Hoe het web werkt
On oktober 15, 2021 by adminHet web is overal!
We gebruiken het meer dan ooit tevoren – ook op veel plaatsen waar je het misschien niet ziet. Want “het web” is meer dan alleen websites die je bezoekt door een URL in je browser in te voeren.
Hoe je ook je e-mails checkt op je mobiele telefoon of een tweet verstuurt – je gebruikt het internet (dus “het web”).
Hoe werkt dat allemaal? Welke technologieën komen erbij kijken en wat moet je leren (en in welke mate) als je webontwikkelaar wilt worden?
In dit artikel en de video (zie hierboven) zal ik niet in alle technische details duiken. Dit is bedoeld als een goed overzicht van de webfunctionaliteit.

CSS – The Complete Guide
Doe mee aan deze uitgebreide 20u+ cursus om CSS onder de knie te krijgen en te leren hoe je prachtige websites maakt.

JavaScript – The Complete Guide
Leer JavaScript vanaf nul om zeer interactieve en dynamische websites te bouwen in deze hands-on cursus!
# How Websites Work
Laten we beginnen met de meest voor de hand liggende manier om het internet te gebruiken: Je bezoekt een website als academind.com.
Op het moment dat je dit adres in je browser invoert en op ENTER drukt, gebeuren er een heleboel verschillende dingen:
- De URL wordt opgelost
- Er wordt een verzoek naar de server van de website gestuurd
- Het antwoord van de server wordt verwerkt
- De pagina wordt gerenderd en weergegeven

Eigenlijk, zou elke stap kunnen worden opgesplitst in meerdere andere stappen, maar voor een goed overzicht van hoe het allemaal werkt, is dat iets wat we hier kunnen negeren. Laten we alle vier de stappen eens bekijken.
Stap 1 – URL wordt opgelost
De code van de website staat natuurlijk niet op uw machine en moet dus worden opgehaald van een andere computer, waar hij wel staat opgeslagen. Deze “andere computer” wordt een “server” genoemd. Omdat die een bepaald doel dient, in ons geval, de website.
U voert “academind.com” in. (dat wordt “een domein” genoemd), maar eigenlijk wordt de server die de broncode van een website host, geïdentificeerd via IP-adressen (= Internet Protocol). De browser stuurt een “verzoek” (zie stap 2) naar de server met het IP-adres dat je hebt ingevoerd (indirect – je hebt natuurlijk “academind.com” ingevoerd).
In werkelijkheid voer je ook vaak "academind.com/learn" of iets dergelijks in. "academind.com" is het domein, "/learn" is het zogenaamde pad. Samen vormen ze de “URL” (“Uniform Resource Locator”).
Daarnaast kunt u de meeste websites bezoeken via "www.academind.com" of gewoon "academind.com". Technisch gezien is "www" een subdomein, maar de meeste websites leiden het verkeer naar "www" gewoon door naar de hoofdpagina.
Een IP-adres ziet er meestal als volgt uit: 172.56.180.5 (hoewel er ook een “modernere” vorm bestaat, IPv6 genaamd – maar dat laten we nu even buiten beschouwing). U kunt meer leren over IP-adressen op Wikipedia.
Hoe wordt het domein “academind.com” vertaald naar zijn IP-adres?
Er is een speciaal type server op het internet – niet slechts één, maar vele servers van dat type. Een zogenaamde “name server” of “DNS server” (waarbij DNS = “Domain Name System”).
De taak van deze DNS-servers is om domeinen te vertalen naar IP-adressen. Je kunt je die servers voorstellen als enorme woordenboeken waarin vertaaltabellen zijn opgeslagen: Domein => IP-adres.
Wanneer u “academind.com” invoert, haalt de browser dus eerst het IP-adres van zo’n DNS-server.
In het geval u zich dat afvraagt: De browser kent de adressen van deze domeinservers uit zijn hoofd, ze zijn als het ware in de browser geprogrammeerd.
Als het IP-adres eenmaal bekend is, gaan we verder met stap 2.
