Qu’est-ce qu’un autoencodeur ?
On novembre 11, 2021 by adminUne introduction douce à l’autoencodeur et à ses diverses applications. De plus, ces tutoriels utilisent tf.keras,l’API Python de haut niveau de TensorFlow pour la construction et l’entraînement de modèles d’apprentissage profond.
.4310>
常常見到 Autoencodeur 的變形以及應用,打算花幾篇的時間好好的研究一下,順便練習 Tensorflow.keras 的 API 使用。
- Qu’est-ce que l’Autoencodeur
- Types d’Autoencodeur
- Application de l’Autoencodeur
- Mise en œuvre
- Conclusion
Grands exemples
Difficulté : ★ ★ ☆ ☆
後記 : 由於 Tensorflow 2.0 alpha 已於 3/8號釋出,但此篇是在1月底完成的,故大家可以直接使用安裝使用看看,但需要更新至相對應的 CUDA10。
Qu’est-ce que l’Autoencodeur ?
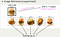
首先,什麼是 Autoencodeur 呢 ? 不囉唆,先看圖吧!
.Le concept original de l’auto-encodeur est très simple : il s’agit d’introduire des données d’entrée et d’obtenir exactement les mêmes données que celles d’entrée grâce à un réseau de type neuronal.Le codeur prend d’abord les données d’entrée, les compresse en un vecteur Z de plus petite dimension, puis entre le Z dans le décodeur pour lui redonner sa taille d’origine.Cela semble facile, mais regardons de plus près et voyons si c’est aussi simple que cela.

Encodeur:
L’encodeur est chargé de compresser les données d’entrée originales en un vecteur de faible dimension C. Ce C, que nous appelons habituellement code, vecteur latent ou vecteur de caractéristiques, mais j’ai l’habitude de l’appeler espace latent, car C représente une caractéristique cachée.L’encodeur peut compresser les données d’origine en un vecteur significatif de faible dimension, ce qui signifie que l’encodeur automatique a une réduction de la dimensionnalité et que la couche cachée a une fonction d’activation de transformation non linéaire, de sorte que cet encodeur est comme une version puissante de l’ACP, car l’encodeur peut faire des transformations non linéaires.Réduction de la dimension!
Décodeur:
Ce que fait le décodeur est de restaurer l’espace latent dans les données d’entrée autant que possible, ce qui est une transformation des vecteurs de caractéristiques de l’espace de dimension inférieure à l’espace de dimension supérieure.
Alors comment mesurez-vous le bon fonctionnement de l’Autoencodeur ! En comparant simplement la similarité des deux données d’entrée originales avec les données reconstruites.Notre fonction de perte peut donc s’écrire comme suit : ….
Fonction de perte:

Parce que nous voulons minimiser la différence entre lesL’AutoEncoder est formé en utilisant la rétropropagation pour mettre à jour les poids, tout comme un réseau neuronal normal.mettre à jour les poids.
Pour résumer, Autoencoder est …..
1. une architecture de modèle très courante, également utilisée couramment pour l’apprentissage non supervisé
2. peut être utilisé comme méthode de réduction de dimension pour les
3. peut être utilisé pour apprendre la représentation des données, avec des transformations de caractéristiques représentatives.
A ce stade, il devrait être facile de comprendre à quoi ressemble l’Autoencodeur, l’architecture est très simple, alors regardons ses transformations !
Types d’AutoEncoder
Après avoir expliqué les principes de base de l’AutoEncoder, il est temps de jeter un coup d’œil à l’utilisation étendue et avancée de l’AutoEncoder, afin que vous puissiez voir l’utilisation étendue de l’AutoEncoder !
2-1. Unet:
Unet peut être utilisé comme l’un des moyens de segmentation des images, et l’architecture d’Unet peut être considérée comme une variante d’Autoencoder.

