. te scheiden. Het meest voorkomende scenario dat ik ben tegengekomen tijdens vele jaren van sequeling is het gebruik van recursieve CTE om verschillende hiërarchische problemen op te lossen.
De Werknemer boom hiërarchie is een klassiek voorbeeld van een hiërarchisch probleem dat kan worden opgelost met behulp van Recursieve CTE’s.
Voorbeeld
Laten we zeggen dat we een organisatie hebben met 12 werknemers. De volgende bedrijfsregels zijn van toepassing;
- Een werknemer moet een uniek id hebben, EmpId
- gedwongen door: Primary Key constraint op kolom EmpId
- Een werknemer kan door 0 of 1 manager worden beheerd.
- Geperst door: PK op EmpId, FK op MgrId en NULLable MgrId kolom
- Een manager kan een of meer werknemers beheren.
- afgedwongen door: Foreign Key constraint(self referenced) op MgrId-kolom
- Een manager kan zichzelf niet managen.
- afgedwongen door: CHECK constraint on MgrId column
De boomhiërarchie is geïmplementeerd in een tabel genaamd dbo.Employees. De scripts zijn hier te vinden.

Figuur 2, tabel WerknemersLaten we de werking van recursieve CTE’s zien door de vraag te beantwoorden: Wie zijn de directe en indirecte ondergeschikten van de manager met EmpId = 3?
Van de hiërarchieboom in figuur 2 kunnen we duidelijk zien dat Manager (EmpId = 3) direct leiding geeft aan medewerkers; EmpId=7, EmpId=8 en EmpId=9 en indirect leiding geeft aan; EmpId=10, EmpId=11 en EmpId=12.
Figuur 3 toont de EmpId=3 hiërarchie en het verwachte resultaat. De code is hier te vinden.

Figuur 3, EmpId=3 directe en indirecte ondergeschiktenHoe komen we nu tot het uiteindelijke resultaat.
Het recursieve deel in de huidige iteratie verwijst altijd naar zijn vorige resultaat uit de vorige iteratie. Het resultaat is een tabel expressie (of virtuele tabel) genaamd cte1 (de tabel aan de rechterkant van de INNER JOIN). Zoals we kunnen zien, bevat cte1 ook het ankergedeelte. In de allereerste run (de eerste iteratie), kan het recursieve deel niet verwijzen naar zijn vorige resultaat omdat er geen vorige iteratie was. Daarom wordt in de eerste iteratie alleen het ankergedeelte uitgevoerd en maar één keer tijdens het hele proces. De anker-query geeft het recursieve deel in de tweede iteratie zijn vorige resultaat. Het anker fungeert als een vliegwiel zo u wilt 🙂
Het uiteindelijke resultaat bouwt zich op door middel van iteraties, d.w.z. Anker resultaat + iteratie 1 resultaat + iteratie 2 resultaat …
De logische uitvoeringsvolgorde
De test query wordt uitgevoerd door de onderstaande logische volgorde te volgen:
- Het SELECT statement buiten de cte1 expressie roept de recursie op. De ankerquery wordt uitgevoerd en retourneert een virtuele tabel genaamd cte1. Het recursieve deel geeft een lege tabel terug omdat het geen vorig resultaat heeft. Vergeet niet dat de expressies in de set-gebaseerde benadering in één keer worden geëvalueerd.
 Figuur 4, cte1-waarde na 1e iteratie
Figuur 4, cte1-waarde na 1e iteratie - De tweede iteratie begint.Dit is de eerste recursie. Het ankergedeelte heeft zijn rol gespeeld in de eerste iteratie en geeft vanaf nu alleen lege sets terug. Het recursieve deel kan nu echter verwijzen naar zijn vorige resultaat (cte1 waarde na de eerste iteratie) in de INNER JOIN operator. De tabelbewerking levert het resultaat van de tweede iteratie op, zoals te zien is in de onderstaande figuur.
 FIguur 5, cte1-waarde na 2e iteratie
FIguur 5, cte1-waarde na 2e iteratie - De tweede iteratie levert een niet-lege verzameling op, dus gaat het proces verder met de derde iteratie – de tweede recursie. Het recursieve element verwijst nu naar het cte1-resultaat van de tweede iteratie.
