SQL CHIT CHAT … Blog about Sql Server
On novembre 29, 2021 by adminSummary
Les expressions de table communes ont été introduites dans SQL Server 2005. Elles représentent l’un des nombreux types d’expressions de table disponibles dans Sql Server. Une expression de table commune récursive est un type d’expression de table commune qui se référence elle-même. Il est généralement utilisé pour résoudre des hiérarchies.
Dans ce billet, je vais essayer d’expliquer comment fonctionne la récursion CTE, où elle se situe dans le groupe des expressions de table disponibles dans Sql Server et quelques scénarios de cas où la récursion brille.
Expressions de table
Une expression de table est une expression de requête nommée qui représente une table relationnelle. Sql Server supporte quatre types d’expressions de table;
- Tables dérivées
- Vues
- ITVF (Inline Table Valued Functions aka vues paramétrées)
- CTE (Common Table Expressions)
- CTE récursif
En général, les expressions de table ne sont pas matérialisées sur le disque. Ce sont des tables virtuelles présentes uniquement en mémoire RAM (elles peuvent être déversées sur le disque suite à i.e. la pression mémoire, la taille d’une table virtuelle etc…). La visibilité des expressions de table peut varier i.e. les vues et ITVF sont des objets db visibles au niveau de la base de données, alors que leur portée est toujours au niveau d’une instruction SQL – les expressions de table ne peuvent pas opérer sur différentes instructions sql dans un lot.
Les avantages des expressions de table ne sont pas liés aux performances d’exécution des requêtes mais à l’aspect logique du code !
Tables dérivées
Les tables dérivées sont des expressions de table également appelées sous-requêtes. Les expressions sont définies dans la clause FROM d’une requête externe. La portée des tables dérivées est toujours la requête externe.
Le code suivant représente une table dérivée appelée AUSCust.
Transact-…SQL
|
1
2
3
4
5
6
7
8
|
SELECT AUSCust.*
FROM (
SELECT custid
,companyname
FROM dbo.Customers
WHERE country = N’Australia’
) AS AUSCust ;
–AUSCust est une table dérivée
|
La table dérivée AUSCust n’est visible que pour la requête externe et la portée est limitée à l’instruction sql.
Vues
Les vues (parfois appelées relations virtuelles) sont des expressions de table réutilisables. Une définition de vue est stockée en tant qu’objet Sql Server avec des objets tels que ; les tables définies par l’utilisateur, les déclencheurs, les fonctions, les procédures stockées etc.
Le principal avantage des vues par rapport aux autres types d’expressions de table est leur réutilisabilité c’est-à-dire que les requêtes dérivées et les CTE ont une portée limitée à une seule déclaration.
Les vues ne sont pas matérialisées, ce qui signifie que les lignes produites par les vues ne sont pas stockées en permanence sur le disque. Les vues indexées est Sql Server(similaire mais pas la même chose que les vues matérialisées dans d’autres plates-formes db) sont un type spécial de vues qui peuvent avoir leur jeu de résultats stocké de façon permanente sur le disque – plus sur les vues indexées peut être trouvé ici.
Juste quelques directives de base sur la façon de définir les vues SQL.
-
SELECT * dans le contexte d’une définition de vue se comporte différemment que lorsqu’il est utilisé comme un élément de requête dans un lot.
Transact.SQL
12345CREATE VIEW dbo.vwTestASSELECT *FROM dbo.T1…La définition de la vue inclura toutes les colonnes de la table sous-jacente, dbo.T1 au moment de la création de la vue. Cela signifie que si nous modifions le schéma de la table (c’est-à-dire si nous ajoutons et/ou supprimons des colonnes), les modifications ne seront pas visibles pour la vue – la définition de la vue ne sera pas automatiquement modifiée pour prendre en charge les modifications de la table. Cela peut causer des erreurs dans les situations où i.e une vue essayer de sélectionner des colonnes inexistantes à partir d’une table sous-jacente.
Pour résoudre le problème, nous pouvons l’une des deux procédures système : sys.sp_refreshview ou sys.sp_refreshsqlmodule.
Pour empêcher ce comportement suivre la meilleure pratique et nommer explicitement les colonnes dans la définition de la vue. - Les vues sont des expressions de table et ne peuvent donc pas être ordonnées. Les vues ne sont pas des curseurs ! Il est possible, cependant, d' »abuser » de la construction TOP/ORDER BY dans la définition de la vue pour tenter de forcer une sortie triée. par exemple .
