Come funziona il web
Il Ottobre 15, 2021 da adminIl web è ovunque!
Lo usiamo più di quanto non abbiamo mai fatto prima – anche in molti posti dove potresti non vederlo. Perché “il web” è più di semplici siti web che visiti inserendo un URL nel tuo browser.
Non importa se controlli le tue e-mail sul tuo cellulare o se stai inviando un tweet – stai usando internet (cioè “il web”).
Come funziona tutto questo? Quali tecnologie sono coinvolte e cosa devi imparare (e in che misura) se vuoi diventare uno sviluppatore web?
In questo articolo e nel video (vedi sopra), non mi immergerò in tutti i dettagli tecnici. Questo vuole essere una buona panoramica delle funzionalità web.

CSS – La guida completa
Entra in questo corso completo di oltre 20 ore per padroneggiare i CSS e imparare a creare bellissimi siti web.

JavaScript – La Guida Completa
Impara JavaScript da zero per costruire siti web altamente interattivi e dinamici in questo corso pratico!
# How Websites Work
Iniziamo con il modo più ovvio di usare internet: Si visita un sito web come academind.com.
Nel momento in cui inserisci questo indirizzo nel tuo browser e premi INVIO, accadono molte cose diverse:
- L’URL viene risolto
- Una richiesta viene inviata al server del sito web
- La risposta del server viene analizzata
- La pagina viene resa e visualizzata

In realtà, ogni singolo passo potrebbe essere suddiviso in molteplici altri passi, ma per una buona panoramica di come funziona il tutto, è qualcosa che possiamo ignorare qui. Diamo un’occhiata a tutti e quattro i passi.
Step 1 – URL Gets Resolved
Il codice del sito web non è ovviamente memorizzato sulla tua macchina e quindi deve essere recuperato da un altro computer dove è memorizzato. Questo “altro computer” è chiamato “server”. Perché serve a qualche scopo, nel nostro caso, serve il sito web.
Si entra in “academind.com” (che si chiama “un dominio”) ma in realtà, il server che ospita il codice sorgente di un sito web, è identificato tramite indirizzi IP (= Internet Protocol). Il browser invia una “richiesta” (vedi passo 2) al server con l’indirizzo IP che hai inserito (indirettamente – ovviamente hai inserito “academind.com”).
In realtà, spesso si inserisce anche "academind.com/learn" o qualcosa del genere. "academind.com" è il dominio, "/learn" è il cosiddetto percorso. Insieme, costituiscono l'”URL” (“Uniform Resource Locator”).
Inoltre, puoi visitare la maggior parte dei siti web tramite "www.academind.com" o solo "academind.com". Tecnicamente, "www" è un sottodominio, ma la maggior parte dei siti web semplicemente reindirizza il traffico a "www" alla pagina principale.
Un indirizzo IP in genere assomiglia a questo: 172.56.180.5 (sebbene ci sia anche una forma più “moderna” chiamata IPv6 – ma ignoriamola per ora). Puoi imparare di più sugli indirizzi IP su Wikipedia.
Come viene tradotto il dominio “academind.com” nel suo indirizzo IP?
C’è un tipo speciale di server là fuori in internet – non solo uno ma molti server di quel tipo. Un cosiddetto “name server” o “server DNS” (dove DNS = “Domain Name System”).
Il lavoro di questi server DNS è quello di tradurre i domini in indirizzi IP. Puoi immaginare questi server come enormi dizionari che immagazzinano tabelle di traduzione: Dominio => indirizzo IP.
Quando si inserisce “academind.com”, il browser recupera quindi prima l’indirizzo IP da un tale server DNS.
In caso vi stiate chiedendo: Il browser conosce a memoria gli indirizzi di questi server di dominio, sono programmati nel browser per così dire.
Una volta che l’indirizzo IP è noto, siamo passati alla fase 2.
Step 2 – Request Is Sent
Con l’indirizzo IP risolto, il browser va avanti e fa una richiesta al server con quell’indirizzo IP.
“Una richiesta” non è solo un termine. È davvero una cosa tecnica che avviene dietro le quinte.
Il browser raggruppa un mucchio di informazioni (Qual è l’URL esatto? Che tipo di richiesta deve essere fatta? Dovrebbero essere allegati dei metadati) e invia quel pacchetto di dati all’indirizzo IP.