Stap 2 – Verzoek wordt verzonden
Met het IP-adres opgelost, gaat de browser verder en doet een verzoek aan de server met dat IP-adres.
“Een verzoek” is niet zomaar een term. Het is echt een technisch ding dat achter de schermen gebeurt.
De browser bundelt een hoop informatie (Wat is de exacte URL? Wat voor soort verzoek moet er worden gedaan? Moeten er metagegevens worden bijgevoegd?) en stuurt dat gegevenspakket naar het IP-adres.
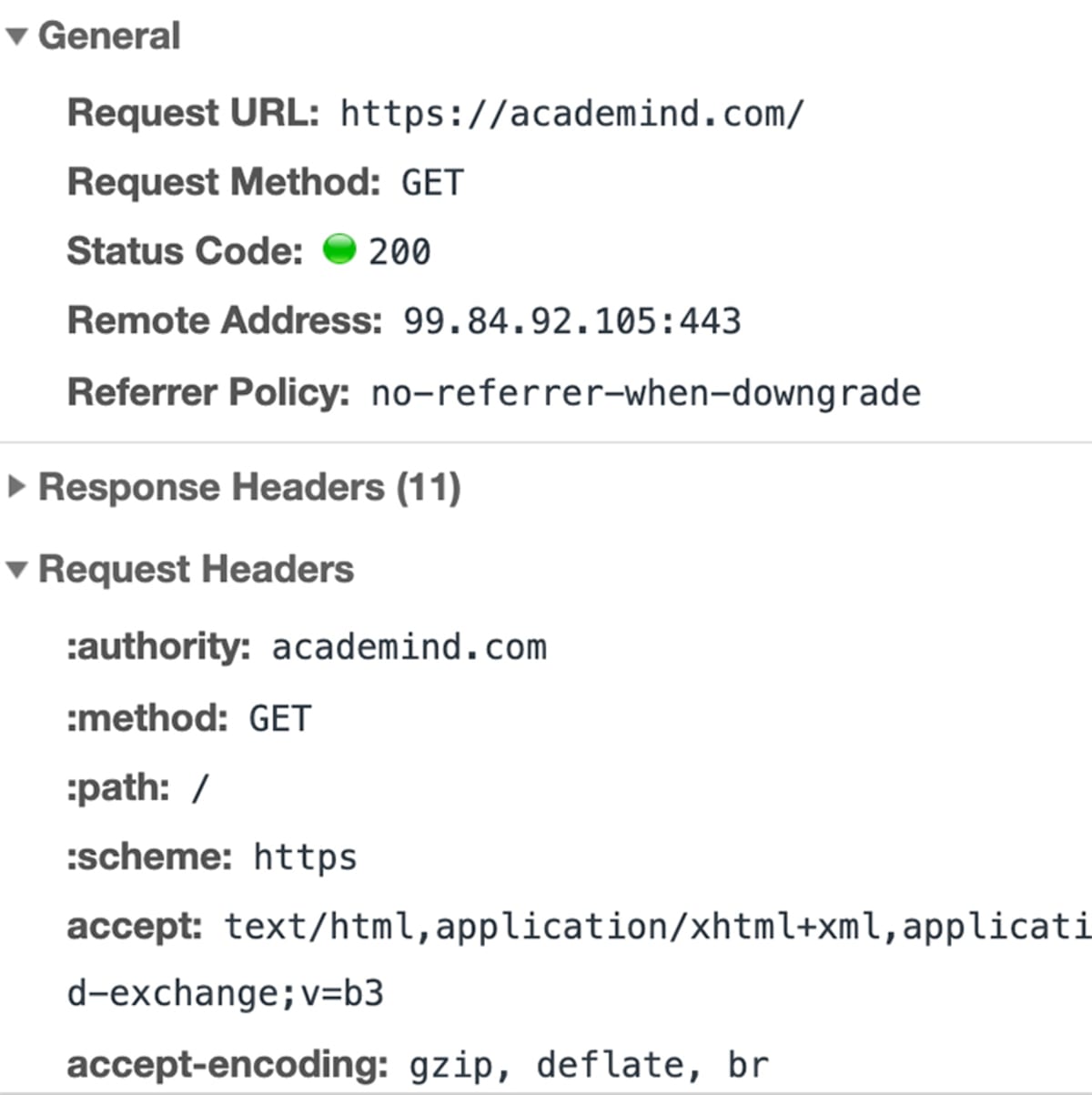
De gegevens worden verzonden via het “HyperText Transfer Protocol” (bekend als “HTTP”) – een gestandaardiseerd protocol waarin is vastgelegd hoe een verzoek (en antwoord) eruit moet zien, welke gegevens mogen worden bijgevoegd (en in welke vorm) en hoe het verzoek wordt ingediend. U kunt hier meer te weten komen over HTTP.
