SQL CHIT CHAT … Sql Serverに関するブログ
On 11月 29, 2021 by adminSummary
Common Table ExpressionsはSQL Server 2005で導入されたものである。 これは、Sql Server で利用可能ないくつかのタイプのテーブル式の 1 つを表します。 再帰的 CTE は、自分自身を参照する CTE の一種です。
この投稿では、CTE の再帰がどのように機能するか、SQL Server で使用可能なテーブル式のグループ内での位置付け、および再帰が輝くいくつかのケース シナリオを説明します。 Sql Server は 4 種類のテーブル式をサポートしています。
- Derived tables
- Views
- ITVF (Inline Table Valued Functions、別名 parameterised views)
- CTE (Common Table Expressions)
- Recursive CTE
通常、テーブル式のデータはディスク上には現れません。 それらは RAM メモリ内にのみ存在する仮想テーブルである (それらは、例えばメモリ圧迫、仮想テーブルのサイズなどの結果としてディスクに流出することがある)。 テーブル式の可視性は、ビューおよび ITVF がデータベース レベルで可視化されるデータベース オブジェクトであるのに対し、スコープは常に SQL 文のレベルです。 この式は外部クエリのFROM句で定義されます。
次のコードは、AUSCustという派生テーブルを表しています。
Transact-
|
1
2
3
の場合 4
5
6
7
8
|
SELECT AUSCust.SELECT AUSCust.SELECT AUSCust.*
FROM (
SELECT custid
,companyname
FROM dbo.Customers
WHERE country = N’Australia’
) AS AUSCust;
–AUSCust は派生テーブルです
|
派生テーブル AUSCust は外部クエリーにのみ見え、範囲は SQL 文に限定されます。
Views
ビュー(時々仮想関係として参照)は再利用できるテーブル式のことです。 ビュー定義は、ユーザー定義テーブル、トリガー、関数、ストアドプロシージャなどのオブジェクトと共に Sql Server オブジェクトとして格納されます。
他のタイプのテーブル式に対するビューの主な利点は、再利用性、すなわち派生クエリと CTE が単一の文に範囲を限定していることです。 Sql Server のインデックス付きビュー (他のデータベース プラットフォームのマテリアライズド ビューと似ていますが同じではありません) は、結果セットをディスクに永久に保存できる特別なタイプのビューです。
SQL ビューの定義方法に関するいくつかの基本ガイドラインです。
Transact->
|
1
2
4
5
|
CREATE VIEW dbo.vwTest
AS
SELECT *
FROM dbo.T1
…
|
ビュー定義には、ビュー作成時に基礎となるテーブル dbo.T1 からすべての列が含まれます。 これは、テーブル スキーマを変更する場合 (すなわち、列の追加や削除)、変更はビューに表示されないことを意味します – ビュー定義は、テーブルの変更をサポートするために自動的に変更されません。
この問題を解決するには、次の 2 つのシステム プロシージャのいずれかを使用します。sys.sp_refreshview または sys.sp_refreshsqlmodule.
この動作を防ぐには、ベスト プラクティスに従って、ビューの定義で列に明示的に名前を付けます。 ビューはカーソルではありません! しかし、並べ替えられた出力を強制するために、ビュー定義で TOP/ORDER BY 構成を「悪用」することは可能です。
Transact->
|
1
2
3
4
5
|
CREATE VIEW dbo.MyCursorView
AS
SELECT TOP(100 PERCENT) *
FROM dbo.CursorView
SELECT TOP(100 PERCENT) *
FIROM dbo.SomeTable
ORDER BY column1 DESC
|
Query optimiser は TOP/ORDER BY を無視します。
ビューを参照するクエリを処理している間、ビュー定義からのクエリは展開され、メイン クエリのコンテキストで実装されます。
ITVF (Inline Table Valued Functions)
ITVF は、入力パラメーターをサポートする再利用可能なテーブル式です。
CTE (Common Table Expressions)
共通テーブル式は派生テーブルと似ていますが、いくつかの重要な利点があります。 曖昧さを避けるため (TSQL では WITH キーワードを他の目的 (WITH ENCRYPTION など) にも使用します)、CTE の WITH 節の前の文は半列で終了させなければなりません (MUST)。 これは、WITH 節がバッチ内の最初のステートメント(VIEW/ITVF 定義など)の場合は必要ありません。
NOTE: セミコラムは ANSI 標準でサポートされており、TSQL プログラミング手法の一部として使用することが強く推奨されています。)
再帰的 CTE の要素