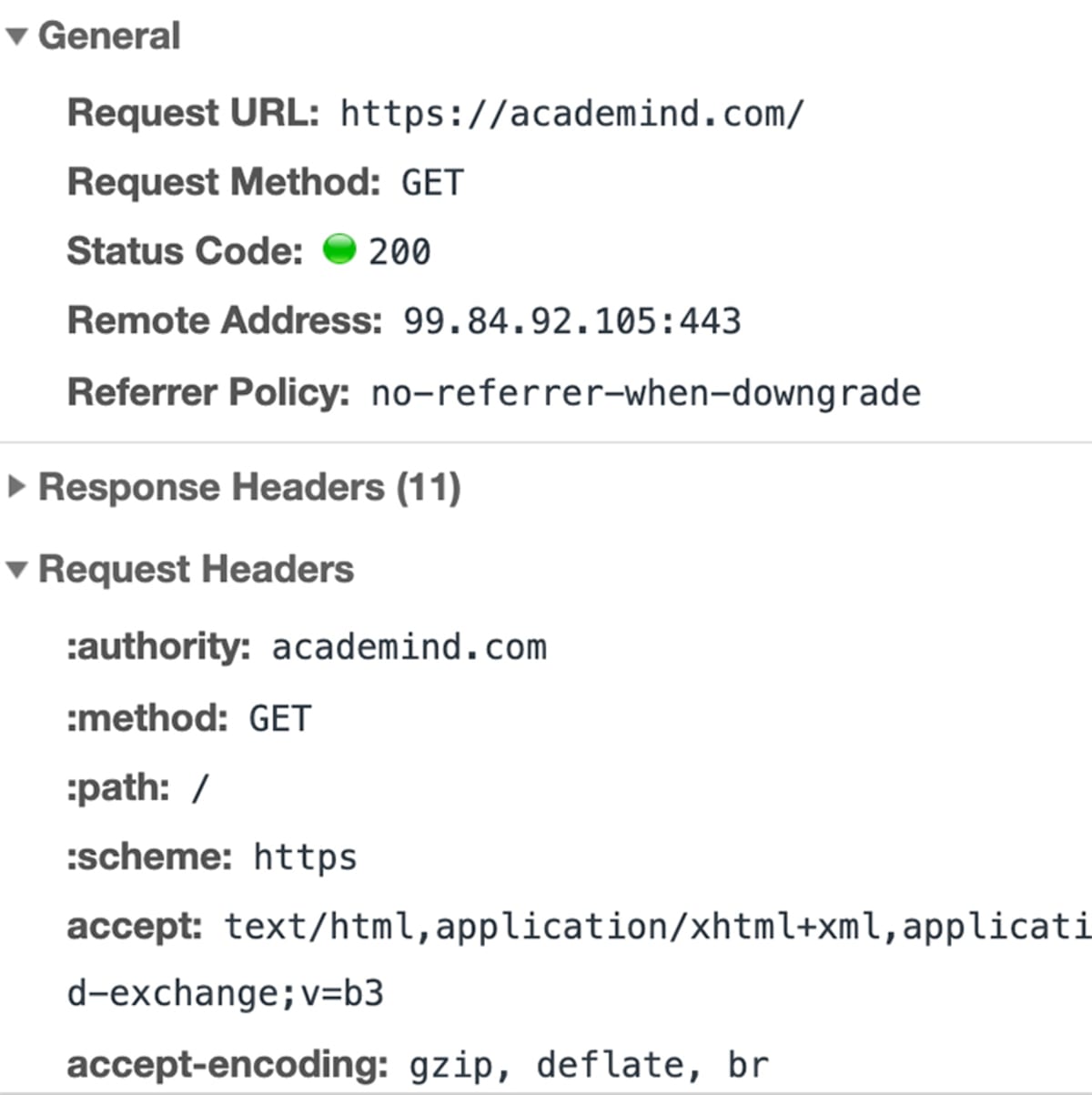
I dati vengono inviati tramite il “Protocollo di Trasferimento Ipertestuale” (noto come “HTTP”) – un protocollo standardizzato che definisce come deve essere una richiesta (e una risposta), quali dati possono essere inclusi (e in quale forma) e come la richiesta sarà inviata. Puoi imparare di più su HTTP qui.
Perché viene usato HTTP, un URL completo in realtà assomiglia a questo: http://academind.com. Il browser lo compila automaticamente per te.
E c’è anche HTTPS – è come HTTP ma criptato. La maggior parte delle pagine moderne (incluso academind.com) lo usano al posto di HTTP. Un URL completo diventa quindi: https://academind.com.
Siccome l’intero processo e il formato sono standardizzati, non ci sono congetture su come quella richiesta deve essere letta dal server.