Transact-SQL
12345CREATE VIEW dbo.MyCursorViewASSELECT TOP(100 PERCENT) *FROM dbo.SomeTableORDER BY column1 DESCL’optimiseur de requêtes rejettera le TOP/ORDER BY puisque le résultat d’une expression de table est toujours une table – sélectionner TOP(100 PERCENT) n’a de toute façon aucun sens. L’idée derrière les structures de table est dérivée d’un concept dans la théorie des bases de données relationnelles connu sous le nom de Relation.
-
Lors du traitement d’une requête qui fait référence à une vue, la requête de la définition de la vue est dépliée ou étendue et mise en œuvre dans le contexte de la requête principale. Le code consolidé(requête) sera ensuite optimisé et exécuté.
ITVF (Inline Table Valued Functions)
Les ITVF sont des expressions de table réutilisables qui prennent en charge les paramètres d’entrée. Les fonctions peuvent être traitées comme des vues paramétrées.
CTE (Common Table Expressions)
Les expressions de table communes sont similaires aux tables dérivées mais avec plusieurs avantages importants;
Une CTE est définie à l’aide d’une instruction WITH, suivie d’une définition d’expression de table. Pour éviter toute ambiguïté (TSQL utilise le mot-clé WITH à d’autres fins, c’est-à-dire WITH ENCRYPTION, etc.), l’instruction précédant la clause WITH du CTE DOIT être terminée par une demi-colonne. Cela n’est pas nécessaire si la clause WITH est la toute première déclaration dans un lot c’est-à-dire dans une définition VIEW/ITVF)
NOTE : Le demi-colonne, le terminateur de déclaration est pris en charge par la norme ANSI et il est fortement recommandé de l’utiliser dans le cadre de la pratique de programmation TSQL.
CTE récursif
SQL Server prend en charge les capacités de requête récursive mises en œuvre par le biais des CTE récursifs depuis la version 2005(Yukon).
Éléments d’un CTE récursif
- Membre(s) d’ancrage – Définitions de requête qui;
- renvoie une table de résultats relationnelle valide
- est exécutée UNE SEULE FOIS au début de l’exécution de la requête
- est positionnée toujours avant la première définition de membre récursif
- le dernier membre d’ancrage doit être suivi de l’opérateur UNION ALL. L’opérateur combine le dernier membre d’ancrage avec le premier membre récursif
- opérateur multi-ensembles UNION ALL. L’opérateur opère sur
- Membre(s) récursif(s) – Les définitions de requêtes qui;
- renvoient une table de résultats relationnelle valide
- ont une référence au nom du CTE. La référence au nom de l’ETC représente logiquement le jeu de résultats précédent dans une séquence d’exécutions, c’est-à-dire que le premier jeu de résultats « précédent » dans une séquence est le résultat que le membre d’ancrage a retourné.
- Invocation de l’ETC – Instruction finale qui invoque la récursion
- Mécanisme à sécurité intégrée – L’option MAXRECURSION empêche le système de base de données des boucles infinies. C’est un élément facultatif.
Contrôle de terminaison
Le membre récursif de CTE n’a pas de contrôle explicite de terminaison de récursion.
Dans de nombreux langages de programmation, nous pouvons concevoir une méthode qui s’appelle elle-même – une méthode récursive. Chaque méthode récursive doit être terminée lorsqu’une certaine condition est satisfaite. C’est la terminaison récursive explicite. Après ce point, la méthode commence à retourner des valeurs. Sans point de terminaison, la récursion peut finir par s’appeler elle-même « sans fin ».
Le contrôle de terminaison des membres récursifs de CTE est implicite , ce qui signifie que la récursion s’arrête lorsqu’aucune ligne n’est renvoyée par l’exécution précédente de CTE.
Voici un exemple classique de récursion en programmation impérative. Le code ci-dessous calcule la factorielle d’un nombre entier en utilisant un appel récursif de fonction(méthode).
Le code complet du programme console se trouve ici.
MAXRECURSION
Comme mentionné ci-dessus, les CTE récursifs ainsi que toute opération récursive peuvent provoquer des boucles infinies s’ils ne sont pas conçus correctement. Cette situation peut avoir un impact négatif sur les performances de la base de données. Le moteur Sql Server dispose d’un mécanisme de sécurité qui ne permet pas les exécutions infinies.