Omdat HTTP wordt gebruikt, ziet een volledige URL er eigenlijk als volgt uit: http://academind.com. De browser vult het automatisch voor je in.
En er is ook HTTPS – het is net HTTP maar dan versleuteld. De meeste moderne pagina’s (inclusief academind.com) gebruiken dat in plaats van HTTP. Een volledige URL wordt dan: https://academind.com.
Omdat het hele proces en formaat gestandaardiseerd is, hoeft men niet te raden hoe dat verzoek door de server gelezen moet worden.
De server behandelt het verzoek dan op de juiste manier en stuurt een zogenaamd “antwoord” terug. Nogmaals, een “response” is een technisch ding en een beetje vergelijkbaar met een “request”. Je zou kunnen zeggen dat het in feite een “verzoek” in omgekeerde richting is.
Zoals een verzoek kan een antwoord gegevens, metadata enz. bevatten. Wanneer een pagina zoals academind.com wordt opgevraagd, bevat het antwoord de code die nodig is om de pagina op het scherm weer te geven.
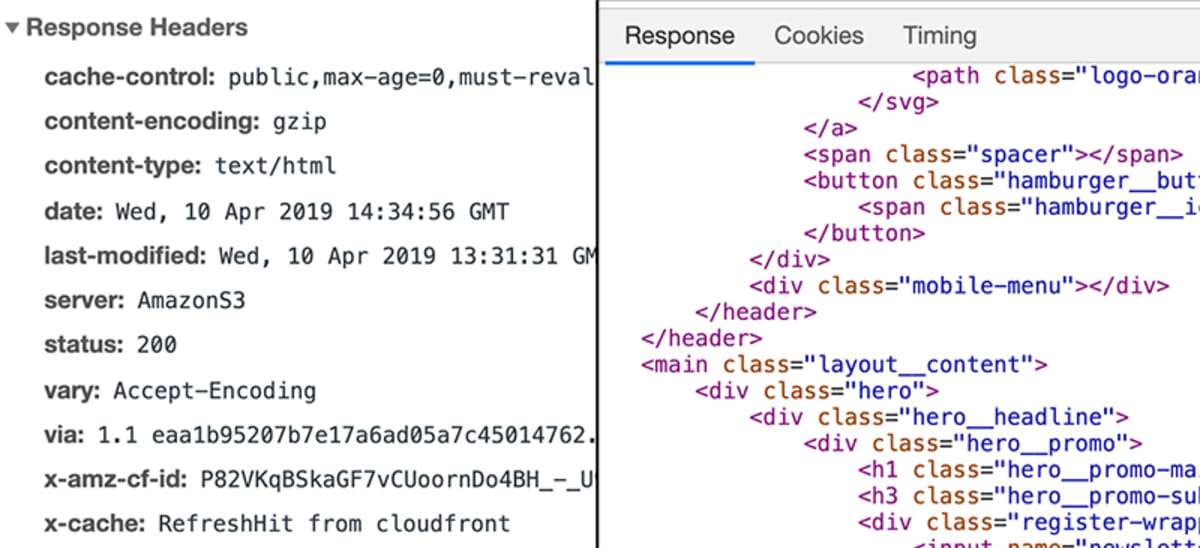
Wat gebeurt er op de server?
