WindowsでのTesseractの使い方
On 1月 14, 2022 by admin
Tesseract はGoogleが開発した光学文字認識ソフトです。 そのオープンソースの OCR ツールです。 バージョン 4 では、Long Short Term Memory (LSTM) ベースの認識エンジンが実装されました。 LSTMはRecurrent Neural Network(RNN)の一種です。 LSTM ベースの認識は、従来の (CNN ベースの) 認識プロセスよりもはるかに効果的に機能します。
Tesseract のおかげで、画像のコンテンツをテキストファイルとして保存することができます。 それでは、ウィンドウズで行っていきます。 まず、このリンクからtesseractをダウンロードし、インストールしましょう。 (
その後、Windowsのシステム変数にPATHを追加してください。 実はこれは簡単なステップです。 まず、テッセラクトのルートフォルダを探し、コピーします。
C:\Program Files\Tesseract-OCR
そして、Windows の検索バーにある Advanced System Settings
Advanced system settings > Advanced > Environment variables > PATH > New
そして、コピーしたソースを貼り付けて設定を保存してください。
Tesseract のインストールが完了しました。 コマンドラインからインストールを確認することができます。
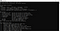
さて、次はPython編に進みましょう。 python上でtesseractを使うには、pytesseractライブラリをダウンロードする必要があります。
pip install pytesseract
これでテッセラクトは使えるようになりました!
コーディング
テッセラクトを使うのは本当に簡単です。 難しいのは設定を最適化することです。
OCRを成功させるには、画像処理のステップとOCRの設定に注意する必要があるからです。
レシートにOCRを適用してみましょう。

Importing The Libraries
import pytesseract
from PIL import Image
import cv2
import numpy as np
画像のDPI値の設定
Dots per inch (DPI, or dpi) is a measure of video or image scanner dot density. DPI 値は、OCR を実行するために重要なものです。 DPI 値が 300 より低い場合、OCR の成功率が低下することがあります。
file_path= 'receipt.jpg'
im = Image.open(file_path)
im.save('ocr.png', dpi=(300, 300))
Applying Some Techniques to Make Image Cleaner
Firstly we scale our image with x2.は、最初に、画像を拡大縮小します。 文字が小さい場合、それを認識するために画像を拡大縮小する必要があります。 その後、簡単な閾値を適用します。 バイナリ閾値です。 まず、127の値で試してみて、その後、さまざまな変数を試してみてください。 閾値は、ピクセル値が閾値以上であれば、そのピクセルを黒に変更します。 グレースケール画像にすると、白黒画像になります。
いろいろな閾値のテクニックがあります。

Tesseract の実行
さて、Tesseract を実行してみましょう。 image_to_string() 関数を持っています。
text = pytesseract.image_to_string(treshold)
出力を保存する
次のコードで出力を保存できます。
with open("Output.txt", "w",5 ,"utf-8") as text_file:
text_file.write(text)
OCRの出力は次のとおりです。 より高い成功が必要な場合は、画像に別の操作を適用することができます.
。
コメントを残す