- アンカー・メンバー – 問い合わせ定義のうち、
- 有効な関係結果テーブルを返すもの
- 問い合わせの実行開始時に 1 回のみ実行され、最初の再帰的メンバー定義の前に常に配置されます
- 最後のアンカー・メンバーは UNION ALL 演算子が続いている必要があります。 この演算子は、最後のアンカー・メンバーと最初の再帰的メンバー
- UNION ALLマルチセット演算子を結合します。 この演算子は、
- Recursive member(s) –
- returns a valid relational result table
- has reference to the CTE name を持つクエリ定義を操作します。 CTE 名への参照は、論理的に一連の実行における前の結果セットを表します。つまり、一連の実行における最初の「前の」結果セットは、アンカー・メンバーが返した結果です。
- CTE Invocation – recursion
- を呼び出す最後の文 – MAXRECURSION オプションによりデータベース・システムが無限ループを回避できます。 これはオプションの要素です。
終了チェック
CTE の recursive メンバーには明示的な再帰終了チェックがありません。
多くのプログラミング言語では、自分自身を呼び出すメソッドを設計できます – 再帰式メソッド。 すべての再帰的なメソッドは、特定の条件が満たされたときに終了する必要があります。 これが明示的な再帰終了です。 これを明示的再帰終了といい、この時点からメソッドは値を返すようになる。
CTE の再帰メンバ終了チェックは暗黙的で、前の CTE 実行から行が返されないと再帰が停止することを意味します。 以下のコードは、再帰的な関数 (メソッド) 呼び出しを使用して整数の階乗を計算します。
Complete console program code can be found here.
MAXRECURSION
前述のように、再帰的 CTE およびあらゆる再帰的操作は、正しく設計しなければ無限ループを引き起こす場合があります。 この状況は、データベースのパフォーマンスに悪影響を与える可能性があります。 Sql Server エンジンには、無限実行を許可しないフェールセーフ機構があります。
デフォルトでは、再帰的メンバーが呼び出される回数は 100 に制限されています (これは、一度限りのアンカー実行はカウントされません)。 再帰的メンバの 101 回目の実行でコードは失敗します。
Msg 530, Level 16, State 1, Line xxx
The statement terminated.
Recursions の数は MAXRECURSION n クエリ・オプションで管理されます。 このオプションは、デフォルトの最大許容再帰回数をオーバーライドすることができます。 パラメータ(n)は再帰レベルを表す。 0<=n <=32767
Important note:: MAXRECURSION 0 – 再帰の制限を無効にする!
Figure 1 に、再帰的 CTE とその要素の例を示します

Figure 1, Recursive CTE elements
宣言的再帰は従来の命令的再帰とはかなり異なります。 コード構造の違いの他に、明示的な終了チェックと暗黙的な終了チェックの違いも確認できます。 CalculateFactorial の例では、明示的な終了ポイントは条件によって明確に定義されています。 ON e.MgrId = c.EmpId. テーブル操作の結果は、再帰回数を決定します。 これは、次のセクションで詳しく説明します。
再帰的な CTE を使用して Employee 階層を解決する
再帰的な CTE を使用できるシナリオは数多くあります(要素を分離する場合など)。
Employee ツリー階層は、再帰的 CTE を使用して解決できる階層的問題の典型的な例です。 次のビジネスルールが適用されます。
- 従業員は一意のID、EmpId
- を持つ必要があります。 EmpId列の主キー制約
- 従業員は、0または1のマネージャによって管理することができます
- 。 PK on EmpId, FK on MgrId and NULLable MgrId column
- A manager can manage one or more employees.
- enforced by: EmpIdのPK、MgrIdのFK、NULLable MgrId column。 MgrIdカラムの外部キー制約(自己参照)
- A manager cannot manage himself.
- enforced by: MgrId列
上のCHECK制約
ツリー階層は、dbo.Employeesというテーブルで実装されています。 スクリプトはこちら

Figure 2, Employees table
質問に答えることで、再帰的CTEがどのように動作するかを紹介しましょう。 図2の階層ツリーから、マネージャー(EmpId = 3)は、EmpId=7、EmpId=8、EmpId=9を直接管理し、EmpId=10、EmpId=11、EmpId=12を間接管理することが明確にわかります。

Figure 3, EmpId=3 direct and indirect subordinates
So, how did we get the final result.