2-2. Autoencodeurs récursifs:
C’est un réseau qui combine le nouveau texte d’entrée avec l’espace latent des autres entrées, le but de ce réseau est la classification des sentiments.Cela peut également être considéré comme une variante de l’Autoencodeur, qui extrait le texte clairsemé au fur et à mesure qu’il est tapé et trouve l’espace latent qui est important.

2-Seq2Seq:
Séquence à Séquence est un modèle génératif très populaire depuis un certain temps. C’est une merveilleuse solution au dilemme des types de RNN qui ne sont pas capables de gérer les paires indéterminées, et a donné de bons résultats sur des sujets tels que la génération de chatbot et de texte.Cela peut également être considéré comme une sorte d’architecture d’auto-encodage.

Applications de l’auto-codeur
.3612> Après avoir examiné les nombreuses et variées variations de l’Autoencodeur, voyons où l’Autoencodeur peut être utilisé d’une autre manière !
3-1. Poids prétraîné du modèle
L’autoencodeur peut également être utilisé pour le prétraînement du poids, ce qui signifie que le modèle trouve une meilleure valeur de départ.Par exemple, lorsque nous voulons compléter le modèle de cible tel que la cible. couche cachée est :, donc au début, nous utilisons le concept de l’autoencodeur à l’entrée 784 dimensions, et l’espace latent au milieu est de 1000 dimensions pour faire la pré-formation d’abord, de sorte que ces 1000 dimensions peuvent bien retenir l’entréeEnsuite, nous supprimons la sortie originale et ajoutons la deuxième couche, et ainsi de suite.De cette façon, l’ensemble du modèle aura une meilleure valeur de départ.
Huh ! Il y a une partie bizarre… si vous utilisez 1000 neurones pour représenter 784 dimensions d’entrée, cela ne signifie-t-il pas que le réseau doit simplement être recopié une nouvelle fois ? Quel est l’intérêt de la formation ? Oui, c’est pourquoi dans un pré-entraînement comme celui-ci, nous ajoutons généralement le régularisateur de la norme L1 afin que la couche cachée ne soit pas copiée à nouveau.

Selon Mr. Li HongyiDans le passé, il était plus courant d’utiliser une telle méthode pour la préformation, mais aujourd’hui, en raison de l’augmentation des compétences de formation, il n’est plus nécessaire d’utiliser cette méthode.Mais si vous disposez de très peu de données étiquetées mais d’un grand nombre de données non étiquetées, vous pouvez utiliser cette méthode pour effectuer le pré-entraînement au poids, car l’Autoencodeur est lui-même une méthode d’apprentissage non supervisée. Nous utilisons d’abord les données non étiquetées pour obtenir le pré-entraînement au poids, puis nous utilisons les données non étiquetées pour obtenir le pré-entraînement au poids.Nous utilisons d’abord les données non étiquetées pour obtenir le pré-entraînement des poids, puis nous utilisons les données étiquetées pour affiner les poids, afin d’obtenir un bon modèle.Pour plus de détails, voir la vidéo de M. Li, c’est très bien expliqué !
3-2. Segmentation d’images
Le modèle Unet que nous venons de voir, regardons-le à nouveau, car il s’agit essentiellement du problème de détection de défauts le plus courant dans l’industrie manufacturière de Taïwan.
Tout d’abord, nous devons étiqueter les données d’entrée, qui seront notre sortie. Ce que nous devons faire, c’est construire un réseau, entrer l’image originale (à gauche, des radiographies de dents) et générer la sortie (à droite, la classification de la structure des dents).Dans ce cas, le codeur & décodeur sera une couche de convolution avec un jugement graphique fort, extrayant les caractéristiques significatives et la déconvolution de retour dans le décodeur pour obtenir le résultat de la segmentation.

3-3. de la vidéo au texte
Pour un problème de légende d’image comme celui-ci, nous utilisons le modèle de séquence à séquence, où les données d’entrée sont un groupe de photos et la sortie est un texte décrivant les photos.Le modèle séquence à séquence utilise LSTM + Conv net comme codeur & décodeur, qui peut décrire une séquence d’actions séquentielles & en utilisant le noyau CNN pour extraire l’espace latent requis dans l’image.mais cette tâche est très difficile à réaliser, alors je vous laisse l’essayer si vous êtes intéressé !