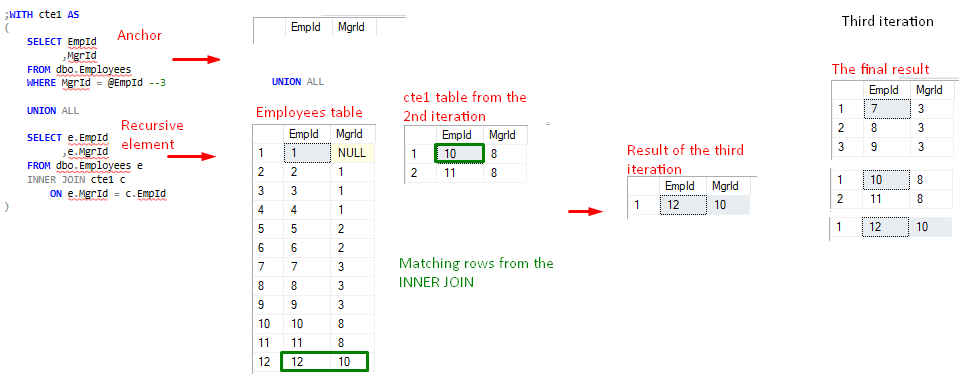
FIguur 6, cte1-waarde na 3e iteratie - Er gebeurt iets interessants bij de 4e iteratie – de derde recursiepoging. Volgens het vorige patroon gebruikt het recursieve element het cte1-resultaat van de vorige iteratie. Deze keer worden er echter geen rijen teruggegeven als resultaat van de INNER JOIN operatie, en het recursieve element geeft een lege set terug. Dit is het eerder genoemde impliciete eindpunt. In dit geval dicteert de logische expressie-evaluatie van INNER JOIN het aantal recursies.
Omdat het laatste cte1-resultaat een lege resultaatverzameling is, wordt de 4e iteratie (of 3e recursie) “geannuleerd” en wordt het proces met succes afgesloten.
Figuur 7, De laatste iteratie
De logische annulering van de 3e recursie (de laatste recursie die een lege resultaatverzameling heeft opgeleverd, telt niet mee) zal duidelijker worden in het volgende gedeelte, de analyse van het recursieve CTE-uitvoeringsplan.We kunnen OPTION(MAXRECURSION 2) query optie toevoegen aan het einde van de query waardoor het aantal toegestane recursies beperkt wordt tot 2. De query zal het juiste resultaat opleveren waaruit blijkt dat slechts twee recursies nodig zijn voor deze taak.Opmerking: Vanuit het perspectief van de fysieke uitvoering wordt de resultatenset progressief (als rijen omhoog borrelen) naar de netwerkbuffers en terug naar de clientapplicatie gestuurd.
Tot slot, het antwoord op de bovenstaande vraag is :
Er zijn zes werknemers die direct of indirect rapporteren aan de Emp = 3. Drie werknemers, EmpId= 7, EmpId=8 en EmpId=9 zijn directe ondergeschikten en EmpId=10, EmpId=11 en EmpId=12 zijn indirecte ondergeschikten.Weten we de mechanica van recursieve CTE, dan kunnen we gemakkelijk de volgende problemen oplossen.
- vind alle werknemers die hiërarchisch boven EmpId = 10 staan (code hier)
- vind EmpId=8 ’s directe en het tweede niveau ondergeschikten(code hier)
In het tweede voorbeeld controleren we de diepte van de hiërarchie door het aantal recursies te beperken.
Anchor element geeft ons het eerste niveau van de hiërarchie, in dit geval, de directe ondergeschikten. Elke recursie verplaatst zich vervolgens één hiërarchisch niveau naar beneden vanaf het eerste niveau. In het voorbeeld is het startpunt EmpId=8 en zijn/haar directe ondergeschikten. De eerste recursie verplaatst zich nog een niveau lager in de hiërarchie waar EmpId=8 ’s tweede niveau ondergeschikten “wonen”.Circulair referentie probleem
Een van de interessante dingen met hiërarchieën is dat de leden van een hiërarchie een gesloten lus kunnen vormen waarbij het laatste element in de hiërarchie verwijst naar het eerste element. De gesloten lus wordt ook wel circulaire verwijzing genoemd.