Il server poi gestisce la richiesta in modo appropriato e restituisce una cosiddetta “risposta”. Di nuovo, una “risposta” è una cosa tecnica e un po’ simile a una “richiesta”. Si potrebbe dire che è fondamentalmente una “richiesta” nella direzione opposta.
Come una richiesta, una risposta può contenere dati, metadati ecc. Quando si richiede una pagina come academind.com, la risposta conterrà il codice necessario per rendere la pagina sullo schermo.
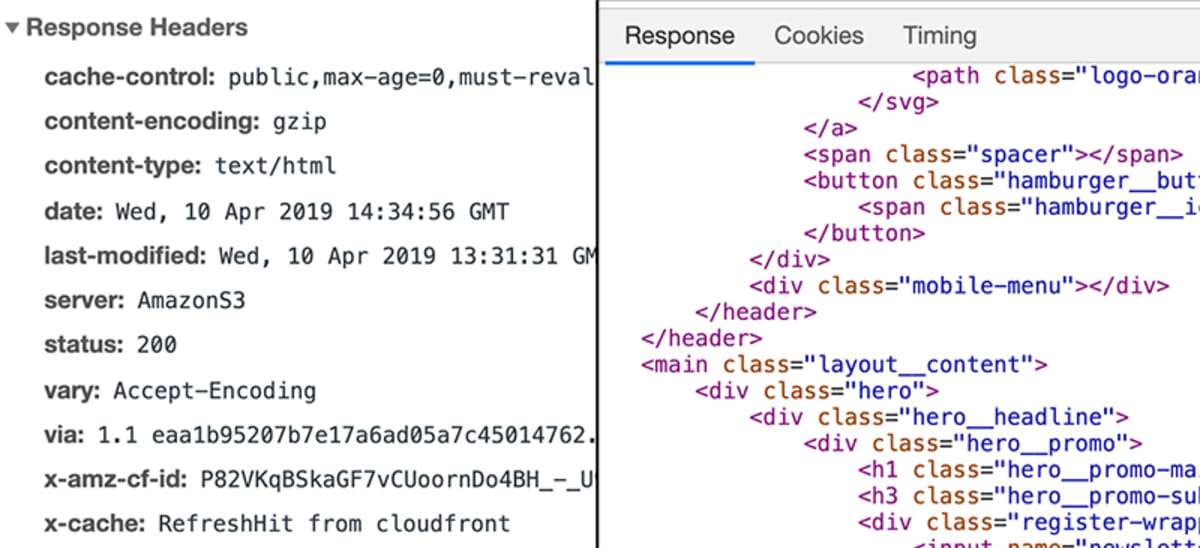
Cosa succede sul server?
Questo è definito dagli sviluppatori web. Alla fine, una risposta deve essere inviata. Quella risposta non deve necessariamente contenere “un sito web”. Può contenere qualsiasi dato – inclusi file o immagini.
Alcuni server sono programmati per generare siti web dinamicamente in base alla richiesta (ad esempio una pagina di profilo che contiene i tuoi dati personali), altri server restituiscono pagine HTML pre-generate (ad esempio una pagina di notizie). Oppure si fanno entrambe le cose – per diverse parti di una pagina web. C’è anche una terza alternativa: Siti web che sono pre-generati ma che cambiano il loro aspetto e i loro dati nel browser.
I diversi tipi di siti web non sono davvero il focus di questo articolo. Se volete saperne di più, guardate questo articolo + video.
Per il nostro caso semplice abbiamo un server che restituisce il codice per visualizzare un sito web. Quindi continuiamo con il passo 3.
Step 3 – Response Is Parsed
Il browser riceve la risposta inviata dal server. Questo da solo non visualizza nulla sullo schermo.
Invece, il passo successivo è che il browser analizza la risposta. Proprio come ha fatto il server con la richiesta. Di nuovo, la standardizzazione imposta da HTTP aiuta naturalmente.
Il browser controlla i dati e i metadati che sono inclusi nella risposta. E in base a questo, decide cosa fare.
Ti sarà capitato di aprire un PDF nel tuo browser. Questo è successo perché la risposta ha informato il browser che i dati non sono un sito web ma un documento PDF. E il browser cerca di scegliere il miglior meccanismo di gestione per ogni tipo di dati che rileva.
Torniamo al nostro scenario del sito web.
In quel caso, la risposta conterrebbe un pezzo specifico di metadati, che dice al browser che i dati della risposta sono di tipo text/html.