The recursive part in the current iteration always references its previous result from the previous iteration.This is a result in the current iteration, the recursive part in the previous iteration. その結果は、cte1 (INNER JOIN の右側のテーブル) と呼ばれるテーブル式 (または仮想テーブル) です。 見ての通り、cte1にはアンカー部分も含まれています。 最初の実行(最初の反復)では、再帰的な部分は前の反復がないため、前の結果を参照することができません。 このため、最初の反復処理では、アンカー部のみが実行され、全処理中一度だけ実行される。 アンカー部のクエリ結果セットは、2回目の反復で再帰部に前の結果を与える。 アンカーはフライホイールとして機能します。
最終結果は、アンカー結果 + 反復1結果 + 反復2結果 …
論理実行シーケンス
テストクエリは、次の論理シーケンスに従って実行されます。 アンカー クエリが実行され、cte1 という仮想テーブルが返されます。 再帰的な部分は前の結果を持たないので、空のテーブルを返します。  Figure 4, cte1 value after 1st iteration
Figure 4, cte1 value after 1st iteration
 図 5、2 回目の反復後の cte1 値
図 5、2 回目の反復後の cte1 値 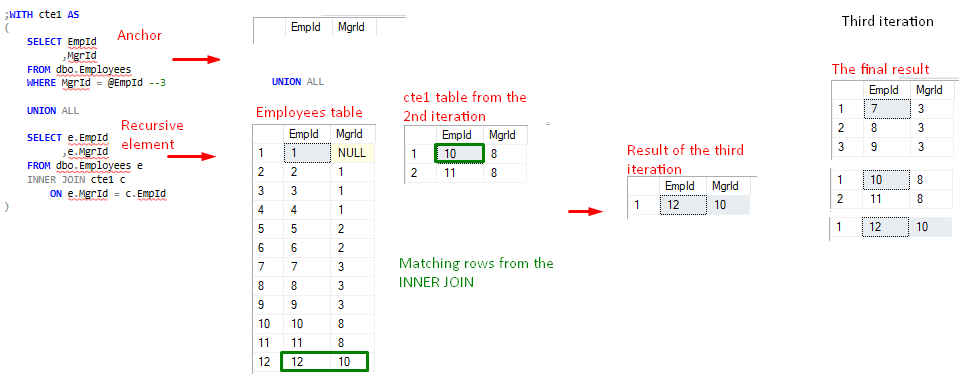
図6、3回目の反復後のcte1値
最後のcte1の結果は空の結果セットなので、4回目の反復(または3回目の再帰)は「キャンセル」され、処理は正常に終了します。

図7、最後の反復
3回目の再帰の論理的キャンセル(空の結果セットを生成した最後の再帰はカウントされない)は、次の再帰的CTE実行プラン解析セクションでより明らかになります。OPTION(MAXRECURSION 2)問い合わせオプションを問い合わせの最後に追加し、許可される再帰の数を2に制限することができます。この問い合わせは正しい結果を生成し、このタスクに必要な再帰が2つであることを証明します。注:物理的な実行の観点から、結果セットは徐々に(行がバブルアップするにつれて)ネットワークバッファに送信され、クライアントアプリケーションに戻されます。 EmpId=7、EmpId=8、EmpId=9の3人が直接の部下で、EmpId=10、EmpId=11、EmpId=12が間接の部下です。
recursive CTE の仕組みを知っていれば、以下の問題を簡単に解決することができます。
- find all the employees who are hierarchically above the EmpId = 10 (code here)
- find EmpId=8 ‘s direct and the second level subordinates (code here)
2番目の例では、再帰の数を制限して階層の深さを制御します。
Anchor要素によって階層の最初のレベル、この場合は直接部下を取得します。 その後、各再帰は最初のレベルから階層を1つ下に移動します。 この例では、出発点は EmpId=8 およびその直属の部下です。 最初の再帰は、EmpId=8 の 2 番目のレベルの部下が「住んでいる」階層をさらに 1 つ下に移動します。
循環参照問題
階層の興味深い点の 1 つは、階層のメンバーが閉ループを形成し、階層内の最後の要素が最初の要素を参照できるようになることです。
