Hogyan működik a web
On október 15, 2021 by adminA web mindenütt jelen van!
Mivel többet használjuk, mint valaha – sok olyan helyen is, ahol talán nem is látjuk. Mert a “web” több, mint egyszerű weboldalak, amelyeket a böngészőbe beírva egy URL-t látogatsz meg.
Nem számít, hogy a mobiltelefonodon nézed meg az e-mailjeidet, vagy éppen tweetet küldesz – az internetet (azaz a “webet”) használod.
Hogyan működik mindez? Milyen technológiákról van szó, és mit kell megtanulnod (és milyen mértékben), ha webfejlesztő akarsz lenni?
Ebben a cikkben és a videóban (lásd fentebb) nem fogok minden technikai részletbe belemerülni. Ez egy jó áttekintésnek szánom a webes funkcionalitásról.

CSS – A teljes útmutató
Jelentkezz erre az átfogó, több mint 20 órás tanfolyamra, hogy elsajátítsd a CSS-t és megtanuld, hogyan készíts gyönyörű weboldalakat.

JavaScript – A teljes útmutató
Tanulja meg a JavaScriptet az alapoktól kezdve, hogy rendkívül interaktív és dinamikus weboldalakat készíthessen ebben a gyakorlati kurzusban!
# Hogyan működnek a weboldalak
Kezdjük az internet használatának legnyilvánvalóbb módjával: Meglátogatsz egy olyan weboldalt, mint az academind.com.
Amikor beírja ezt a címet a böngészőjébe, és megnyomja az ENTER billentyűt, egy csomó különböző dolog történik:
- Az URL felbontásra kerül
- A kérés elküldésre kerül a weboldal szerverére
- A szerver válasza elemzésre kerül
- A lap megjelenik és megjelenik

Ténylegesen, minden egyes lépést több másik lépésre is fel lehetne osztani, de ahhoz, hogy jól áttekinthessük, hogyan működik az egész, ezt itt figyelmen kívül hagyhatjuk. Nézzük meg mind a négy lépést.
1. lépés – URL feloldása
A weboldal kódja nyilvánvalóan nem az Ön gépén van tárolva, ezért egy másik számítógépről kell lekérni, ahol tárolják. Ezt a “másik számítógépet” “szervernek” nevezzük. Mivel valamilyen célt szolgál, esetünkben a weboldalt szolgálja ki.