Par défaut, le nombre de fois que le membre récursif peut être invoqué est limité à 100 (cela ne compte pas l’exécution de l’ancre une fois). Le code échouera à la 101e exécution du membre récursif.
Msg 530, Level 16, State 1, Line xxx
L’instruction s’est terminée. La récursion maximale 100 a été épuisée avant la fin de l’instruction.
Le nombre de récursions est géré par l’option de requête MAXRECURSION n. L’option peut remplacer le nombre par défaut de récursions maximales autorisées. Le paramètre (n) représente le niveau de récursion. 0<=n <=32767
Note importante: : MAXRECURSION 0 – désactive la limite de récursion!
La figure 1 montre un exemple de CTE récursif avec ses éléments

Figure 1, éléments de CTE récursifs
La récursion déclarative est assez différente de la récursion traditionnelle, impérative. En dehors de la structure différente du code, nous pouvons observer la différence entre le contrôle de terminaison explicite et implicite. Dans l’exemple CalculateFactorial, le point de terminaison explicite est clairement défini par la condition : if (number == 0) then return 1.
Dans le cas du CTE récursif ci-dessus, le point de terminaison est implicitement défini par l’opération INNER JOIN, plus précisément par le résultat de l’expression logique dans sa clause ON : ON e.MgrId = c.EmpId. Le résultat de l’opération de table détermine le nombre de récursions. Cela deviendra plus clair dans les sections suivantes.
Utiliser un CTE récursif pour résoudre la hiérarchie des employés
Il existe de nombreux scénarios dans lesquels nous pouvons utiliser des CTE récursifs c’est-à-dire pour séparer des éléments etc. Le scénario le plus courant que j’ai rencontré au cours de nombreuses années de séquençage a été d’utiliser des CTE récursifs pour résoudre divers problèmes hiérarchiques.
La hiérarchie arborescente des employés est un exemple classique d’un problème hiérarchique qui peut être résolu en utilisant des CTE récursifs.
Exemple
Disons que nous avons une organisation avec 12 employés. Les règles de gestion suivantes s’appliquent;
- Un employé doit avoir un id unique, EmpId
- renforcé par : Contrainte de clé primaire sur la colonne EmpId
- Un employé peut être géré par 0 ou 1 manager.
- enforcé par : PK sur EmpId, FK sur MgrId et colonne MgrId NULLable
- Un manager peut gérer un ou plusieurs employés.
- renforcé par : Contrainte de clé étrangère(auto-référencée) sur la colonne MgrId
- Un gestionnaire ne peut pas se gérer lui-même.
- renforcé par : Contrainte CHECK sur la colonne MgrId
La hiérarchie arborescente est mise en œuvre dans une table appelée dbo.Employees. Les scripts se trouvent ici.

Figure 2, table Employees
Présentons le mode de fonctionnement des CTE récursifs en répondant à la question : Qui sont les subordonnés directs et indirects du manager avec EmpId = 3?
D’après l’arbre hiérarchique de la figure 2, nous pouvons clairement voir que le manager (EmpId = 3) gère directement les employés ; EmpId=7, EmpId=8 et EmpId=9 et gère indirectement ; EmpId=10, EmpId=11 et EmpId=12.
La figure 3 montre la hiérarchie EmpId=3 et le résultat attendu. Le code peut être trouvé ici.

Figure 3, EmpId=3 subordonnés directs et indirects
Alors, comment avons-nous obtenu le résultat final.
La partie récursive dans l’itération actuelle fait toujours référence à son résultat précédent de l’itération précédente. Le résultat est une expression de table(ou table virtuelle) appelée cte1(la table du côté droit de l’INNER JOIN). Comme nous pouvons le voir, cte1 contient également la partie d’ancrage. Lors de la toute première exécution (la première itération), la partie récursive ne peut pas faire référence à son résultat précédent car il n’y a pas eu d’itération précédente. C’est pourquoi, lors de la première itération, seule la partie ancre s’exécute et une seule fois pendant tout le processus. Le jeu de résultats de la requête de l’ancre donne à la partie récursive son résultat précédent dans la deuxième itération. L’ancre agit comme un volant d’inertie si vous voulez 🙂
Le résultat final se construit à travers les itérations c’est-à-dire Résultat de l’ancre + résultat de l’itération 1 + résultat de l’itération 2 …
La séquence logique d’exécution
La requête de test est exécutée en suivant la séquence logique ci-dessous:
- L’instruction SELECT en dehors de l’expression cte1 invoque la récursion. La requête d’ancrage s’exécute et renvoie une table virtuelle appelée cte1. La partie récursive renvoie une table vide puisqu’elle n’a pas son résultat précédent. Rappelez-vous que les expressions dans l’approche basée sur les ensembles sont évaluées en une seule fois.
