オートエンコーダーとは
On 11月 11, 2021 by adminオートエンコーダーとその様々なアプリケーションについて優しく紹介します。 また、これらのチュートリアルはtf.kerasを使用しています。TensorFlowの高レベルのPython APIで、深層学習モデルの構築と学習を行います。
常常見到オートエンコーダー的變形以及應用,打算花幾篇的時間好好的研究一下,順便練習 Tensorflow.keras 的 API 使用。
- Autoencoderとは
- Autoencoderの種類
- Autoencoderの応用
- 実装方法
- Great examples
- Conclusion
難易度:★☆☆☆
後記:由於Tensorflow 2.0 alpha 已持 3/8號釋出,此篇是在1月底完成的,故に。大家以直接使用安裝使用看,但需要更新至相對的CUDA10。
Autoencoderとは?
首先,什麼是Autoencoder呢? 不囉唆,先看圖吧!?
オートエンコーダー本来のコンセプトは非常にシンプルで、入力データを投入し、ニューラルネットワークによって入力データと全く同じデータを得ることです。エンコーダーは、まず入力データを取り込み、より小さな次元のベクトルZに圧縮し、デコーダーに入力してZを元のサイズに戻す。簡単そうに聞こえますが、そんなに簡単なことなのか、詳しく見てみましょう。

エンコーダー:
エンコーダーは、元の入力データを低次元のベクトルCに圧縮する役割を果たします。このC、通常はコード、潜在ベクトル、特徴ベクトルと呼びますが、私はCが隠れた特徴を表すことから潜在空間と呼ぶのに慣れています。Encoderは元のデータを意味のある低次元ベクトルに圧縮することができます。つまり、Autoencoderには次元削減機能があり、隠れ層には非線形変換活性化機能があるので、EncoderはPCAの強力版みたいなものです。dimension reduction!
Decoder:
Decoderが行うのは、潜在空間をできるだけ入力データに戻すことであり、特徴ベクトルを低次元空間から高次元空間へ変換することである。
では、Autoencoder がどの程度うまく機能しているかをどのように測定しているのでしょうか? 単純に、2つの元の入力データと再構成されたデータの類似性を比較することである。したがって、我々の損失関数は次のように書くことができる……。
損失関数:

の差を最小化したいからです。AutoEncoderは、通常のニューラルネットワークと同様に、バックプロパゲーションを用いて重みを更新して学習します。は重みを更新する。
結論から言うと、Autoencoderは……。
1.非常に一般的なモデルアーキテクチャで、教師なし学習にもよく使われる
2.非線形の次元削減手法として使える
3.データ表現の学習に使える、代表的な特徴変換
この時点で、Autoencoderがどのようなものか理解するのは簡単でしょう。アーキテクチャは非常にシンプルなので、その変換を見てみましょう
Types of Autoencoder
AutoEncoderの基本原理を説明した後は、Autoencoderの広範囲な使い方をご覧いただくために、拡張した高度な使い方を見ていきましょう!AutoEncoderの基本的な使い方は以下のとおりです。
2-1. Unet:
Unetは画像分割の手段の一つとして使用でき、UnetアーキテクチャはAutoencoderの変種と見ることができる。

2-2. Recursive Autoencoders:
これは新しい入力テキストと他の入力からの潜在空間を結合するネットワークで、このネットワークの目的は感情分類である。これは、入力されたままの疎なテキストを抽出し、重要な潜在空間を見つけ出すオートエンコーダの変形ともいえる。

2.-Seq2Seq:
Sequence to Sequenceは、以前から非常に人気のある生成モデルです。 RNN型が不定形のペアを扱えないというジレンマを見事に解決し、チャットボットやテキスト生成などのテーマで良い成績を残しています。これは一種のオートエンコーダー・アーキテクチャと見ることもできる。