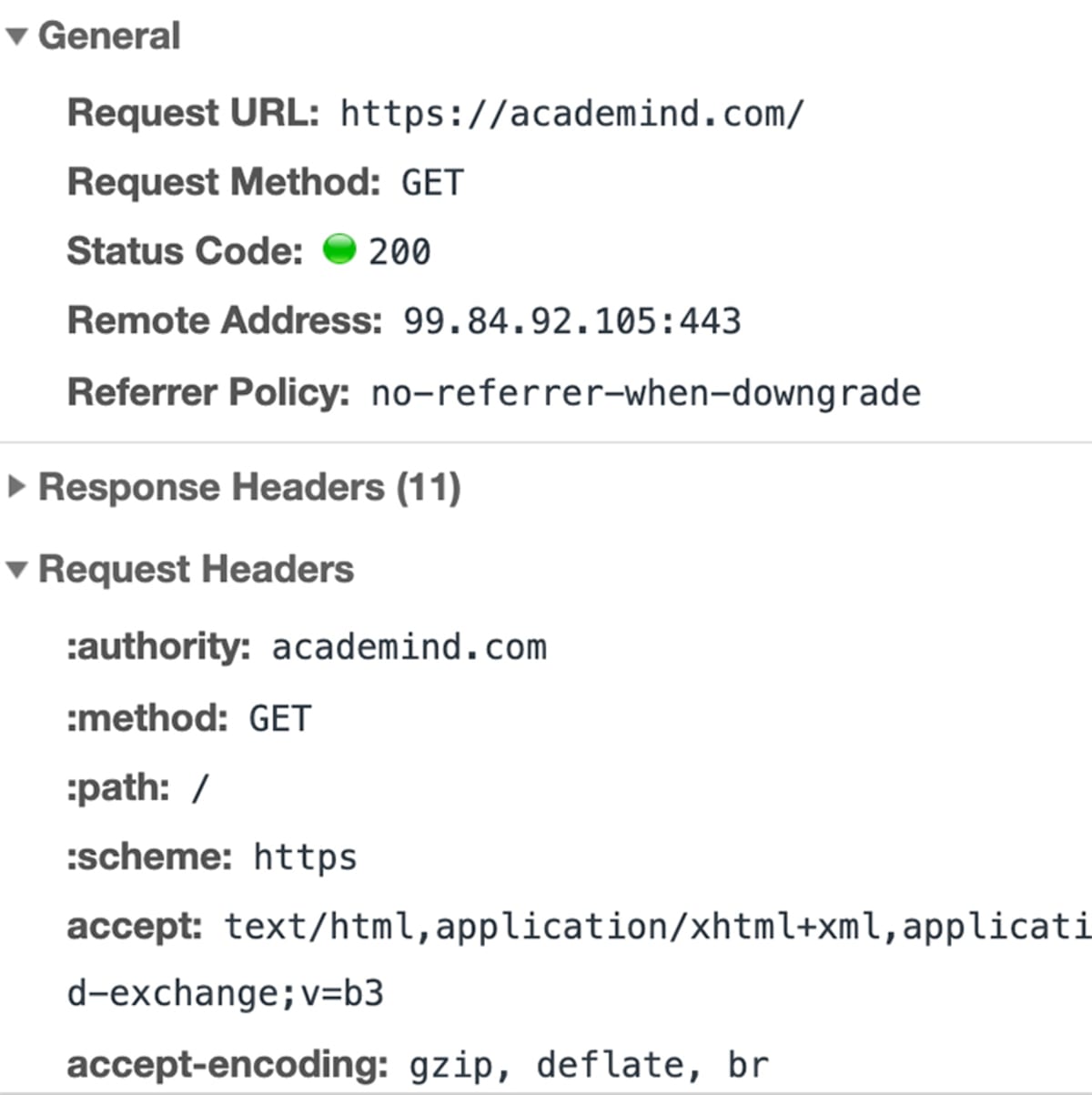
Az “academind.com” beírása. (ezt hívják “domainnek”), de valójában a szervert, amely egy weboldal forráskódját tárolja, IP (= Internet Protocol) címekkel azonosítják. A böngésző “kérést” küld (lásd a 2. lépést) az Ön által megadott IP-címmel rendelkező szervernek (közvetve – Ön természetesen “academind.com”-ot írt be).
A valóságban gyakran beírja a "academind.com/learn" vagy bármi hasonlót is. A "academind.com" a domain, a "/learn" az úgynevezett path. Ezek együtt alkotják az “URL”-t (“Uniform Resource Locator”).
Mellett a legtöbb webhelyet a "www.academind.com" vagy csak a "academind.com" segítségével is meglátogathatod. Technikailag a "www" egy aldomain, de a legtöbb webhely egyszerűen átirányítja a "www"-ra irányuló forgalmat a főoldalra.
Egy IP-cím általában így néz ki: 172.56.180.5 (bár létezik egy “modernebb” forma is, az IPv6 – de ezt most hagyjuk figyelmen kívül). Az IP-címekről többet megtudhat a Wikipédián.
Hogyan fordítják le az “academind.com” tartományt IP-címre?
Az interneten létezik egy különleges típusú szerver – nem is egy, hanem sok ilyen típusú szerver. Egy úgynevezett “névkiszolgáló” vagy “DNS-kiszolgáló” (ahol DNS = “Domain Name System”).
Ezeknek a DNS-kiszolgálóknak az a feladata, hogy a domaineket IP-címekre fordítsák. Ezeket a szervereket úgy képzelhetjük el, mint hatalmas szótárakat, amelyek fordítási táblázatokat tárolnak: Domain => IP-cím.
Amikor beírja, hogy “academind.com”, a böngésző ezért először az IP-címet kéri le egy ilyen DNS-kiszolgálóról.
Ha esetleg kíváncsi lenne: A böngésző kívülről tudja ezeknek a domain-kiszolgálóknak a címét, úgymond be vannak programozva a böngészőbe.