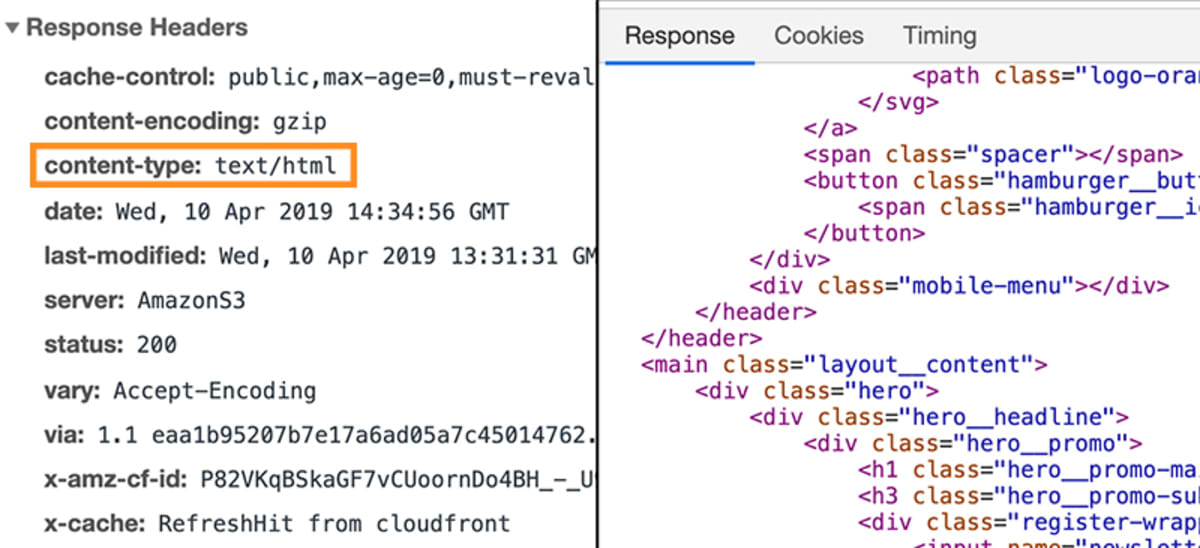
Questo permette al browser di analizzare i dati effettivi allegati alla risposta come codice HTML.
HTML è il “linguaggio di programmazione” principale (tecnicamente, non è un linguaggio di programmazione – non si può scrivere alcuna logica con esso) del web. HTML sta per “Hyper Text Markup Language” e descrive la struttura di una pagina web.
Il codice assomiglia a questo:
<h1>Breaking News!</h1><p>Websites work because browser understand HTML!</p><h1> e <p> sono i cosiddetti “tag HTML” e se vuoi imparare di più su HTML, questa serie è un ottimo posto dove andare.
Ogni tag HTML ha un significato semantico che il browser capisce, perché anche l’HTML è standardizzato. Quindi non ci sono congetture sul significato di un tag <h1>.
Il browser sa come analizzare l’HTML e ora passa semplicemente attraverso l’intera risposta (chiamata anche “il corpo della risposta”) per rendere il sito web.
Fase 4 – La pagina viene visualizzata
Come detto, il browser passa attraverso i dati HTML restituiti dal server e costruisce un sito web basato su quello.
Anche se è importante sapere che l’HTML non include alcuna istruzione riguardo a come dovrebbe essere il sito (cioè come dovrebbe essere stilizzato). In realtà definisce solo la struttura e dice al browser quale contenuto è un titolo, quale contenuto è un’immagine, quale contenuto è un paragrafo ecc. Questo è particolarmente importante per l’accessibilità – i lettori di schermo ottengono tutte le informazioni utili dalla struttura dell’HTML.
Una pagina che include solo l’HTML avrebbe questo aspetto:

Non è così bello, vero?
Ecco perché c’è un’altra importante tecnologia (un altro “linguaggio di programmazione”, che non è veramente un linguaggio di programmazione): CSS (“Cascading Style Sheets”).
CSS consiste nell’aggiungere stile al sito web. Questo viene fatto tramite “regole CSS”:
h1 { color: blue;}Questa regola colorerebbe tutti i tag <h1> di blu.
Regole come questa possono essere aggiunte all’interno del codice HTML, ma tipicamente, sono parte di file .css separati che vengono richiesti separatamente.
Senza entrare troppo nei dettagli, questo ha un’importante implicazione: Un sito web può essere composto da più dei dati della prima risposta che riceviamo.
In pratica, i siti web recuperano molti dati aggiuntivi (tramite richieste e risposte aggiuntive) che vengono avviati una volta arrivata la prima risposta.
Come funziona?