このような場合、先に説明した INNER JOIN 操作のような暗黙の終了ポイントは、次の再帰を続行するために常に空でない結果セットを返すので、単に機能しないでしょう。 再帰部分は、Sql Server のフェールセーフである MAXRECURSION クエリ オプションに当たるまで回り続けます。
先に設定したテスト環境を使って循環参照の状況を示すには、
- dbo.Employees テーブルから主キーおよび外部キー制約を削除して閉ループシナリオを可能にすることが必要です。
- 循環参照を作成します(EmpId=10 は、間接的なマネージャーである EmpId = 3 を管理します)
- 前の例で使用したテスト クエリを拡張し、閉ループ内の要素の階層を分析できるようにします。 WHERE句の述語(最後の2行)をコメントアウトし、元のdbo.Employeeテーブル
 Figure 8, Detection of circular loops in hierarchies
Figure 8, Detection of circular loops in hierarchies拡張クエリの結果は、図3の前の実験で提示した結果とまったく同じです。 出力は以下の列
- pth – 現在の階層をグラフィカルに表現するように拡張されている。 最初は、アンカー部分の中で、単純に最初の部下をMgrId=3、つまり私たちの出発点であるマネージャーに追加しています。 現在、各再帰的要素は前の pth 値を取り、それに次の部下を追加します。
- recLvl – 現在の再帰レベルを表します。 アンカーの実行は、recLvl=0
- isCircRef – 現在の階層(行)に循環参照が存在することを検出する。 recursive 要素の一部として、pth 文字列に以前含まれていた EmpId が存在するかどうかを検索します。例えば、以前のpthが3->8->10のように見え、現在の再帰が” ->3 “を追加した場合、(3->8 >10 ->3) EmpId=3はEmpId=10に対して間接的に上位であるだけではなく、EmpId=10の下位であることを意味します – 私は上司またはあなたの上司、そしてあなたは私の上司という状況ですね😐
dbo.LABEL.NET Frameworkに変更を加えてみましょう。
循環参照を許可するためにPKおよびFK制約を削除し、テーブルに「不良循環参照」を追加します。
拡張テストクエリを実行し、結果を分析します(スクリプトの最後にある以前にコメントした WHERE句の削除を忘れないでください)
デフォルトの MAXRECURSIONで中断される前にスクリプトは100再帰実行を実行します。 AND cte1.recLvl <= 2; これは EmpId=3 の階層を解決するために必要です。図 9 は、閉ループ階層、最大許容再帰回数エラー、および閉ループを示す出力を示しています。

Figure 10, Circular reference detected循環参照スクリプトに関するいくつかの注意点
このスクリプトは、階層内の閉ループを見つける方法についての単なるアイデアです。 WHERE 句を削除して結果を観察してみてください。
私の意見では、このスクリプト (または、スクリプトの類似バージョン) は、トラブルシューティングの目的、または既存の階層に循環参照を作成するのを防ぐものとして実環境で使用することが可能です。 ただし、適切な MAXRECURSION n (n は階層の予想される深さ) によって保護する必要があります。このスクリプトは非リレーショナルで、トラバーサル技法に依存しています。