In dit soort gevallen zal het impliciete eindpunt, zoals de INNER JOIN operatie die eerder is uitgelegd, gewoon niet werken omdat het altijd een niet-lege result-set zal teruggeven voor de volgende recursie om verder te gaan. Het recursie gedeelte zal blijven draaien totdat het de fail-safe van Sql Server raakt, de MAXRECURSION query optie.Om de circulaire referentie situatie te demonstreren met behulp van de eerder opgezette test omgeving, moeten we
- Verwijder Primary en Foreign key constraints uit dbo.Employees tabel om de gesloten lussen scenario’s toe te staan.
- Een circulaire verwijzing maken (EmpId=10 zal zijn indirecte manager , EmpId = 3 beheren)
- De in de vorige voorbeelden gebruikte test query uitbreiden, om de hiërarchie van de elementen in de gesloten lus te kunnen analyseren.
De uitgebreide test query kan hier worden gevonden.
Voordat we verder gaan met het circulaire ref. voorbeeld, laten we eens kijken hoe de uitgebreide test query werkt. Commentarieer de predikaten van de WHERE-clausule (de laatste twee regels) uit en voer de query uit tegen de oorspronkelijke tabel dbo.Employee
 Figuur 8, Detecteren van het bestaan van cirkelvormige lussen in hiërarchieën
Figuur 8, Detecteren van het bestaan van cirkelvormige lussen in hiërarchieënHet resultaat van de uitgebreide query is precies hetzelfde als het resultaat dat in het vorige experiment in figuur 3 werd gepresenteerd. De uitvoer is uitgebreid met de volgende kolommen
- pth – Geeft de huidige hiërarchie grafisch weer. Aanvankelijk voegt het binnen het ankergedeelte gewoon de eerste ondergeschikte toe aan MgrId=3, de manager die we als uitgangspunt nemen. Nu neemt elk recursief element de vorige pth waarde en voegt er de volgende ondergeschikte aan toe.
- recLvl – geeft het huidige niveau van recursie weer. Ankeruitvoering wordt geteld als recLvl=0
- isCircRef – detecteert het bestaan van een circulaire verwijzing in de huidige hiërarchie(rij). Als onderdeel van recursief element, zoekt het naar het bestaan van een EmpId dat eerder was opgenomen in de pth string.
i.Als de vorige pth eruit ziet als 3->8->10 en de huidige recursie voegt ” ->3 ” toe, (3->8 >10 -> 3) wat betekent dat EmpId=3 niet alleen een indirecte superieur is aan EmpId=10, maar ook EmpId=10’s ondergeschikte is – ik ben baas of jouw baas, en jij bent mijn baas soort situatie 😐
Laten we nu de nodige veranderingen aanbrengen op dbo.Employees om de uitgebreide test query in actie te zien.
Verwijder PK en FK constraints om circulaire referenties toe te staan en voeg een “bad boy circulaire ref” toe aan de tabel.
Loop de uitgebreide test query, en analyseer de resultaten (vergeet niet de eerder becommentarieerde WHERE clausule aan het eind van het script te verwijderen)
Het script zal 100 recursies uitvoeren voordat het wordt onderbroken door de standaard MAXRECURSION. Het eindresultaat zal beperkt zijn tot twee recursies … EN cte1.recLvl <= 2; wat nodig is om de hiërarchie van EmpId=3 op te lossen.Figuur 9 toont een gesloten lus hiërarchie, het maximaal toegestane aantal recursies uitgeputte fout en de uitvoer die de gesloten lus laat zien.

Figuur 10, Circulaire verwijzing gedetecteerdEen paar opmerkingen over het script voor circulaire verwijzing.
Het script is slechts een idee over hoe je gesloten lussen in hiërarchieën kunt vinden. Het rapporteert alleen het eerste voorkomen van een circulaire verwijzing – probeer de WHERE clausule te verwijderen en observeer het resultaat.