Mihelyt az IP-cím ismert, továbblépünk a 2. lépéshez.
2. lépés – A kérés elküldése
Az IP-cím feloldásával a böngésző továbblép, és kérést küld az adott IP-címmel rendelkező kiszolgálónak.
A “kérés” nem csak egy kifejezés. Ez tényleg egy technikai dolog, ami a színfalak mögött történik.
A böngésző egy csomó információt (Mi a pontos URL? Milyen típusú kérést kell benyújtani? Kell-e metaadatokat csatolni), és elküldi ezt az adatcsomagot az IP-címre.
Az adatokat a “HyperText Transfer Protocol” (ismert nevén “HTTP”) – egy szabványosított protokoll – segítségével küldi el, amely meghatározza, hogyan kell kinéznie egy kérésnek (és válasznak), milyen adatokat tartalmazhat (és milyen formában), és hogyan kell a kérést elküldeni. A HTTP-ről itt tudhat meg többet.
A HTTP használata miatt egy teljes URL valójában így néz ki: http://academind.com. A böngésző automatikusan kitölti Ön helyett.
És létezik HTTPS is – ez olyan, mint a HTTP, de titkosított. A legtöbb modern oldal (beleértve az academind.com-ot is) ezt használja a HTTP helyett. A teljes URL így lesz: https://academind.com.
Mivel az egész folyamat és formátum szabványosított, nem kell találgatni, hogyan kell ezt a kérést a szervernek beolvasnia.
A szerver ezután megfelelően kezeli a kérést, és egy úgynevezett “választ” küld vissza. Ismétlem, a “válasz” egy technikai dolog, és egy kicsit hasonlít a “kéréshez”. Úgy is mondhatnánk, hogy alapvetően egy “kérés” az ellenkező irányban.
A kéréshez hasonlóan a válasz is tartalmazhat adatokat, metaadatokat stb. Ha egy olyan oldalt kérünk, mint az academind.com, a válasz tartalmazza azt a kódot, amely az oldal képernyőre való megjelenítéséhez szükséges.
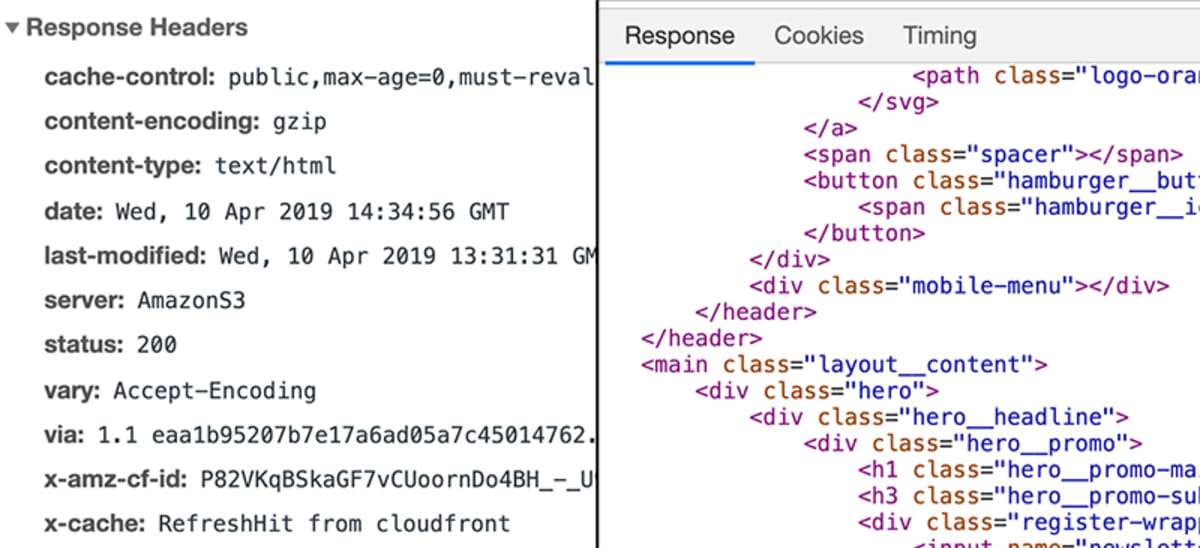
Mi történik a szerveren?
