Hoe gebruik je Tesseract op Windows
On januari 14, 2022 by admin
Tesseract is een optische tekenherkenningssoftware die is ontwikkeld door Google. Het is een OCR-programma met open broncode. Er zijn veel versies van Tesseract, maar wij gebruiken versie 4.0.
In versie 4 heeft Tesseract een op Long Short Term Memory (LSTM) gebaseerde herkenningsengine geïmplementeerd. LSTM is een soort van Recurrent Neural Network (RNN). De op LSTM gebaseerde herkenning werkt veel effectiever dan de oude (CNN-gebaseerde) herkenningsprocessen.
Dankzij tesseract, zullen we in staat zijn om de inhoud van onze afbeeldingen op te slaan als tekst bestanden.
Installatie
De isntallatie is afhankelijk van uw besturingssysteem. Nu gaan we de vensters doorlopen. Laten we eerst tesseract downloaden en installeren via deze link. (Het download een exe bestand.) We stellen het exe bestand eenvoudig in.
Daarna moeten we een PATH toevoegen aan windows systeem variabelen. Eigenlijk is het een makkelijke stap. Eerst zoeken en kopiëren we de hoofdmap van de tesseract installatie. Dat moet er zo uitzien :
C:\Program Files\Tesseract-OCR
En dan in de zoekbalk van Windows Geavanceerde systeem instellingen
Geavanceerde systeem instellingen > Geavanceerd > Omgevingsvariabelen > PATH > Nieuw
We plakken het bron pad dat we gekopieerd hebben en we slaan deze configuraties op. Na deze stap moet de computer opnieuw worden opgestart om de configuraties toe te passen.
De tesseract installatie is voltooid. U kunt de installatie bevestigen vanaf de commandoregel. Wanneer we tesseract commando uitvoeren op de command line, zou het ons informatie moeten geven over het programma.
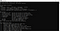
Nu kunnen we verder gaan met het python gedeelte. Om tesseract op python te gebruiken, moeten we de pytesseract-bibliotheek downloaden. Deze bibliotheek kan worden gedownload via pip naar de omgeving die u gebruikt.
pip install pytesseract
Nu is tesseract klaar voor gebruik!!
Coding
Het is heel eenvoudig om tesseract te gebruiken. Het moeilijke deel is het optimaliseren van de instellingen.
Want als je een succesvolle OCR wilt maken, moet je voorzichtig zijn met de beeldbewerking en de OCR instellingen.
Laten we OCR op het bonnetje toepassen.

De bibliotheken importeren
import pytesseract
from PIL import Image
import cv2
import numpy as np
De DPI-waarde van de afbeelding instellen
Dots per inch (DPI, of dpi) is een maat voor de puntdichtheid van video- of beeldscanners. DPI waarde is een belangrijk ding om OCR te draaien. Want als DPI waarde is lager dan 300, kan het verminderen van het succes van OCR.
file_path= 'receipt.jpg'
im = Image.open(file_path)
im.save('ocr.png', dpi=(300, 300))
Toepassing van enkele technieken om beeld schoner
Voreerst schalen we onze afbeelding met x2. Als de tekens klein zijn, moeten we het beeld schalen om het te herkennen. Daarna passen we een eenvoudige drempel techniek toe. Het is Binary Threshold. Eerst moet je proberen met 127 waarde, daarna kunnen verschillende variabelen worden geprobeerd. De drempelwaarde verandert de pixel in zwart als de pixelwaarde boven de drempelwaarde komt. Als we het beeld grijstinten maken, krijgen we een zwart-wit beeld.
Er zijn verschillende drempel technieken. Je kunt de bron website bekijken met deze link.

Tesseract uitvoeren
Nu kunnen we tesseract uitvoeren. Het heeft een image_to_string() functie. Het geeft ons een string als uitvoer.
text = pytesseract.image_to_string(treshold)
Opslaan uitvoer
We kunnen de uitvoer opslaan met de volgende code.
with open("Output.txt", "w",5 ,"utf-8") as text_file:
text_file.write(text)
De uitvoer van de OCR is als volgt:
Het resultaat is zeer succesvol. Als een groter succes gewenst is, kunnen verschillende bewerkingen op het beeld worden toegepast.
Geef een antwoord