オートエンコーダの応用
Autoencoderの様々なバリエーションを見た後は、Autoencoderの他の使い道を見てみましょう!
3-1. モデルの事前学習済み重み
Autoencoder は重みの事前学習にも使用でき、これはモデルがより良い開始値を見つけることを意味します。例えば、ターゲットなどのモデルを完成させたい場合、隠れ層は:なので、最初はオートエンコーダの概念を使って784次元を入力し、真ん中の潜在空間は1000次元で、まず事前学習を行うので、この1000次元はよく入力を保持することができます。そして、元の出力を削除して、2層目を追加する、という具合です。こうすることで、モデル全体がより良いスタート値を得ることができるのです。
あれっ! もし、784次元の入力を1000個のニューロンで表現するのであれば、ネットワークをもう一度コピーする必要があるのではないでしょうか? 何のためのトレーニングなのか? ですから、このような事前学習では、通常、L1ノルム正則化器を追加して、隠れ層がコピーされないようにするのです。

According to Mr Li Hongyi以前は、プレトレーニングにこのような方法を用いることが多かったのですが、トレーニングスキルの向上により、現在はこのような方法を用いる必要はなくなりました。しかし、ラベルデータはほとんどないが、ラベルのないデータが大量にある場合、Autoencoder自体が教師なし学習法なので、この方法で重み事前学習を行うことができます。まずラベルのないデータで重み事前学習を行い、次にラベルのないデータを使って重み事前学習を行います。ラベルのないデータでまず重みのプリトレインを行い、ラベルのあるデータで重みの微調整を行うことで、良いモデルを得ることができるのです。詳しくは、李さんの動画をご覧ください。とてもよくわかりますよ。
3-2. 画像分割
先ほど見たUnetモデルですが、基本的に台湾の製造業で最も多い欠陥検出の問題ですので、もう一度見てみましょう。
まず、出力となる入力データにラベルを付ける必要があります。 やることは、ネットワークを構築し、元の画像(左:歯のレントゲン写真)を入力し、出力(右:歯の構造分類)を生成することです。この場合、エンコーダ&デコーダは、グラフィカルな判断力の強いコンボリューション層となり、意味のある特徴を抽出し、デコーダでデコンボリューションバックしてセグメンテーション結果を得ることになります。

3-3. Video to Text
このような画像キャプションの問題では、入力データが写真の束で、出力が写真を説明するテキストであるsequence to sequenceモデルを使う。sequence to sequenceモデルは、LSTM+Conv netをエンコーダ<7428>デコーダとして用い、CNNカーネルを用いて画像に必要な潜在空間を抽出し、連続した動作<7428>を記述することが可能である。が、この作業はとても大変なので、興味のある方は試してみてください

3-4.画像検索
画像検索 画像を入力して、最も近いものを探そうということですが、ピクセル単位で比較すると、実に簡単でAutoencoderを使って、まず画像を潜像空間に圧縮し、その潜像空間上で類似度を計算すれば、より良い結果が得られるでしょう。潜在空間の各次元は特定の特徴を表す可能性があるため、結果はより良いものになります。潜在空間上で距離を計算すれば、類似画像を見つけるのは合理的である。特に、ラベリングデータを使わない教師なし学習の方法として最適でしょう
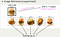
以下略Deep Learningの神様として有名なGeorey E. Hintonの論文では、左上に検索したいグラフが表示され、他はすべてオートエンコーダーが非常に似ていると思うグラフです。7133>

Content-Based画像検索
3-5. 異常値検出
良い画像が見つからないので、この画像を使うことにしました笑
異常値検出も製造業の超常識なので、この問題もオートエンコーダーで試すことができます。Autoencoderで試せる!まず、実際の異常の発生についてですが、異常は通常、機械の異常信号、急激な温度上昇・・・・・・など、ごくまれにしか発生しません。これが月に1回(それ以上ならマシンを強制的に引退させるべき)。 10秒ごとにデータを集めるとすると、毎月26万個のデータが集まるが、異常があるのは1期間だけで、実は非常に偏ったデータ量である。
だから、この状況に対応するためには、結局のところ最大のデータ量であるオリジナルデータを取りに行くのが一番なんだ!良いデータを取って良いオートエンコーダーを学習させることができれば、異常が入れば当然、再構成されたグラフィックは壊れるわけです。こうして、オートエンコーダーを使って異常を見つけるという発想が生まれました