Dat wordt bepaald door webontwikkelaars. Uiteindelijk moet er een antwoord worden verstuurd. Dat antwoord hoeft niet “een website” te bevatten. Het kan alle gegevens bevatten – ook bestanden of afbeeldingen.
Sommige servers zijn geprogrammeerd om websites dynamisch te genereren op basis van het verzoek (b.v. een profielpagina die uw persoonlijke gegevens bevat), andere servers sturen vooraf gegenereerde HTML-pagina’s terug (b.v. een nieuwspagina). Of beide wordt gedaan – voor verschillende delen van een webpagina. Er is ook nog een derde alternatief: Websites die wel voorgegenereerd zijn, maar waarvan het uiterlijk en de gegevens in de browser veranderen.
De verschillende soorten websites zijn niet echt de focus van dit artikel. Als u daar meer over wilt leren, bekijk dan dit artikel + video.
Voor ons eenvoudige geval hebben we een server die de code retourneert om een website weer te geven. Dus laten we verder gaan met stap 3.
Stap 3 – Response Is Parsed
De browser ontvangt het antwoord dat door de server is verzonden. Dit alleen, toont niets op het scherm niet.
In plaats daarvan, de volgende stap is dat de browser het antwoord parseert. Net zoals de server dat met het verzoek heeft gedaan. Ook hier helpt de standaardisatie die door HTTP wordt afgedwongen natuurlijk.
De browser controleert de gegevens en metadata die in het antwoord zijn ingesloten. En op basis daarvan beslist hij wat hij moet doen.
U hebt misschien gevallen gehad waarin een PDF in uw browser werd geopend. Dat gebeurde omdat het antwoord de browser meedeelde dat het niet om een website maar om een PDF-document ging. En de browser probeert het beste afhandelingsmechanisme te kiezen voor elk gegevenstype dat hij aantreft.
Terug naar ons website-scenario.
In dat geval zou de respons een specifiek stukje metadata bevatten, dat de browser vertelt dat de responsgegevens van het type text/html zijn.
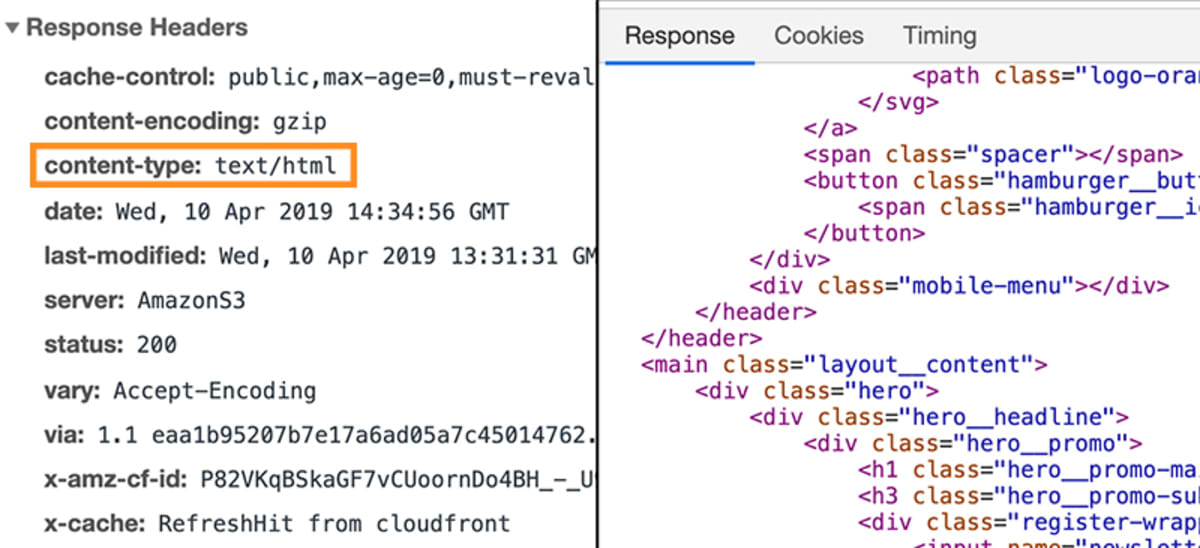
Dit stelt de browser in staat om de feitelijke gegevens die als HTML-code aan het antwoord zijn gekoppeld, te ontleden.