Naar mijn mening kan het script (of een vergelijkbare versie van het script) worden gebruikt in een productie omgeving voor bijvoorbeeld troubleshooting doeleinden of als preventie voor het maken van circulaire verwijzingen in een bestaande hiërarchie. Het moet echter wel beveiligd worden met de juiste MAXRECURSION n, waarbij n de verwachte diepte van de hiërarchie is.Dit script is niet-relationeel en vertrouwt op een traversal techniek. Het is altijd de beste aanpak om declaratieve constraints (PK, FK, CHECK..) te gebruiken om gesloten lussen in gegevens te voorkomen.
Uitvoeringsplananalyse
In dit segment wordt uitgelegd hoe de query-optimalisator (QO) van Sql Server een recursieve CTE implementeert. Er is een gemeenschappelijk patroon dat QO gebruikt bij het construeren van het uitvoeringsplan. Voer de oorspronkelijke test query uit en neem het werkelijke uitvoeringsplan op
Net als de test query heeft het uitvoeringsplan twee takken: de ankertak en de recursieve tak. De aaneenschakelingsoperator, die de operator UNION ALL implementeert, verbindt de resultaten van de twee delen tot het resultaat van de query.
Laten we proberen de eerder genoemde logische uitvoeringsvolgorde en de feitelijke uitvoering van het proces met elkaar in overeenstemming te brengen.
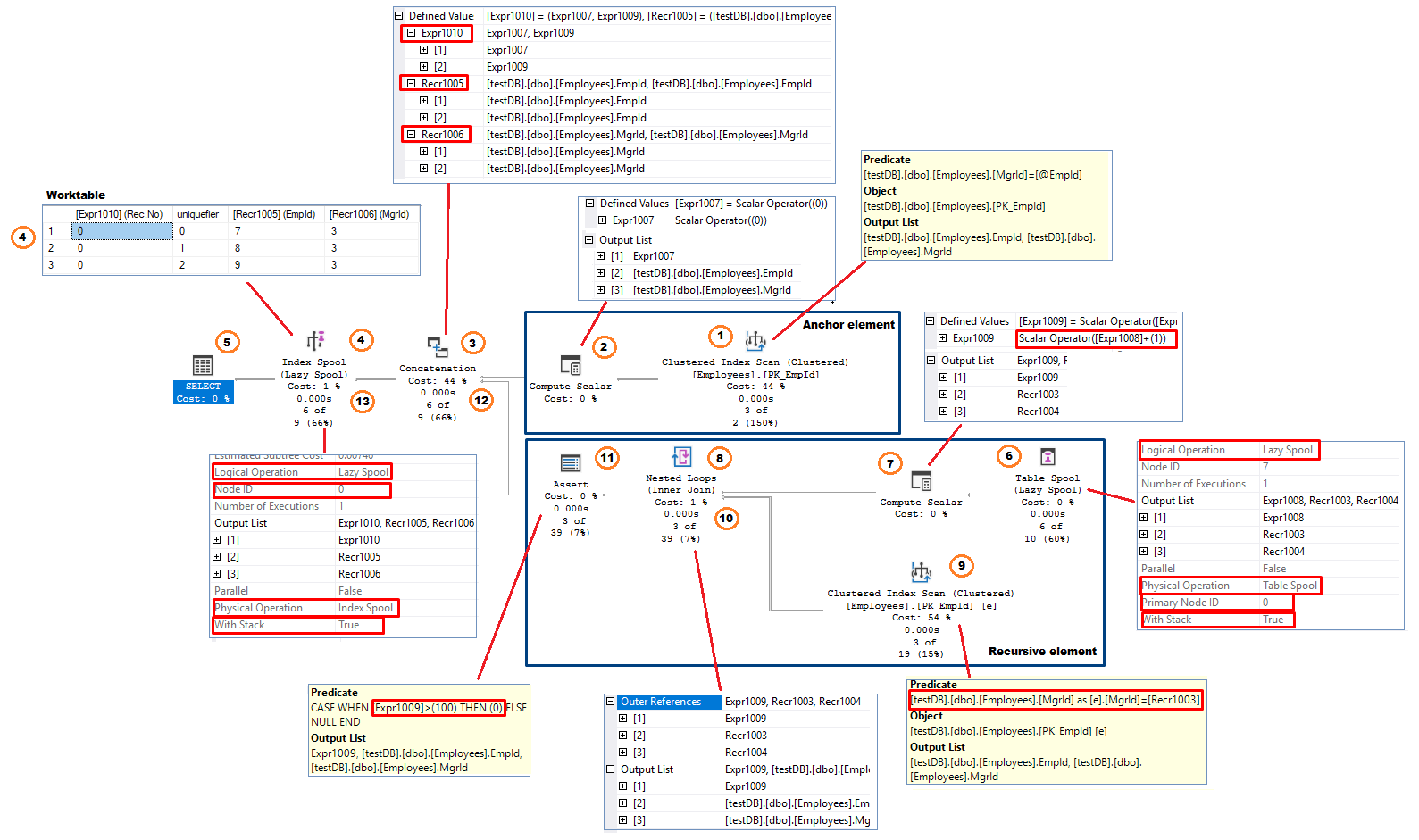
Figuur 11, Recursief CTE-uitvoeringsplanVolgend de gegevensstroom (van rechts naar links) ziet het proces er als volgt uit:
Ankerelement (wordt slechts eenmaal uitgevoerd)
- Operator voor geclusterde indexscan – het systeem voert een indexscan uit. In dit voorbeeld past het de uitdrukking MgrId = @EmpId toe als een residueel predicaat. Geselecteerde rijen (kolommen EmpId en MgrId) worden (rij voor rij) teruggegeven aan de vorige operator.