 Figure 4, valeur de cte1 après la 1ère itération
Figure 4, valeur de cte1 après la 1ère itération - La deuxième itération commence.C’est la première récursion. La partie ancre a joué son rôle dans la première itération et ne retourne désormais que des ensembles vides. Cependant, la partie récursive peut maintenant faire référence à son résultat précédent (valeur de cte1 après la première itération) dans l’opérateur INNER JOIN. L’opération de table produit le résultat de la deuxième itération comme le montre la figure ci-dessous.
 FIgure 5, valeur cte1 après la 2e itération
FIgure 5, valeur cte1 après la 2e itération - La deuxième itération produit un ensemble non vide, donc le processus continue avec la troisième itération – la deuxième récursion. L’élément récursif fait maintenant référence au résultat cte1 de la deuxième itération.
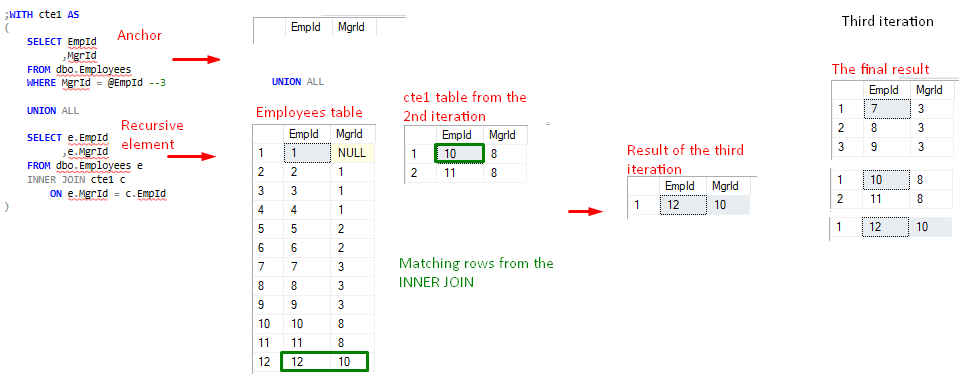
FIgure 6, valeur cte1 après la 3e itération - Une chose intéressante se produit à la 4e itération – la troisième tentative de récursion. Suivant le modèle précédent, l’élément récursif utilise le résultat cte1 de l’itération précédente. Cependant, cette fois-ci, aucune ligne n’est renvoyée à la suite de l’opération INNER JOIN, et l’élément récursif renvoie un ensemble vide. C’est le point de terminaison implicite mentionné précédemment. Dans ce cas, l’évaluation de l’expression logique de INNER JOIN dicte le nombre de récursions.
Parce que le dernier résultat cte1 est un ensemble de résultats vide, la 4e itération(ou 3e récursion) est « annulée » et le processus se termine avec succès.
Figure 7, La dernière itération
L’annulation logique de la 3e récursion (la dernière récursion qui a produit un ensemble de résultats vide ne compte pas) deviendra plus claire dans la section suivante, analyse du plan d’exécution récursif CTE.Nous pouvons ajouter l’option de requête OPTION(MAXRECURSION 2) à la fin de la requête qui limitera le nombre de récursions autorisées à 2. La requête produira le résultat correct prouvant que seules deux récursions sont nécessaires pour cette tâche.Remarque : Du point de vue de l’exécution physique, le jeu de résultats est progressivement(au fur et à mesure que les rangées remontent) envoyé aux tampons du réseau et de retour à l’application client.
Enfin, la réponse sur la question ci-dessus est :
Il y a six employés qui rapportent directement ou indirectement à l’Emp = 3. Trois employés, EmpId= 7, EmpId=8 et EmpId=9 sont des subordonnés directs et EmpId=10, EmpId=11 et EmpId=12 sont des subordonnés indirects.