HTML is de belangrijkste “programmeertaal” (technisch gezien is het geen programmeertaal – je kunt er geen logica mee schrijven) van het web. HTML staat voor “Hyper Text Markup Language” en beschrijft de structuur van een webpagina.
De code ziet er als volgt uit:
<h1>Breaking News!</h1><p>Websites work because browser understand HTML!</p><h1> en <p> zijn zogenaamde “HTML-tags” en als je meer over HTML wilt leren, is deze serie een prima plek om naartoe te gaan.
Elke HTML-tag heeft een semantische betekenis die de browser begrijpt, omdat HTML ook gestandaardiseerd is. Er hoeft dus niet te worden gegokt naar de betekenis van een <h1>-tag.
De browser weet hoe HTML moet worden geparseerd en doorloopt nu eenvoudig de volledige responsgegevens (ook wel “de responsbody” genoemd) om de website te renderen.
Stap 4 – De pagina wordt weergegeven
Zoals gezegd, doorloopt de browser de door de server geretourneerde HTML-gegevens en bouwt op basis daarvan een website.
Het is belangrijk te weten dat HTML geen instructies bevat over hoe de site eruit moet zien (d.w.z. hoe deze moet worden vormgegeven). Het definieert eigenlijk alleen de structuur en vertelt de browser welke inhoud een kop is, welke inhoud een afbeelding is, welke inhoud een paragraaf is, enz. Dit is vooral belangrijk voor de toegankelijkheid – schermlezers halen alle nuttige informatie uit de HTML-structuur.
Een pagina die alleen HTML bevat, zou er echter zo uitzien:

Niet zo mooi, toch?
Daarom is er een andere belangrijke technologie (een andere “programmeertaal”, die niet echt een programmeertaal is): CSS (“Cascading Style Sheets”).
CSS draait om het toevoegen van styling aan de website. Dat gebeurt via “CSS-regels”:
h1 { color: blue;}Deze regel zou alle <h1> tags blauw kleuren.
Regels als deze kunnen binnen de HTML-code worden toegevoegd, maar meestal maken ze deel uit van aparte .css bestanden die apart worden aangevraagd.
Zonder hier in al te veel details te duiken, heeft dat een belangrijke implicatie: Een website kan uit meer bestaan dan de gegevens van de eerste respons die we krijgen.
In de praktijk halen websites veel extra gegevens op (via extra verzoeken en reacties) die worden afgetrapt zodra de eerste respons is binnengekomen.
Hoe gaat dat in zijn werk?