- Compute Scalar De operator voegt een kolom toe aan de uitvoer. In dit voorbeeld is de naam van de toegevoegde kolom . Dit vertegenwoordigt het Aantal recursies. De kolom heeft een beginwaarde van 0; =0
- Aaneenschakeling – combineert de ingangen van de twee takken. In de eerste iteratie ontvangt de operator alleen rijen van de ankertak. Hij verandert ook de namen van de outputkolommen. In dit voorbeeld zijn de nieuwe kolomnamen:
- = of * * houdt het aantal recursies vast dat in de recursieve tak is toegewezen. Het heeft geen waarde in de eerste iteratie.
- = EmpId(van het ankergedeelte) of EmpId(van het recursieve gedeelte)
- = MgrId(van het ankergedeelte) of MgrId (van het recursieve gedeelte)
- Index Spool (Lazy Spool) Deze operator slaat het resultaat, ontvangen van de Concatenation operator, op in een worktable. De eigenschap “Logische bewerking” is ingesteld op “Luie spoel”. Dit betekent dat de operator zijn inputrijen onmiddellijk teruggeeft en niet alle rijen accumuleert tot hij de uiteindelijke resultatenset krijgt (Eager Spool) . De werktabel is gestructureerd als een geclusterde index met als sleutelkolom – het recursienummer. Omdat de indexsleutel niet uniek is, voegt het systeem een interne uniquifier van 4 bytes toe aan de indexsleutel om ervoor te zorgen dat alle rijen in de index, vanuit het oogpunt van de fysieke implementatie, uniek identificeerbaar zijn. De operator heeft ook de eigenschap “With Stack” ingesteld op “True”, wat deze versie van de spool operator een Stack Spool maakt Een Stack Spool operator heeft altijd twee componenten – een Index Spool die de index structuur bouwt en een Table Spool die fungeert als een consument van de rijen opgeslagen in de worktable die werd gebouwd door de Index Spool.
In dit stadium retourneert de Index Spool operator rijen aan de SELECT operator en slaat dezelfde rijen op in de worktable. - SELECT operator retourneert EmpId en MgrId ( , ). Het sluit uit van het resultaat. De rijen worden naar de netwerkbuffer gestuurd als ze aankomen van de operatoren stroomafwaarts
Nadat alle rijen van de Index Scan operator zijn uitgeput, schakelt de Concatenation operator de context over naar de recursieve tak. De ankertak wordt tijdens het proces niet opnieuw uitgevoerd.
Recursief element
- Table Spool (Lazy Spool). Deze operator heeft geen inputs en fungeert, zoals vermeld in (4), als consument van de rijen die door de Index Spool worden geproduceerd en in een geclusterde werktafel worden opgeslagen. De eigenschap “Primary Node” is ingesteld op 0 en wijst naar de Index Spool Node Id. Het benadrukt de afhankelijkheid van de twee operatoren. De operator
- verwijdert rijen die hij in de vorige recursie heeft gelezen. Dit is de eerste recursie en er zijn geen eerder gelezen rijen die moeten worden verwijderd. De worktable bevat drie rijen (Figuur 4).