Connaissant la mécanique du CTE récursif, nous pouvons facilement résoudre les problèmes suivants.
- trouver tous les employés qui sont hiérarchiquement au-dessus de EmpId = 10 (code ici)
- trouver les subordonnés directs et de deuxième niveau de EmpId=8’s(code ici)
Dans le deuxième exemple, nous contrôlons la profondeur de la hiérarchie en limitant le nombre de récursions.
Un élément d’ancrage nous donne le premier niveau de la hiérarchie, dans ce cas, les subordonnés directs. Chaque récursion déplace ensuite un niveau hiérarchique vers le bas à partir du premier niveau. Dans l’exemple, le point de départ est EmpId=8 et ses subordonnés directs. La première récursion déplace un niveau de plus vers le bas de la hiérarchie où « vivent » les subordonnés de deuxième niveau de EmpId=8.
Problème de référence circulaire
L’une des choses intéressantes avec les hiérarchies est que les membres d’une hiérarchie peuvent former une boucle fermée où le dernier élément de la hiérarchie fait référence au premier élément. La boucle fermée est également connue sous le nom de référence circulaire.
Dans les cas comme celui-ci, le point de terminaison implicite, comme l’opération INNER JOIN expliquée précédemment, ne fonctionnera tout simplement pas parce qu’il retournera toujours un ensemble de résultats non vide pour que la récursion suivante continue. La partie récursion continuera à rouler jusqu’à ce qu’elle atteigne la sécurité intégrée de Sql Server, l’option de requête MAXRECURSION.
Pour démontrer la situation de référence circulaire en utilisant l’environnement de test précédemment mis en place, nous devrons
- Supprimer les contraintes de clé primaire et étrangère de la table dbo.Employees pour permettre les scénarios de boucles fermées.
- Créer une référence circulaire (EmpId=10 gérera son manager indirect , EmpId = 3)
- Etendre la requête de test utilisée dans les exemples précédents, pour pouvoir analyser la hiérarchie des éléments dans la boucle fermée.
La requête de test étendue se trouve ici.
Avant de continuer avec l’exemple de la référence circulaire, voyons comment fonctionne la requête de test étendue. Commentez les prédicats de la clause WHERE(les deux dernières lignes) et exécutez la requête contre la table originale dbo.Employee
 Figure 8, Détection de l’existence de boucles circulaires dans les hiérarchies
Figure 8, Détection de l’existence de boucles circulaires dans les hiérarchies
Le résultat de la requête étendue est exactement le même que le résultat présenté dans l’expérience précédente dans la Figure 3. La sortie est étendue pour inclure les colonnes suivantes
- pth – Représente graphiquement la hiérarchie actuelle. Initialement, dans la partie d’ancrage, il ajoute simplement le premier subordonné à MgrId=3, le manager à partir duquel nous commençons. Maintenant, chaque élément récursif prend la valeur pth précédente et lui ajoute la subordonnée suivante.
- recLvl – représente le niveau actuel de récursion. L’exécution de l’ancre est comptée comme recLvl=0
- isCircRef – détecte l’existence d’une référence circulaire dans la hiérarchie actuelle(row). Dans le cadre d’un élément récursif, il recherche l’existence d’un EmpId qui a été précédemment inclus dans la chaîne pth.
i.e si le pth précédent ressemble à 3->8->10 et que la récursion actuelle ajoute » ->3 « , (3->8 >10 -> 3) ce qui signifie que EmpId=3 n’est pas seulement un supérieur indirect de EmpId=10, mais est aussi le subordonné de EmpId=10 – je suis le patron ou ton patron, et tu es mon patron genre de situation 😐
Faisons maintenant les changements nécessaires sur dbo.Employees pour voir la requête de test étendue en action.
Supprimez les contraintes PK et FK pour permettre les références circulaires et ajoutez un « bad boy circular ref » à la table.
Exécutez la requête de test étendue, et analysez les résultats (n’oubliez pas de dé-commettre la clause WHERE précédemment commentée à la fin du script)
Le script exécutera 100 récursions avant d’être interrompu par la MAXRECURSION par défaut. Le résultat final sera limité à deux récursions … AND cte1.recLvl <= 2 ; ce qui est nécessaire pour résoudre la hiérarchie de EmpId=3.