実装
ここでは、Mnistをおもちゃの例として、Tensorflow.kerasの高レベルAPIを使ってAutoencoderを実装します!tf.kerasの新しいパッケージがまもなくリリースされるので、ファイル内のModelサブクラス化メソッドを使って練習しています。
4-1. モデルの作成 – Vallina_AE:
まず、tensorflowをインポートします!7133>
tf.kerasの使い方は、tf.kerasと入力するだけと、とても簡単です!(何言ってるかわからない笑)
Load data & model preprocess
まずtf.keras.datasetからMnistデータを取り出し、少し前処理
を行います。Nomalize: 値を0から1の間に圧縮し、学習が収束しやすくなる
Binarization: より目立つ部分を強調し、学習がより良い結果をもたらすようになる。
Create a Model – Vallina_AE:
これはTensorflow Documentが提供するモデルを作成するためのメソッドです。より複雑になります。
これまで学んだことは、__init __の場所でレイヤーを作成し、呼び出しの中でフォワードパスを定義することです。
そこで、エンコーダ&デコーダを作るために2つの逐次モデルを使います。2つは対称構造で、エンコーダは入力データを運ぶ役割をする入力層に接続され、その後3つの密な層に接続されます。デコーダも同じです。
再び呼び出しの下、エンコーダ&デコーダを連結する必要があり、まずself.encoderの出力として潜在空間を定義します。の空間をself.encoderの出力とし、デコーダを通した結果としての再構成を行う。次にtf.keras.Model()を使って、__init__で定義した2つのモデルを接続する。AE_model = tf.keras.Model(inputs = self.encoder.input, outputs = reconstruction)では、エンコーダーの入力をinput、デコーダーの出力をoutputと指定し、それで完了です。そして、AE_modelを返せば完了です。
Model Compile & training
Kerasがモデルをトレーニングする前に、トレーニングに落とし込む前に、コンパイルする必要があります。コンパイルでは、使用するオプティマイザと計算する損失を指定します。
トレーニングでは、VallinaAE.fitを使ってデータを投入しますが、自分自身を復元することを忘れないでください、したがってXとYは同じデータを投入する必要があります。
100エポックの学習結果を見てみると、再構成結果は思ったほど良くなさそうですね。

4-2. モデルの作成- Conv_AE:
名前の通り、コンボリューション層を隠れ層として使い、再構築できる特徴を学習させることができます。
モデルを変更した後、改善されているかどうか、結果を見てみましょう。

Reconstructionの方が10エポック程度の学習で結果が良くなったようです。
4-3.モデルの作成 – denoise_AE:
また、オートエンコーダーはノイズ除去にも使えるので、ここでは
まず、元の画像にノイズを加えます。 ノイズを加える論理は、元のピクセルに単純なシフトを行い、それから乱数を加えることです。画像の前処理部分は、クリップが0より小さい場合は0、1より大きい場合は1とするだけで、以下のように、クリップの画像処理後は、画像がより鮮明になり、目立つ部分がより見やすくなる。これにより、Autoencoderを投入すると、より良い結果が得られます。

とモデル本体と Conv_AE には差がない。フィット時に元のnoise_dataを元の入力データに戻すために
denoise_AE.fit(train_images_noise, train_images, epochs=100, batch_size=128, shuffle=True)
に変更しなければならない以外はモデル自体に違いはない
このように、Mnistでは、シンプルなオートエンコーダーで非常に素早いノイズ除去効果を得ることができます。
Great examples
もっと知りたい人には良い資料です
- Building Autoencoders in Keras autoencoder シリーズはわかりやすく書かれています。
- Tensorflow 2.0公式ドキュメントのチュートリアル、何か非常に完全な、ちょうど(少なくとも私はXDを引っ張る)
3を見てかなり多くの時間を過ごすために、少し難しい書く。 深い学習のLi Hongyi先生も非常にお勧めですが、非常に明確かつ簡単に理解する、非話します。
まとめ
この記事で、オートエンコーダの基本概念、オートエンコーダのいくつかのバリエーション、オートエンコーダのアプリケーションをすばやく確立してください。シナリオを作成します。4310>
次の数回の記事では、生成モデルから始めて、オートエンコーダの概念、VAE、GAN、そしてその途中でさらなる拡張と形態に拡張していく予定です。
記事を気に入っていただけたら、励みとしてもう少し拍手(一回だけでなく)をクリックしてください!。
この記事の全コードを読む:https://github.com/EvanstsaiTW/Generative_models/blob/master/AE_01_keras.ipynb
。
コメントを残す