Azt a webfejlesztők határozzák meg. Végül egy választ kell küldeni. Ennek a válasznak nem kell tartalmaznia “egy weboldalt”. Bármilyen adatot tartalmazhat – beleértve a fájlokat vagy képeket is.
Egyik szerver úgy van programozva, hogy a kérés alapján dinamikusan generáljon weboldalakat (pl. egy profiloldal, amely az Ön személyes adatait tartalmazza), más szerverek előre generált HTML-oldalakat küldenek vissza (pl. egy híroldalt). Vagy mindkettő történik – egy weboldal különböző részeire. Van egy harmadik alternatíva is: Előre generált weboldalak, amelyek azonban a böngészőben megváltoztatják a megjelenésüket és az adataikat.
A különböző típusú weboldalak nem igazán állnak e cikk középpontjában. Ha többet szeretne megtudni róla, nézze meg ezt a cikket + videót.
Egyszerű esetünkben van egy kiszolgáló, amely egy weboldal megjelenítéséhez szükséges kódot küld vissza. Folytassuk tehát a 3. lépéssel.
3. lépés – A válasz elemzése
A böngésző megkapja a szerver által küldött választ. Ez önmagában azonban nem jelenít meg semmit a képernyőn.
Ehelyett a következő lépés az, hogy a böngésző elemzi a választ. Ugyanúgy, ahogyan azt a szerver tette a kéréssel. Ebben természetesen ismét segít a HTTP által kikényszerített szabványosítás.
A böngésző ellenőrzi a válaszba zárt adatokat és metaadatokat. És ezek alapján eldönti, hogy mit tegyen.
Elképzelhető, hogy volt már olyan eset, amikor egy PDF megnyílt a böngészőben. Ez azért történt, mert a válasz arról tájékoztatta a böngészőt, hogy az adat nem egy weboldal, hanem egy PDF-dokumentum. A böngésző pedig megpróbálja kiválasztani a legjobb kezelési mechanizmust minden általa észlelt adattípushoz.
Visszatérve a weboldalas forgatókönyvünkhöz.
Ebben az esetben a válasz tartalmazna egy bizonyos metaadatot, amely közli a böngészővel, hogy a válaszadat text/html típusú.
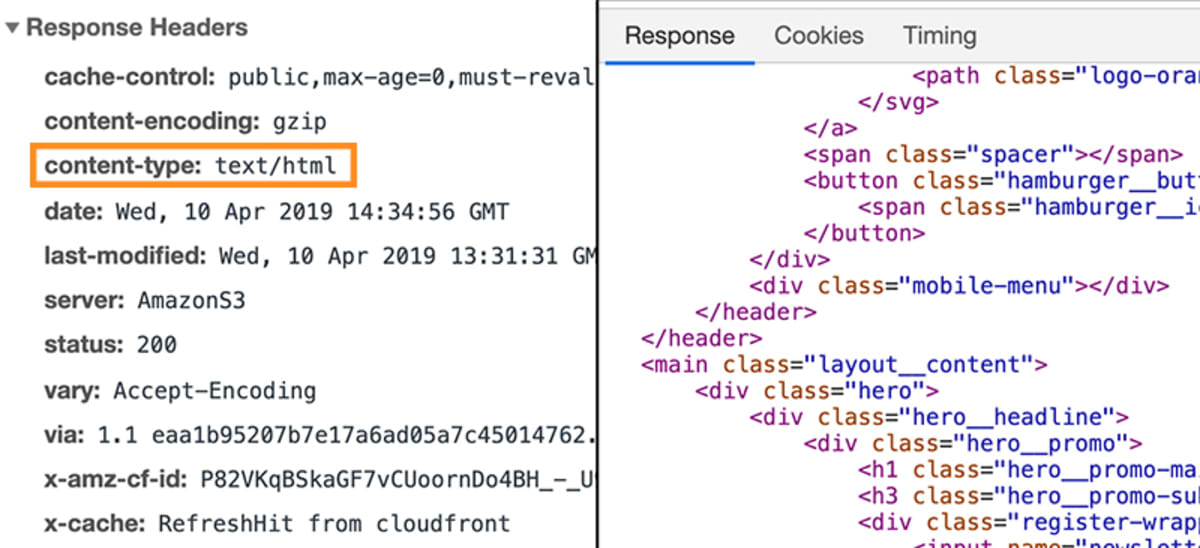
Ez lehetővé teszi a böngésző számára, hogy ezután HTML-kódként elemezze a válaszhoz csatolt tényleges adatokat.