Bene, il codice HTML della prima risposta contiene semplicemente le istruzioni per recuperare altri dati tramite nuove richieste – e il browser capisce queste istruzioni:
<link rel="stylesheet" href="/page-styles.css" />
Ancora una volta, non mi immergerò in ulteriori dettagli qui. Se vuoi saperne di più sui CSS, la nostra Guida Completa ti sarà molto utile!
Insieme ai CSS, il browser è in grado di visualizzare pagine web come questa:

In realtà c’è un altro linguaggio di programmazione coinvolto (questa volta, è davvero un linguaggio di programmazione!): JavaScript.
Non è sempre visibile, ma tutto il contenuto dinamico che si trova su un sito web (ad esempio schede, overlay ecc.) è in realtà possibile solo grazie a JavaScript. Esso permette agli sviluppatori web di definire il codice che viene eseguito nel browser (non sul server), quindi JavaScript può essere usato per cambiare il sito web mentre l’utente lo sta visualizzando.
Come prima, se vuoi saperne di più, controlla le nostre risorse JavaScript, per esempio il nostro corso completo.
Questi sono i quattro passi che sono sempre coinvolti quando inserisci l’indirizzo di una pagina come academind.com e successivamente vedi il contenuto del sito web nel tuo browser.
# Server-side vs Browser-side
Dai quattro passi sopra, hai imparato che possiamo differenziare due “lati” fondamentali quando parliamo del web: Server-side e Browser-side (o: Client-side dato che possiamo accedere a internet anche senza un browser – vedi sotto!).
Se sei interessato a diventare uno sviluppatore web, è importante sapere che si usano diverse tecnologie e linguaggi di programmazione per questi lati.
Lato server
Hai bisogno di linguaggi di programmazione lato server – cioè linguaggi che non funzionano nel browser ma che possono funzionare su un normale computer (un server è alla fine solo un normale computer).
Gli esempi sarebbero:
- Node.js
- PHP
- Python
Importante: con l’eccezione di PHP, puoi usare questi linguaggi di programmazione anche per altri scopi oltre allo sviluppo web.
Mentre Node.js è effettivamente usato principalmente per la programmazione lato server (anche se tecnicamente non è limitato a quello), Python è anche molto popolare per la scienza dei dati e l’apprendimento automatico.
Lato browser
Nel browser, ci sono esattamente tre linguaggi/tecnologie che devi imparare. Ma mentre i linguaggi lato server erano alternativi, questi tre linguaggi lato browser sono tutti obbligatori da conoscere e capire:
- HTML (per la struttura)
- CSS (per lo stile)
- JavaScript (per il contenuto dinamico)
# “Dietro le quinte” Internet
Finora abbiamo parlato di siti web. Cioè il caso in cui si inserisce un URL (ad esempio “academind.com/learn”) nel browser e si ottiene un sito web in cambio.
Ma internet è più di questo. Infatti, lo si usa ogni giorno per molto più di questo!
L’idea di base delle richieste e delle risposte è sempre la stessa. Ma non tutte le risposte sono necessariamente un sito web. E non tutte le richieste vogliono un sito web.
I metadati che sono allegati alle richieste e alle risposte controllano quali dati sono desiderati e restituiti. Naturalmente entrambe le parti coinvolte (cioè client e server) devono supportare le richieste e i dati inviati.
Non puoi richiedere un PDF da "academind.com" per esempio. Si potrebbe inviare una richiesta del genere ma non si otterrebbe un PDF – semplicemente perché non supportiamo questo tipo di dati richiesti per questo specifico URL.
Ma ci sono molti server specializzati nel fornire URL che restituiscono certi pezzi di dati. Tali servizi sono anche chiamati “API” (“Application Programming Interface”).
Per esempio, le applicazioni mobili inviano richieste HTTP “invisibili” a tali API (a specifici URL a loro noti) per ottenere o memorizzare dati. Twitter sta recuperando il feed dei tweet per esempio.
E anche sulle pagine web, tali richieste “invisibili” vengono inviate. Se ti iscrivi alla nostra newsletter (cosa che ovviamente dovresti fare!), non verrà caricata nessuna nuova pagina. Perché i dati vengono scambiati dietro le quinte. Anche se in questo caso il cliente è il browser, la richiesta che viene inviata non vuole nessun sito web in cambio. E l’URL del server che la riceve non offre alcun sito web – invece, il server sa come gestire il tuo indirizzo e-mail.
Potremmo entrare molto più in dettaglio qui, ma questo è già un lungo articolo. Ora dovreste avere una buona comprensione di come funziona il web e quali sono le tecnologie di base coinvolte.
Lascia un commento