Comment utiliser Tesseract sur Windows
On janvier 14, 2022 by admin
Tesseract est un logiciel de reconnaissance optique de caractères qui a été développé par Google. C’est un outil d’OCR open source. Il existe de nombreuses versions de tesseract mais nous utiliserons la version 4.0.
Dans la version 4, Tesseract a mis en place un moteur de reconnaissance basé sur la mémoire à long terme (LSTM). LSTM est une sorte de réseau neuronal récurrent (RNN). La reconnaissance basée sur le LSTM fonctionne beaucoup plus efficacement que les anciens processus de reconnaissance (basés sur le CNN).
Grâce à tesseract, nous serons en mesure d’enregistrer le contenu de nos images en tant que fichiers texte.
Installation
L’isntallation dépend de votre système d’exploitation. Maintenant, nous allons passer en revue les fenêtres. Tout d’abord, téléchargeons et installons tesseract à travers ce lien. (Il télécharge un fichier exe.) Nous installons le fichier exe facilement.
Après cela, nous devrions ajouter un PATH aux variables système de windows. En fait, c’est une étape facile. Tout d’abord nous trouvons et copions le dossier racine de l’installation de tesseract. Il devra être comme ça :
C:\Program Files\Tesseract-OCR
Et ensuite dans la barre de recherche de windows Advanced System Settings
Advanced system settings > Advanced > Environment variables > PATH > New
On colle le chemin source qui a été copié et on sauvegarde ces configurations. Après cette étape, l’ordinateur doit être redémarré pour appliquer les configurations.
L’installation de tesseract est terminée. Vous pouvez confirmer l’installation à partir de la ligne de commande. Lorsque nous lançons la commande tesseract sur la ligne de commande, elle devrait nous donner des informations sur le programme.
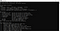
Nous pouvons maintenant passer à la partie python. Pour utiliser tesseract sur python, nous devons télécharger la bibliothèque pytesseract. Cette bibliothèque peut être téléchargée via pip dans l’environnement que vous utilisez.
pip install pytesseract
Maintenant le tesseract est prêt à être utilisé !
Codage
C’est vraiment simple d’utiliser le tesseract. La partie la plus difficile est l’optimisation des paramètres.
Parce que si vous voulez faire une ocr réussie, vous devez faire attention à l’étape de traitement de l’image et aux paramètres de l’ocr.
Appliquons l’ocr au reçu.

Importer les bibliothèques
import pytesseract
from PIL import Image
import cv2
import numpy as np
Définir la valeur DPI de l’image
Les points par pouce (DPI, ou dpi) est une mesure de la densité des points du scanner vidéo ou image. La valeur DPI est une chose importante pour exécuter l’OCR. Parce que si la valeur DPI est inférieure à 300, cela peut réduire le succès de l’OCR.
file_path= 'receipt.jpg'
im = Image.open(file_path)
im.save('ocr.png', dpi=(300, 300))
Application de quelques techniques pour rendre l’image plus propre
D’abord nous mettons notre image à l’échelle avec x2. Si les caractères sont petits alors nous devons mettre à l’échelle l’image pour la reconnaître. Après cela, nous appliquons une technique simple de seuil. C’est le seuil binaire. Tout d’abord, vous devez essayer avec la valeur 127, puis différentes variables peuvent être essayées. Le seuil change le pixel en noir si la valeur du pixel est supérieure à la valeur du seuil. Si nous faisons l’image en niveaux de gris, cela nous donnera une image en noir et blanc.
Il existe différentes techniques de seuil. Vous pouvez vérifier le site web source avec ce lien.

Exécution de Tesseract
Maintenant nous pouvons exécuter tesseract. Il a une fonction image_to_string(). Elle nous donne une chaîne de caractères comme sortie.
text = pytesseract.image_to_string(treshold)
Sauvegarder la sortie
Nous pouvons sauvegarder la sortie avec le code suivant.
with open("Output.txt", "w",5 ,"utf-8") as text_file:
text_file.write(text)
La sortie de l’OCR est la suivante:
Le résultat est très réussi. Si un succès plus élevé est souhaité, différentes opérations peuvent être appliquées à l’image.
Laisser un commentaire