実行計画分析
このセクションでは、Sql Server のクエリオプティマイザー (QO) が再帰的 CTE を実装する方法について説明します。 QOが実行計画を作成する際に使用する一般的なパターンがあります。 元のテストクエリを実行し、実際の実行計画を含める
テストクエリと同様に、実行計画にはアンカーブランチと再帰的ブランチの2つのブランチがあります。 UNION ALL演算子を実装したConcatenation演算子は、クエリ結果を形成する2つの部分から結果を接続します。
前述の論理的な実行順序と実際の処理の実装を整合させてみましょう。
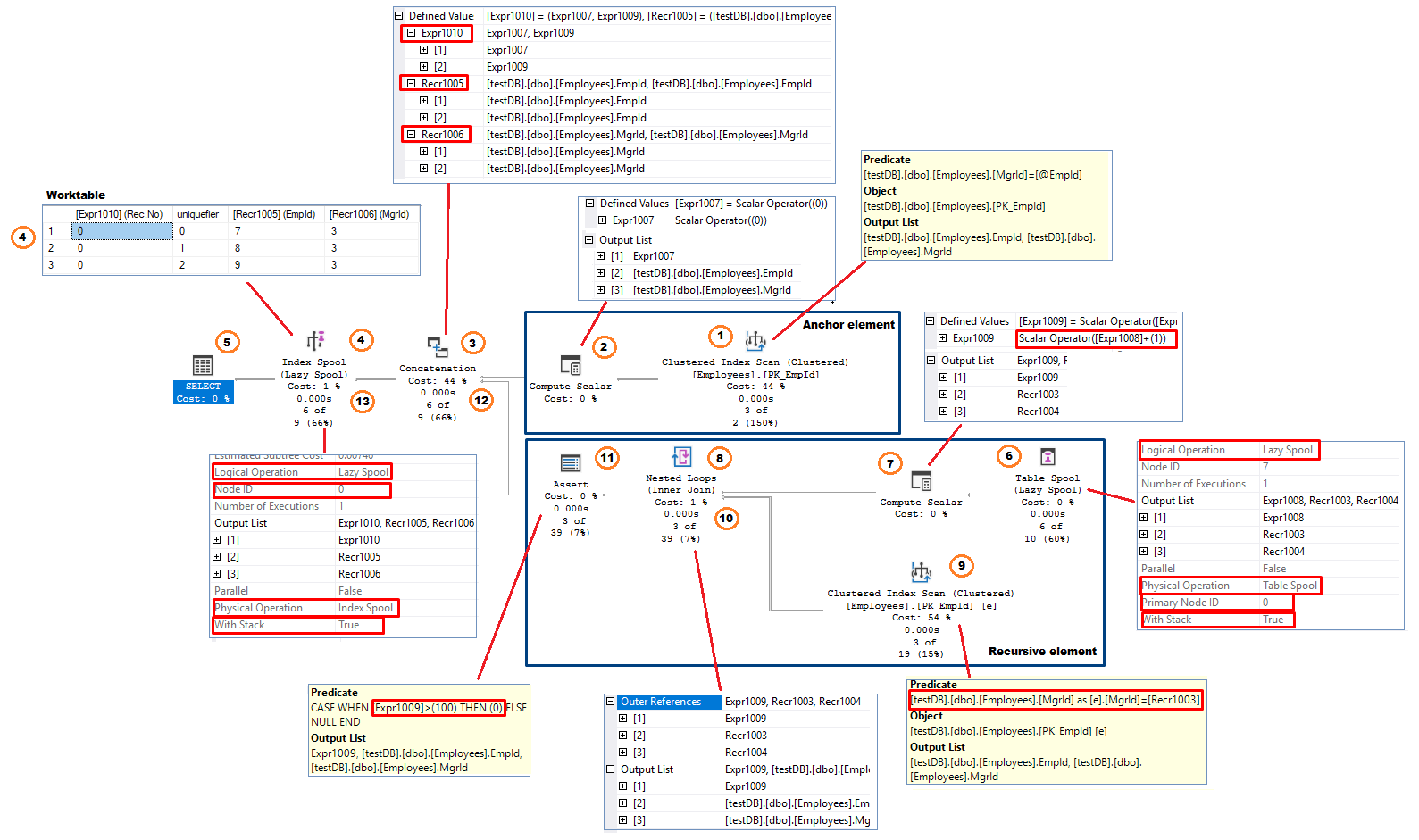
図 11、再帰的 CTE 実行プランデータ フロー (右から左の方向) に従うと、プロセスは次のようになります。
アンカー要素 (1 回のみ実行)
- Clustered Index Scan オペレーター – システムはインデックス スキャンを実行します。 この例では、MgrId = @EmpIdという式を残余述語として適用しています。 選択された行(EmpId と MgrId 列)は、前の演算子に(行ごとに)戻されます。 この例では、追加されたカラムの名前は . これは再帰回数(Number of Recursions)を表します。 列の初期値は 0; =0
- Concatenation – 2つのブランチからの入力を結合します。 最初の反復処理では、この演算子はアンカーブランチからの行のみを受け取ります。 また、出力列の名前も変更されます。 この例では、新しい列名は次のとおりです:
- = または * * recursive branch で割り当てられた recursions の数を保持します。 5067>
- = EmpId(アンカー部)または EmpId(再帰部)
- = MgrId(アンカー部)または MgrId(再帰部)
- Index Spool (Lazy Spool) Concatenation オペレータから受け取った結果をワークテーブルに格納するオペレータです。 プロパティの “Logical Operation “が “Lazy Spool “に設定されています。 これは、この演算子が入力行をすぐに返し、最終結果セット(Eager Spool)を取得するまですべての行を蓄積しないことを意味します。 ワークテーブルは、再帰番号をキー列とするクラスタ化インデックスとして構造化されています。 インデックスキーは一意ではないので、システムはインデックスキーに4バイトの内部一意化子を追加し、インデックス内のすべての行が物理的な実装の観点から一意に識別されるようにします。 インデックス構造を構築するインデックススプールと、インデックススプールによって構築されたワークテーブルに格納された行の消費者として動作するテーブルスプールです。
この段階で、Index Spool演算子はSELECT演算子に行を返し、同じ行をワークテーブルに格納します。 - SELECT演算子はEmpIdとMgrId( , )を返します。 結果からは除外されます。 5067>
インデックススキャン演算子からすべての行を使い切った後、Concatenation演算子は再帰的分岐にコンテキストを切り替えます。 アンカーブランチは処理中に再び実行されることはありません。
Recursive element
- Table Spool (Lazy Spool). この演算子は入力を持たず、(4)で述べたように、Index Spoolが生成し、クラスタ化されたワークテーブルに格納された行の消費者として動作します。 これは、インデックススプールのノードIDを指す “プライマリノード “を0に設定したプロパティを持っています。 これは、2つの演算子の依存関係を強調するものです。 演算子