La figure 9 montre une hiérarchie en boucle fermée, le nombre maximum autorisé de récursions erreur épuisée et la sortie qui montre la boucle fermée.
Figure 10, Référence circulaire détectée
Quelques notes sur le script de référence circulaire.
Le script est juste une idée de comment trouver des boucles fermées dans les hiérarchies. Il ne signale que la première occurrence d’une référence circulaire – essayez de supprimer la clause WHERE et observez le résultat.
À mon avis, le script (ou des versions similaires du script) peut être utilisé dans un environnement de production à des fins de dépannage ou pour prévenir la création de références circulaires dans une hiérarchie existante. Cependant, il doit être sécurisé par une MAXRECURSION n appropriée, où n est la profondeur prévue de la hiérarchie.
Ce script est non relationnel et repose sur une technique de traversée. C’est toujours la meilleure approche d’utiliser des contraintes déclaratives (PK, FK, CHECK..) pour empêcher toute boucle fermée dans les données.
Analyse du plan d’exécution
Ce segment explique comment l’optimiseur de requêtes (QO) de Sql Server met en œuvre un CTE récursif. Il existe un modèle commun que QO utilise lors de la construction du plan d’exécution. Exécuter la requête de test originale et inclure le plan d’exécution réel
Comme la requête de test, le plan d’exécution a deux branches : la branche d’ancrage et la branche récursive. L’opérateur de concaténation, qui implémente l’opérateur UNION ALL, relie les résultats des deux parties formant le résultat de la requête.
Tentons de concilier la séquence d’exécution logique mentionnée précédemment et l’implémentation réelle du processus.
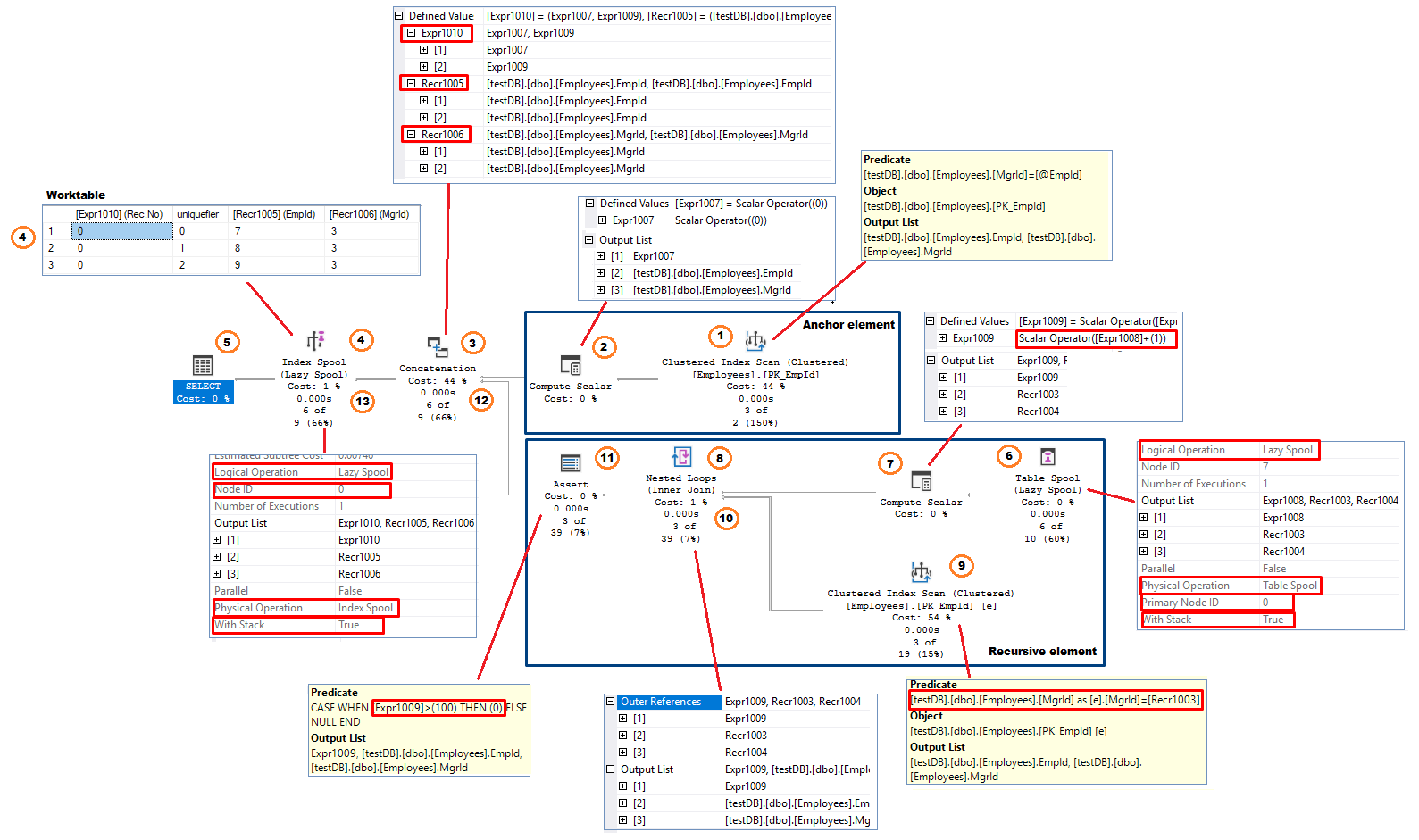
Figure 11, Plan d’exécution d’un CTE récursif
Suivant le flux de données (direction de droite à gauche), le processus ressemble à :
Élément d’ancrage (exécuté une seule fois)
- Opérateur de balayage d’index clusterisé – le système effectue un balayage d’index. Dans cet exemple, il applique l’expression MgrId = @EmpId comme prédicat résiduel. Les lignes sélectionnées(colonnes EmpId et MgrId) sont transmises (ligne par ligne) à l’opérateur précédent.