3-4. Recherche d’images
Recherche d’images La chose à faire est d’entrer une image et d’essayer de trouver la correspondance la plus proche, mais si vous comparez pixel par pixel, alors il est vraiment facile de…Si vous utilisez l’Autoencodeur pour d’abord compresser l’image dans l’espace latent et ensuite calculer la similarité sur l’espace latent de l’image, le résultat sera bien meilleur.Le résultat est bien meilleur car chaque dimension de l’espace latent peut représenter une certaine caractéristique.Si la distance est calculée sur l’espace latent, il est raisonnable de trouver des images similaires.En particulier, ce serait un excellent moyen d’apprentissage non supervisé, sans étiquetage des données !
Voici .L’article de Georey E. Hinton, le célèbre dieu du Deep Learning, montre le graphique que vous voulez rechercher dans le coin supérieur gauche, tandis que les autres sont tous des graphiques que l’autoencodeur pense être très similaires.7133>

les contenus.Recherche d’images
3-5. détection d’anomalies
Je ne peux pas trouver une bonne image, donc j’ai dû utiliser celle-ci LOL
La recherche d’anomalies est aussi un problème de fabrication super commun, donc ce problème peut aussi être essayé avec Autoencoder.Nous pouvons l’essayer avec Autoencoder !Tout d’abord, parlons de l’occurrence réelle des anomalies. Les anomalies se produisent généralement très rarement, par exemple, des signaux anormaux dans la machine, des pics de température soudains ……, etc.Cela se produit une fois par mois (si c’est plus, la machine devrait être mise à la retraite). Si les données sont collectées toutes les 10 secondes, alors 260 000 données seront collectées chaque mois, mais une seule période de temps correspond à des anomalies, ce qui est en fait une quantité très déséquilibrée de données.
Donc la meilleure façon de faire face à cette situation est d’aller chercher les données originales, qui sont la plus grande quantité de données que nous avons après tout !Si nous pouvons prendre les bonnes données et former un bon autoencodeur, alors si des anomalies apparaissent, alors naturellement les graphiques reconstruits se briseront.C’est ainsi qu’est née l’idée d’utiliser un autoencodeur pour trouver des anomalies !

.Implémentation
Ici, nous utilisons Mnist comme un exemple de jouet et implémentons un Autoencodeur en utilisant l’API de haut niveau de Tensorflow.keras ! Comme le nouveau paquet pour tf.keras a été publié sous peu, nous nous entraînons à utiliser la méthode de sous-classement Model dans le fichier.
4-1. Créer un modèle – Vallina_AE:
D’abord, importez tensorflow !7133>