- は、前の再帰で読み込んだ行を削除します。 これは最初の再帰であり、以前に読み込んだ行は削除されません。
- インデックスキー+uniquifierで降順にソートされた行を読み取ります。 この例では、最初に読み込まれた行はEmpId=9, MgrId=3です。
最後に、演算子は出力列名の名前を変更します。 =, =となり、.
NOTE: テーブルスプール演算子は、INNER JOINの右側のcte1式として観察することができます(図4) - Compute Scalar 演算子は、以前に列.に格納されていた現在の再帰回数に1を追加し、結果は新しい列.に格納されます。 = + 1 = 0 + 1 = 1です。 この演算子は、テーブルスプールからの2つの列(と)と
- Nested Loop(I) 演算子の外部入力(前のステップのCompute Scalar)から行を受け取り、ループの内部入力にある Index Scan演算子の残余述語として、テーブルスプール演算子の EmpId を表します。 内側入力は外側入力からの各行に対して1回実行されます。
- Index Scan演算子は、dbo.Employeesテーブル(EmpIdとMgrIdの2列)から入れ子ループ演算子にすべての適格行を返します。
- Assert 演算子は、エラーメッセージとともにクエリを中断する必要がある条件を確認するために使用されます。 再帰的な CTE の場合、assert 演算子は “MAXRECURSION n” クエリ・オプションを実装しています。 これは、再帰部分が許容される再帰回数 (n) に達したかどうかをチェックします。 現在の再帰回数 (ステップ 7 を参照) が (n) よりも多い場合、演算子は 0 を返し、ランタイム・エラーが発生します。 この例では、Sql ServerはデフォルトのMAXRECURSION値である100を使用しています。 この式は次のようになります。 CASE WHEN > 100 THEN 0 ELSE NULL MAXRECURSION 0 を追加してフェイルセーフを除外することにした場合、アサート演算子はプランに含まれません。 今回は再帰部分のみから入力を受け、ステップ3で示したように列/行を出力します。
- Index Spool (Lazy Spool) は連結演算子の出力をワークテーブルに追加し、それをSELECT演算子に渡します。 この時点で、作業テーブルには、アンカー実行による3行と最初の再帰による1行の合計4行が含まれています。 ワークテーブルのクラスタ化インデックス構造に従って、新しい行はワークテーブルの最後に格納される
-
ここで、処理はステップ6から再開される。 テーブルスプール演算子は、以前に読み込んだ行(最初の3行)を作業テーブルから削除し、最後に挿入された行(4行目)を読み込む。
結論
CTE(Common table expressions) は Sql Server で利用できるテーブル式の一種である。 CTEは独立したテーブル式で、メインクエリの中で1回以上名前を付けて参照することができます。
CTEの最も重要な用途の1つは、再帰的なクエリを記述することです。 再帰的なCTEは、アンカー・クエリ、UNION ALLマルチセット・オペレータ、再帰的メンバ、再帰を呼び出す文という、常に同じ構造に従っています。 例えば、宣言的な再帰の終了チェックは暗黙的な性質を持っており、前の CTE で返された行がない場合に再帰処理を停止します。
コメントを残す