- Compute Scalar L’opérateur ajoute une colonne à la sortie. Dans cet exemple, le nom de la colonne ajoutée est . Cela représente le Nombre de récursions. La colonne a une valeur initiale de 0 ; =0
- Concaténation – combine les entrées des deux branches. Lors de la première itération, l’opérateur reçoit des lignes uniquement de la branche d’ancrage. Il change également les noms des colonnes de sortie. Dans cet exemple, les nouveaux noms de colonnes sont :
- = ou * * détient le nombre de récursions affectées dans la branche récursive. Il n’a pas de valeur dans la première itération.
- = EmpId(de la partie ancrée) ou EmpId(de la partie récursive)
- = MgrId(de la partie ancrée) ou MgrId (de la partie récursive)
- Index Spool (Lazy Spool) Cet opérateur stocke le résultat reçu de l’opérateur Concaténation dans un tableau de travail. Il a la propriété « Opération logique » définie sur « Lazy Spool ». Cela signifie que l’opérateur renvoie immédiatement ses lignes d’entrée et n’accumule pas toutes les lignes jusqu’à ce qu’il obtienne le jeu de résultats final (Eager Spool). Le tableau de travail est structuré comme un index clusterisé dont la colonne clé est le numéro de récursion. Comme la clé de l’index n’est pas unique, le système ajoute un unicificateur interne de 4 octets à la clé de l’index pour garantir que toutes les lignes de l’index sont, du point de vue de l’implémentation physique, identifiables de manière unique. L’opérateur a également la propriété « With Stack » définie sur « True » qui fait de cette version de l’opérateur spool un Stack Spool Un opérateur Stack Spool a toujours deux composants – un Index Spool qui construit la structure de l’index et un Table Spool qui agit comme un consommateur des lignes stockées dans la table de travail qui a été construite par l’Index Spool.
À ce stade, l’opérateur Index Spool renvoie des lignes à l’opérateur SELECT et stocke les mêmes lignes dans la table de travail. - L’opérateur SELECT renvoie EmpId et MgrId ( , ). Il exclut du résultat. Les lignes sont envoyées au tampon du réseau au fur et à mesure qu’elles arrivent des opérateurs en aval
Après avoir épuisé toutes les lignes de l’opérateur Index Scan, l’opérateur Concaténation bascule le contexte vers la branche récursive. La branche d’ancrage ne sera pas exécutée à nouveau au cours du processus.