Welnu, de HTML-code van de eerste reactie bevat simpelweg instructies om meer gegevens op te halen via nieuwe verzoeken – en de browser begrijpt deze instructies:
<link rel="stylesheet" href="/page-styles.css" />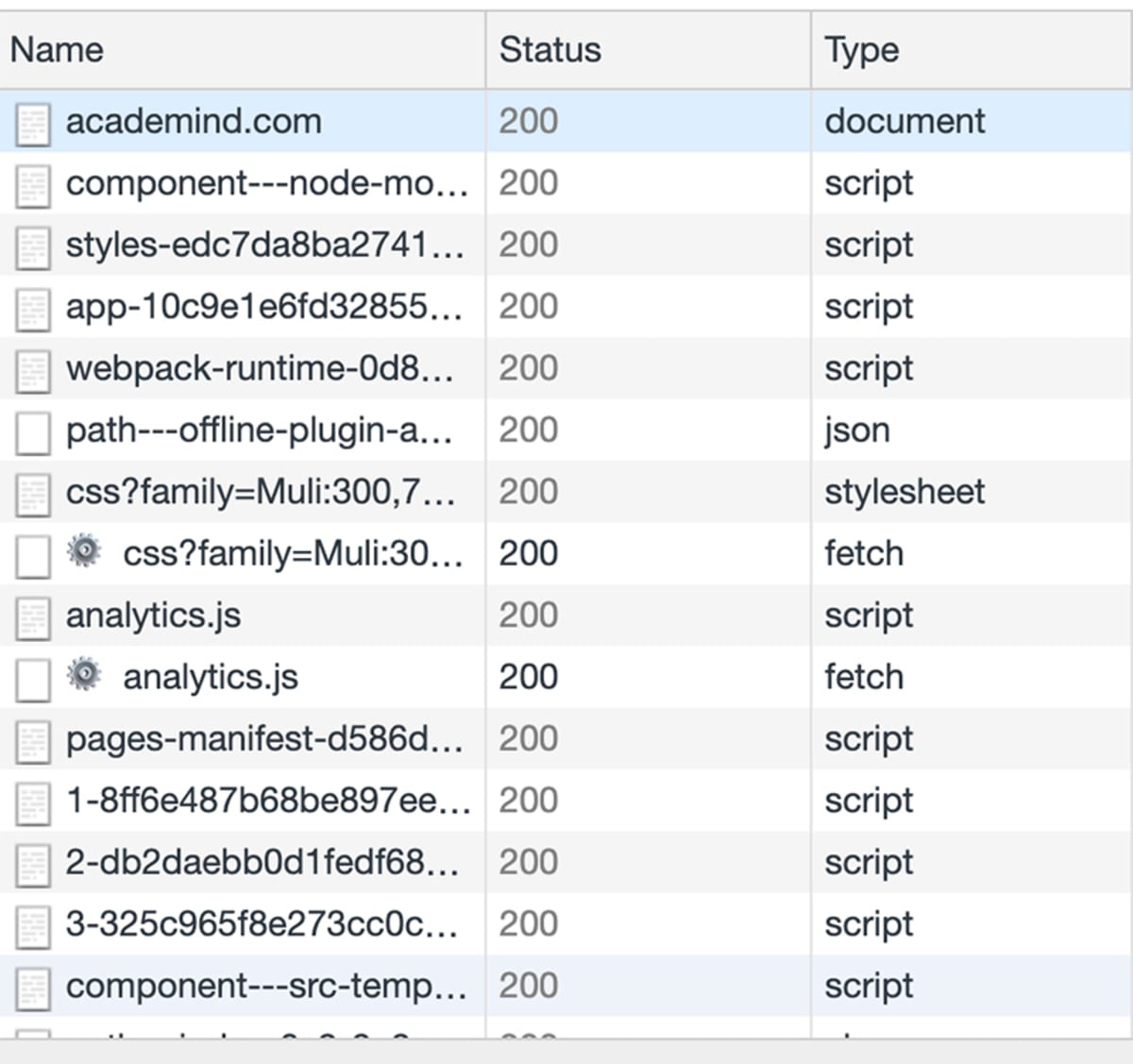
Opnieuw, ik zal hier niet in meer details duiken. Als u meer wilt weten over CSS, is onze complete gids zeer nuttig!
Samen met CSS kan de browser webpagina’s als volgt weergeven:

Er is eigenlijk nog een programmeertaal bij betrokken (deze keer is het echt een programmeertaal!): JavaScript.
Het is niet altijd zichtbaar, maar alle dynamische inhoud die je op een website vindt (bijv. tabbladen, overlays enz.) is eigenlijk alleen mogelijk dankzij JavaScript. Hiermee kunnen webontwikkelaars code definiëren die in de browser wordt uitgevoerd (niet op de server), zodat JavaScript kan worden gebruikt om de website te veranderen terwijl de gebruiker hem bekijkt.