A HTML a web alapvető “programozási nyelve” (technikailag nem programozási nyelv – nem lehet vele logikát írni). A HTML a “Hyper Text Markup Language” rövidítése, és egy weboldal felépítését írja le.
A kód így néz ki:
<h1>Breaking News!</h1><p>Websites work because browser understand HTML!</p><h1> és <p> az úgynevezett “HTML-tagek”, és ha többet szeretnél megtudni a HTML-ről, ez a sorozat remek hely erre.
Minden HTML-tagnek van valamilyen szemantikai jelentése, amit a böngésző megért, mert a HTML is szabványosított. Ezért nem kell találgatni, hogy mit jelent egy <h1> tag.
A böngésző tudja, hogyan kell elemezni a HTML-t, és most egyszerűen végigmegy a teljes válaszadaton (más néven “választest”), hogy megjelenítse a webhelyet.
4. lépés – Az oldal megjelenítése
Amint említettük, a böngésző végigmegy a szerver által visszaküldött HTML-adatokon, és ezek alapján felépíti a webhelyet.
Azt azonban fontos tudni, hogy a HTML nem tartalmaz semmilyen utasítást arra vonatkozóan, hogy a webhelynek hogyan kell kinéznie (azaz hogyan kell stilizálni). Valójában csak a szerkezetet határozza meg, és megmondja a böngészőnek, hogy melyik tartalom címsor, melyik tartalom kép, melyik tartalom bekezdés stb. Ez különösen fontos a hozzáférhetőség szempontjából – a képernyőolvasók minden hasznos információt kiszednek a HTML szerkezetéből.
Egy oldal, amely csak HTML-t tartalmaz, azonban így nézne ki:

Nem olyan szép, igaz?
Ezért van egy másik fontos technológia (egy másik “programozási nyelv”, amely valójában nem is programozási nyelv): A CSS (“Cascading Style Sheets”).
A CSS a weboldal stílusának kialakításáról szól. Ez a “CSS-szabályok” segítségével történik:
h1 { color: blue;}Ez a szabály minden <h1> taget kékre színezne.
Az ehhez hasonló szabályokat a HTML-kódon belül is hozzá lehet adni, de általában külön .css fájlok részét képezik, amelyeket külön kérnek.
Nem bocsátkozva itt túl sok részletbe, ez egy fontos következményt hordoz magában: Egy weboldal többből is állhat, mint az első válasz adatai, amit kapunk.
A gyakorlatban a weboldalak sok további adatot hívnak le (további kéréseken és válaszokon keresztül), amelyeket az első válasz megérkezése után indítanak el.
Hogyan működik ez?
Nos, az első válasz HTML-kódja egyszerűen utasításokat tartalmaz további adatok újabb kéréseken keresztül történő lekérdezésére – és a böngésző megérti ezeket az utasításokat:
<link rel="stylesheet" href="/page-styles.css" />
Még egyszer, itt nem merülök el a részletekbe. Ha többet szeretnél megtudni a CSS-ről, a Teljes útmutató nagyon hasznos lesz!
A CSS-szel együtt a böngésző képes a weboldalakat így megjeleníteni:

Valójában egy másik programozási nyelvről van szó (ezúttal tényleg egy programozási nyelvről!):
Nem mindig látható, de minden dinamikus tartalom, amit egy weboldalon találsz (pl. lapok, átfedések stb.) valójában csak a JavaScriptnek köszönhető. Lehetővé teszi a webfejlesztők számára, hogy olyan kódot határozzanak meg, amely a böngészőben fut (nem a szerveren), ezért a JavaScript segítségével megváltoztatható a weboldal, miközben a felhasználó nézi azt.