Élément récursif
- Spool de table (Lazy Spool). Cet opérateur n’a pas d’entrées et, comme mentionné dans (4), agit comme un consommateur des lignes produites par le Spool d’index et stockées dans une table de travail en cluster. La propriété « Primary Node » de l’opérateur est définie sur 0, ce qui correspond à l’Id du nœud de l’Index Spool. Il met en évidence la dépendance des deux opérateurs. L’opérateur
- supprime les lignes qu’il a lues dans la récursion précédente. Il s’agit de la première récursion et il n’y a pas de lignes lues précédemment à supprimer. Le tableau de travail contient trois lignes (figure 4).
- Lire les lignes triées par la clé d’indexation + l’uniquificateur dans l’ordre décroissant. Dans cet exemple, la première ligne lue est EmpId=9, MgrId=3.
Enfin, l’opérateur renomme les noms des colonnes de sortie. =, = et devient .
NOTE : L’opérateur de spool de table peut être observé comme l’expression cte1 du côté droit du INNER JOIN (figure 4) - Compute Scalar L’opérateur ajoute 1 au nombre actuel de récursions précédemment stockées dans la colonne .Le résultat est stocké dans une nouvelle colonne, . = + 1 = 0 + 1 = 1. L’opérateur sort trois colonnes, les deux provenant du spool de table ( et ) et
- L’opérateur Nested Loop(I) reçoit des lignes de son entrée externe, qui est le Compute Scalar de l’étape précédente, puis utilise – représente EmpId de l’opérateur Table Spool, comme prédicat résiduel dans l’opérateur Index Scan positionné dans l’entrée interne de la boucle. L’entrée interne s’exécute une fois pour chaque ligne de l’entrée externe.
- L’opérateur Index Scan renvoie toutes les lignes qualifiées de la table dbo.Employees (deux colonnes ; EmpId et MgrId) à l’opérateur de boucle imbriquée.
- Boucle imbriquée(II) : L’opérateur combine à partir de l’entrée externe et EmpId et MgrId à partir de l’entrée interne et passe les trois lignes de colonnes à l’opérateur suivant.
- L’opérateur Assert est utilisé pour vérifier les conditions qui nécessitent l’abandon de la requête avec un message d’erreur. Dans le cas des CTE récursifs , l’opérateur assert met en œuvre l’option de requête « MAXRECURSION n ». Il vérifie si la partie récursive a atteint le nombre de récursions autorisé (n) ou non. Si le nombre actuel de récursions (voir étape 7) est supérieur à (n), l’opérateur renvoie 0, ce qui provoque une erreur d’exécution. Dans cet exemple, Sql Server utilise sa valeur par défaut MAXRECURSION de 100. L’expression se présente comme suit CASE WHEN > 100 THEN 0 ELSE NULL Si nous décidons d’exclure la sécurité intégrée en ajoutant MAXRECURSION 0, l’opérateur assert ne sera pas inclus dans le plan.
- La concaténation combine les entrées des deux branches. Cette fois-ci, il reçoit l’entrée de la partie récursive seulement et sort des colonnes/lignes comme indiqué dans l’étape 3.
- Index Spool (Lazy Spool) ajoute la sortie de l’opérateur de concaténation à la table de travail et la passe ensuite à l’opérateur SELECT. À ce stade, la table de travail contient le total de 4 lignes : trois lignes de l’exécution d’ancrage et une de la première récursion. Suivant la structure d’index clusterisé de la table de travail, la nouvelle ligne est stockée à la fin de la table de travail
-
Le processus reprend maintenant à partir de l’étape 6. L’opérateur de spool de table supprime les lignes précédemment lues (les trois premières lignes) de la table de travail et lit la dernière ligne insérée, la quatrième ligne.
Conclusion
CTE(Common table expressions) est un type d’expressions de table disponible dans Sql Server. Une CTE est une expression de table indépendante qui peut être nommée et référencée une ou plusieurs fois dans la requête principale.
L’une des utilisations les plus importantes des CTE est d’écrire des requêtes récursives. Les CTE récursifs suivent toujours la même structure – requête d’ancrage, opérateur multi-ensemble UNION ALL, membre récursif et l’instruction qui invoque la récursion. Les CTE récursifs sont des récursions déclaratives et, en tant que telles, ont des propriétés différentes de celles de leurs homologues impératifs. Par exemple, la vérification de la fin de la récursion déclarative est de nature implicite – le processus de récursion s’arrête lorsqu’il n’y a pas de lignes retournées dans le CTE précédent.
Laisser un commentaire