L’utilisation de tf.keras est aussi simple que cela, il suffit de taper tf.keras !(Je ne sais pas de quoi je parle lol)
Load data & model preprocess
Tout d’abord nous prenons les données Mnist de tf.keras.dataset et faisons un petit pré-traitement
.Nomaliser : compresser les valeurs entre 0 et 1, l’entraînement sera plus facile à converger
Binarisation : mettre en évidence les zones les plus évidentes, l’entraînement donnera de meilleurs résultats.
Créer un modèle – Vallina_AE:
C’est la méthode fournie par le document Tensorflow pour créer des modèles.plus complexe.
Ce que j’ai appris jusqu’à présent, c’est de créer la couche à l’endroit __init __ et de définir la passe avant dans l’appel.
Nous utilisons donc deux modèles séquentiels pour créer l’encodeur & décodeur. deux sont une structure symétrique, l’encodeur est connecté à la couche d’entrée qui est responsable du transport des données d’entrée et ensuite aux trois couches denses. le décodeur est le même.
Encore une fois, sous l’appel, nous devons concaténer le codeur & décodeur, en définissant d’abord l’espace latent comme la sortie de self.encoder.espace comme la sortie de self.encoder, puis la reconstruction comme le résultat du passage du décodeur.Nous utilisons ensuite tf.keras.Model() pour connecter les deux modèles que nous avons définis dans __init__.AE_model = tf.keras.Model(inputs = self.encoder.input, outputs = reconstruction) spécifie l’entrée comme l’entrée de l’encodeur et la sortie comme la sortie du décodeur, et c’est tout !Ensuite, nous retournons le modèle AE_model et vous avez terminé !
Compilation du modèle & formation
Avant que Keras puisse former un modèle, il doit être compilé avant d’être déposé dans la formation.Dans la compilation, vous spécifiez l’optimiseur que vous voulez utiliser et la perte que vous voulez calculer.
Pour l’entraînement, utilisez VallinaAE.fit pour alimenter les données, mais n’oubliez pas que nous nous restaurons, donc X et Y doivent être lancés dans les mêmes données.
Regardons les résultats de l’entraînement de 100 époques, il semble que les résultats de la reconstruction ne soient pas aussi bons que nous le pensions.

4-2. Créer un modèle- Conv_AE:
Comme son nom l’indique, nous pouvons utiliser la couche de convolution comme une couche cachée pour apprendre des caractéristiques qui peuvent être reconstruites.
Après avoir changé le modèle, vous pouvez jeter un coup d’œil aux résultats pour voir s’il y a une amélioration.

Il semble que les résultats de la Reconstruction soient bien meilleurs, avec environ 10 époques d’entraînement.
4-3. Créer un modèle – denoise_AE:
De plus, l’autoencodeur peut être utilisé pour la suppression du bruit, donc ici nous…
D’abord, nous pouvons ajouter du bruit à l’image originale. La logique de l’ajout de bruit est de faire un simple décalage sur le pixel original et ensuite d’ajouter des nombres aléatoires.La partie de prétraitement de l’image peut être effectuée en rendant simplement le clip 0 s’il est plus petit que 0 et 1 s’il est plus grand que 1. Comme indiqué ci-dessous, après le traitement de l’image du clip, nous pouvons rendre l’image plus nette et les zones évidentes deviennent plus visibles.Cela nous donne un meilleur résultat lorsque nous lançons l’Autoencoder.

et le modèle lui-même et Conv_AE.Il n’y a aucune différence entre le modèle lui-même et Conv_AE, sauf que pendant l’ajustement, il doit être changé en
denoise_AE.fit(train_images_noise, train_images, epochs=100, batch_size=128, shuffle=True)
pour restaurer les données de bruit_données d’entrée originales

.
Comme vous pouvez le constater, sur Mnist, un simple Autoencodeur permet d’obtenir un effet de débruitage très rapide.
Grands exemples
C’est une bonne ressource pour ceux qui veulent en savoir plus
- Construire des autoencodeurs dans la série des autoencodeurs de Keras est clairement écrit.
- Tutoriel de la documentation officielle de Tensorflow 2.0, quelque chose de très complet, juste écrire un peu difficile, pour passer pas mal de temps à voir (au moins je tire XD)
3. Li Hongyi professeur d’apprentissage profond est également très recommandé, parler très clair et facile à comprendre, non-.
Conclusion
Utilisez cet article pour établir rapidement le concept de base de l’Autoencodeur, quelques variations de l’Autoencodeur et l’application de…scénarios.4310>
Les prochains articles commenceront par les modèles génératifs, en partant du concept d’autoencodeur, VAE, jusqu’au GAN, et d’autres extensions et morphes en cours de route.
Si vous aimez l’article, veuillez cliquer quelques applaudissements supplémentaires (pas seulement une fois) en guise d’encouragement !
Lisez le code complet de cet article:https://github.com/EvanstsaiTW/Generative_models/blob/master/AE_01_keras.ipynb
.
Laisser un commentaire