Zoals eerder, als u meer wilt leren, bekijk dan onze JavaScript-hulpbronnen, bijvoorbeeld onze complete cursus.
Dit zijn de vier stappen die altijd aan de orde zijn als je een pagina-adres als academind.com invoert en daarna de inhoud van de website in je browser ziet.
# Server-side vs Browser-side
Van de vier stappen hierboven heb je geleerd dat we twee belangrijke “kanten” kunnen onderscheiden als we het over het web hebben: Server-side en Browser-side (of: Client-side aangezien we ook zonder browser het internet op kunnen – zie hieronder!).
Als je geïnteresseerd bent om webontwikkelaar te worden, is het belangrijk om te weten dat je voor deze kanten verschillende technologieën en programmeertalen gebruikt.
Server-side
Je hebt server-side programmeertalen nodig – dat wil zeggen talen die niet in de browser werken, maar die op een normale computer kunnen draaien (een server is uiteindelijk gewoon een normale computer).
Voorbeelden hiervan zijn:
- Node.js
- PHP
- Python
Belangrijk: Met uitzondering van PHP kunt u deze programmeertalen ook voor andere doeleinden dan webontwikkeling gebruiken.
Hoewel Node.js inderdaad voornamelijk wordt gebruikt voor server-side programmeren (hoewel het daar technisch gezien niet toe beperkt is), is Python ook erg populair voor data science en machine learning.
Browser-side
In de browser zijn er precies drie talen/technologieën die je moet leren. Maar terwijl de server-side talen alternatieven waren, zijn deze drie browser-side talen allemaal verplicht om te kennen en te begrijpen:
- HTML (voor de structuur)
- CSS (voor de styling)
- JavaScript (voor dynamische inhoud)
# “Behind the Scenes” Internet
Tot nu toe hebben we het over websites gehad. D.w.z. het geval waarin je een URL (b.v. “academind.com/learn”) in de browser invoert en je krijgt een website terug.
Maar het internet is meer dan dat. Sterker nog, je gebruikt het elke dag voor meer dan dat!
Het kernidee van verzoeken en antwoorden is altijd hetzelfde. Maar niet elk antwoord is noodzakelijkerwijs een website. En niet elk verzoek wil een website.
De metadata die aan verzoeken en antwoorden zijn gekoppeld, bepalen welke gegevens worden opgevraagd en teruggestuurd. Natuurlijk moeten beide betrokken partijen (d.w.z. client en server) de opgevraagde en teruggezonden gegevens ondersteunen.
Je kunt bijvoorbeeld geen PDF opvragen bij "academind.com". U zou een dergelijk verzoek kunnen verzenden, maar u zou geen PDF terugkrijgen – eenvoudigweg omdat wij dit soort opgevraagde gegevens voor deze specifieke URL niet ondersteunen.
Er zijn echter veel servers die zich hebben gespecialiseerd in het aanbieden van URL’s die bepaalde gegevens retourneren. Dergelijke diensten worden ook wel “API’s” (“Application Programming Interface”) genoemd.
Zo sturen mobiele apps bijvoorbeeld “onzichtbare” HTTP-verzoeken naar dergelijke API’s (naar specifieke URL’s die bij hen bekend zijn) om gegevens op te halen of op te slaan. Twitter haalt bijvoorbeeld de tweetfeed op.
En zelfs op webpagina’s worden dergelijke “onzichtbare” verzoeken verzonden. Als u zich aanmeldt voor onze nieuwsbrief (wat u natuurlijk moet doen!), wordt er geen nieuwe pagina geladen. Want achter de schermen worden gegevens uitgewisseld. Ook al is de client in dit geval de browser, het verzoek dat wordt verzonden wil geen website terug. En de server URL die het ontvangt biedt geen website – in plaats daarvan weet de server hoe hij met je email adres moet omgaan.
We zouden hier veel meer in detail kunnen treden, maar dit is al een lang artikel. Je zou nu een goed begrip moeten hebben van hoe het web werkt en welke kerntechnologieën daarbij betrokken zijn.
Geef een antwoord