Amint korábban, ha többet szeretne megtudni, nézze meg JavaScript forrásainkat, például a teljes tanfolyamunkat.
Ez az a négy lépés, amely mindig részt vesz, amikor beír egy oldal címét, például academind.com, és ezt követően a böngészőjében látja a weboldal tartalmát.
# Szerveroldali vs. böngészőoldali
A fenti négy lépésből megtanulta, hogy két alapvető “oldalt” különböztethetünk meg, amikor a webről beszélünk: Szerveroldali és böngészőoldali (vagy: kliensoldali, mivel böngésző nélkül is hozzáférhetünk az internethez – lásd alább!).
Ha webfejlesztő szeretnél lenni, fontos tudnod, hogy ezekhez az oldalakhoz különböző technológiákat és programozási nyelveket használsz.
Szerver-oldali
Szerver-oldali programozási nyelvekre van szükséged – azaz olyan nyelvekre, amelyek nem a böngészőben működnek, hanem egy normál számítógépen futnak (a szerver végső soron csak egy normál számítógép).
Példák lehetnek:
- Node.js
- PHP
- Python
Fontos: A PHP kivételével ezeket a programozási nyelveket a webfejlesztésen kívül más célokra is használhatja.
Míg a Node.js-t valóban elsősorban szerveroldali programozásra használják (bár technikailag nem korlátozódik erre), a Python nagyon népszerű az adattudomány és a gépi tanulás területén is.
Böngészőoldali
A böngészőben pontosan három nyelvet/technológiát kell megtanulnod. De míg a szerveroldali nyelvek alternatívák voltak, addig ezt a három böngészőoldali nyelvet mind kötelező ismerni és megérteni:
- HTML (a szerkezetért)
- CSS (a stílusért)
- JavaScript (a dinamikus tartalomért)
# “A színfalak mögött” Internet
Az eddigiekben a honlapokról beszéltünk. Vagyis azt az esetet, amikor beírunk egy URL-t (pl. “academind.com/learn”) a böngészőbe, és cserébe egy weboldalt kapunk.
De az internet ennél több. Sőt, ennél többre használod minden nap!
A kérések és válaszok alapgondolata mindig ugyanaz. De nem feltétlenül minden válasz egy weboldal. És nem minden kérés akar egy weboldalt.
A kérésekhez és válaszokhoz csatolt metaadatok szabályozzák, hogy milyen adatokat kérnek és küldenek vissza. Természetesen mindkét érintett félnek (azaz a kliensnek és a szervernek) támogatnia kell a kéréseket és a küldött adatokat.
Nem kérhetsz például egy PDF-et a "academind.com"-ről. Elküldhetne egy ilyen kérést, de nem kapna vissza PDF-et – egyszerűen azért, mert nem támogatjuk ezt a fajta kért adatot ezen az adott URL-en.
De sok olyan szerver van, amely arra specializálódott, hogy olyan URL-eket szolgáltasson, amelyek bizonyos adatokat adnak vissza. Az ilyen szolgáltatásokat “API-knak” (“Application Programming Interface”) is nevezik.
A mobilalkalmazások például “láthatatlan” HTTP-kéréseket küldenek az ilyen API-knak (az általuk ismert konkrét URL-címekre), hogy adatokat kapjanak vagy tároljanak. A Twitter például a tweet feedet hívja le.
És még a weboldalakon is küldenek ilyen “láthatatlan” kéréseket. Ha feliratkozol a hírlevelünkre (amit természetesen meg kell tenned!), nem töltődik be új oldal. Mert az adatcsere a színfalak mögött zajlik. Hiába a kliens a böngésző ebben az esetben, a kérés, amit elküldünk, nem kér cserébe semmilyen weboldalt. És a szerver URL címe, amely fogadja, nem kínál weboldalt – ehelyett a szerver tudja, hogyan kezelje az Ön e-mail címét.
Még sokkal részletesebben is elmehetnénk itt, de ez már egy hosszú cikk. Most már tisztában kell lenned azzal, hogyan működik a web, és milyen alapvető technológiákról van szó.
Vélemény, hozzászólás?