- Leest rijen gesorteerd op de index key + uniquifier in aflopende volgorde. In dit voorbeeld is de eerste gelezen rij EmpId=9, MgrId=3.
Ten slotte hernoemt de operator de namen van de uitvoerkolommen. =, = en wordt .
NOTE: De table spool operator kan worden waargenomen als de cte1 expressie aan de rechterkant van de INNER JOIN (figuur 4) - Compute Scalar De operator telt 1 op bij het huidige aantal recursies dat eerder in kolom .was opgeslagen. Het resultaat wordt opgeslagen in een nieuwe kolom, . = + 1 = 0 + 1 = 1. De operator voert drie kolommen uit, de twee uit de table spool ( en ) en
- Nested Loop(I) operator ontvangt rijen van zijn buitenste input, die de Compute Scalar van de vorige stap is, en gebruikt dan – vertegenwoordigt EmpId van de Table Spool operator, als een residueel predicaat in de Index Scan operator die in de binnenste input van de Loop is geplaatst. De binnenste input wordt eenmaal uitgevoerd voor elke rij uit de buitenste input.
- Index Scan operator retourneert alle gekwalificeerde rijen uit dbo.Employees tabel (twee kolommen; EmpId en MgrId) aan de geneste lus operator.
- Geneste lus (II): De operator combineert uit de buitenste invoer en EmpId en MgrId uit de binnenste invoer en geeft de drie kolom rijen door aan de volgende operator.
- Assert operator wordt gebruikt om te controleren op voorwaarden die vereisen dat de query wordt afgebroken met een foutmelding. In het geval van recursieve CTE’s implementeert de Assert operator de “MAXRECURSION n” query-optie. Hij controleert of het recursieve deel het toegestane (n) aantal recursies bereikt heeft of niet. Als het huidige aantal recursies, (zie stap 7) groter is dan (n), retourneert de operator 0 waardoor een run time error ontstaat. In dit voorbeeld gebruikt Sql Server zijn standaard MAXRECURSION waarde van 100. De expressie ziet er als volgt uit: CASE WHEN > 100 THEN 0 ELSE NULL Als we besluiten de failsafe uit te sluiten door MAXRECURSION 0 toe te voegen, zal de assert operator niet in het plan worden opgenomen.
- Concatenation combineert inputs van de twee takken. Deze keer ontvangt het alleen input van het recursieve deel en voert het kolommen/rijen uit zoals getoond in stap 3.
- Index Spool (Lazy Spool) voegt de output van de concatenation operator toe aan de worktable en geeft het dan door aan de SELECT operator. Op dit punt bevat de worktable in totaal 4 rijen: drie rijen van de ankeruitvoering en één van de eerste recursie. Volgens de geclusterde indexstructuur van de worktable wordt de nieuwe rij opgeslagen aan het einde van de worktable
-
Het proces wordt nu hervat vanaf stap 6. De table spool operator verwijdert eerder gelezen rijen (de eerste drie rijen) uit de worktable en leest de laatst ingevoegde rij, de vierde rij.
Conclusie
CTE (Common table expressions) is een type tabeluitdrukking dat beschikbaar is in Sql Server. Een CTE is een onafhankelijke tabel expressie die kan worden genoemd en waarnaar kan worden verwezen een of meer keer in de belangrijkste query.
Een van de belangrijkste toepassingen van CTEs is het schrijven van recursieve queries. Recursieve CTE’s volgen altijd dezelfde structuur – anker query, UNION ALL multi-set operator, recursief lid en het statement dat recursie oproept. Recursieve CTE’s zijn declaratieve recursies en hebben als zodanig andere eigenschappen dan hun imperatieve tegenhanger, b.v. declaratieve recursie-eindcontrole is van impliciete aard – het recursieproces stopt wanneer er geen rijen meer terugkomen in de vorige CTE. - Views zijn tabel expressies en kunnen daarom niet worden geordend. Views zijn geen cursors! Het is echter mogelijk om de TOP/ORDER BY-constructie in de view-definitie te “misbruiken” in een poging gesorteerde uitvoer af te dwingen. bijv.
Geef een antwoord