Come usare Tesseract su Windows
Il Gennaio 14, 2022 da admin
Tesseract è un software di riconoscimento ottico dei caratteri sviluppato da Google. È uno strumento OCR open source. Ci sono molte versioni di Tesseract, ma noi useremo la versione 4.0.
Nella versione 4, Tesseract ha implementato un motore di riconoscimento basato sulla Long Short Term Memory (LSTM). LSTM è un tipo di rete neurale ricorrente (RNN). Il riconoscimento basato su LSTM funziona molto più efficacemente dei vecchi processi di riconoscimento (basati su CNN).
Grazie a tesseract, saremo in grado di salvare il contenuto delle nostre immagini come file di testo.
Installazione
L’installazione dipende dal vostro sistema operativo. Ora passiamo alle finestre. Per prima cosa, scarichiamo e installiamo Tesseract attraverso questo link. (Scarica un file exe.) Impostiamo il file exe facilmente.
Dopo di che dovremmo aggiungere un PATH alle variabili di sistema di windows. In realtà è un passo facile. Per prima cosa troviamo e copiamo la cartella principale dell’installazione di Tesseract. Dovrebbe essere così :
C:\Program Files\Tesseract-OCR
E poi nella barra di ricerca di windows Impostazioni di sistema avanzate
Impostazioni di sistema avanzate > Avanzate > Variabili d’ambiente > PATH > Nuovo
Incolliamo il percorso di origine che abbiamo copiato e salviamo questa configurazione. Dopo questo passo il computer deve essere riavviato per applicare le configurazioni.
L’installazione di tesseract è completata. È possibile confermare l’installazione dalla riga di comando. Quando eseguiamo il comando tesseract sulla linea di comando, dovrebbe darci informazioni sul programma.
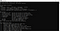
Ora possiamo passare alla parte python. Per usare tesseract su python, dovremmo scaricare la libreria pytesseract. Questa libreria può essere scaricata tramite pip nell’ambiente che state usando.
pip install pytesseract
Ora il tesseract è pronto per l’uso!
Codifica
E’ molto semplice usare tesseract. La parte difficile è l’ottimizzazione delle impostazioni.
Perché se vuoi fare un OCR di successo, devi stare attento alla fase di elaborazione delle immagini e alle impostazioni OCR.
Applichiamo l’OCR alla ricevuta.

Importazione delle librerie
import pytesseract
from PIL import Image
import cv2
import numpy as np
Impostazione del valore DPI dell’immagine
I punti per pollice (DPI, o dpi) è una misura della densità dei punti dello scanner video o immagine. Il valore DPI è una cosa importante per eseguire l’OCR. Perché se il valore DPI è inferiore a 300, può ridurre il successo dell’OCR.
file_path= 'receipt.jpg'
im = Image.open(file_path)
im.save('ocr.png', dpi=(300, 300))
Applicazione di alcune tecniche per rendere l’immagine più pulita
In primo luogo scaliamo la nostra immagine con x2. Se i caratteri sono piccoli, allora abbiamo bisogno di scalare l’immagine per riconoscerla. Dopo di che applichiamo una semplice tecnica di soglia. La sua soglia binaria. Prima si dovrebbe provare con il valore 127, dopo di che si possono provare diverse variabili. La soglia cambia il pixel con il nero se il valore del pixel supera il valore di soglia. Se facciamo l’immagine in scala di grigi, ci darà un’immagine in bianco e nero.
Ci sono diverse tecniche di soglia. Puoi controllare il sito di origine con questo link.

Eseguire Tesseract
Ora possiamo eseguire Tesseract. Ha una funzione image_to_string(). Ci dà una stringa come output.
text = pytesseract.image_to_string(treshold)
Salvataggio dell’output
Possiamo salvare l’output con il seguente codice.
with open("Output.txt", "w",5 ,"utf-8") as text_file:
text_file.write(text)
L’output dell’OCR è il seguente:
Il risultato è molto positivo. Se si desidera un successo maggiore, si possono applicare diverse operazioni all’immagine.
Lascia un commento