Comment fonctionne le web
On octobre 15, 2021 by adminLe web est partout !
Nous l’utilisons plus que jamais auparavant – également dans de nombreux endroits où vous ne le verrez peut-être pas. Parce que « le web » est plus que de simples sites web que vous visitez en entrant une URL dans votre navigateur.
Qu’importe si vous vérifiez vos e-mails sur votre téléphone portable ou si vous envoyez un tweet – vous utilisez l’internet (c’est-à-dire « le web »).
Comment tout cela fonctionne-t-il ? Quelles technologies sont impliquées et que devez-vous apprendre (et dans quelle mesure) si vous voulez devenir un développeur web ?
Dans cet article et dans la vidéo (voir ci-dessus), je ne vais pas plonger dans tous les détails techniques. C’est censé être un bon aperçu de la fonctionnalité web.

CSS – Le guide complet
Rejoignez ce cours complet de 20h+ pour maîtriser CSS et apprendre à créer de beaux sites web.

JavaScript – Le guide complet
Apprenez JavaScript à partir de zéro pour construire des sites web hautement interactifs et dynamiques dans ce cours pratique !
# Comment fonctionnent les sites web
Commençons par la façon la plus évidente d’utiliser Internet : Vous visitez un site web comme academind.com.
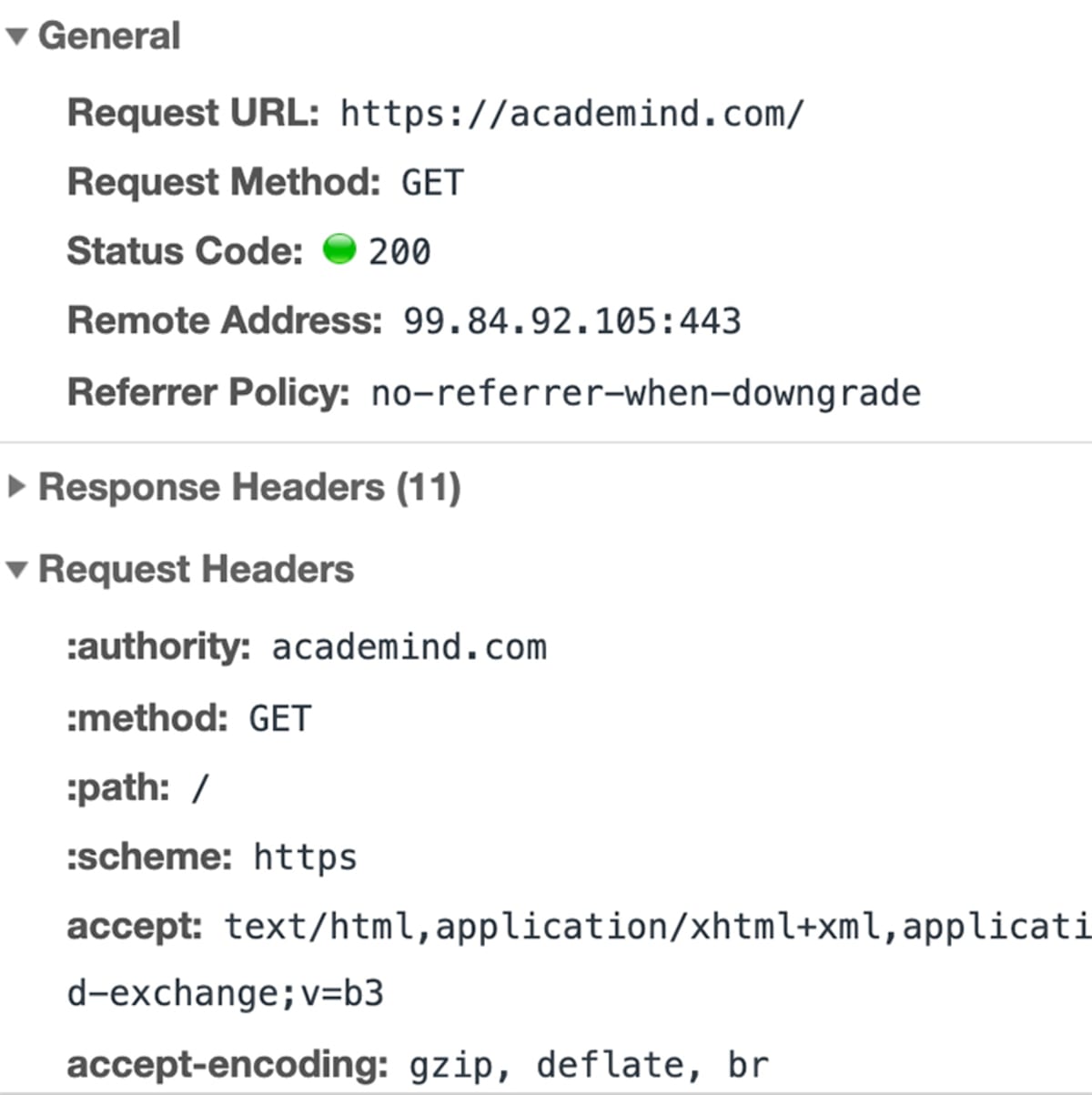
A partir du moment où vous entrez cette adresse dans votre navigateur et que vous appuyez sur ENTRÉE, beaucoup de choses différentes se produisent :
- L’URL est résolue
- Une requête est envoyée au serveur du site web
- La réponse du serveur est analysée
- La page est rendue et affichée

En fait, chaque étape pourrait être divisée en plusieurs autres étapes, mais pour une bonne vue d’ensemble de la façon dont tout cela fonctionne, c’est quelque chose que nous pouvons ignorer ici. Jetons un coup d’œil aux quatre étapes.
Étape 1 – L’URL est résolue
Le code du site Web n’est évidemment pas stocké sur votre machine et doit donc être récupéré sur un autre ordinateur où il est stocké. Cet « autre ordinateur » s’appelle un « serveur ». Parce qu’il sert à quelque chose, dans notre cas, il sert le site web.
Vous entrez dans « academind.com ». (c’est ce qu’on appelle « un domaine ») mais en réalité, le serveur qui héberge le code source d’un site web, est identifié via des adresses IP (= Internet Protocol). Le navigateur envoie une « requête » (voir étape 2) au serveur avec l’adresse IP que vous avez saisie (indirectement – vous avez bien sûr saisi « academind.com »).
En réalité, vous saisissez aussi souvent "academind.com/learn" ou quelque chose comme ça. "academind.com" est le domaine, "/learn" est ce qu’on appelle le chemin. Ensemble, ils constituent l' »URL » (« Uniform Resource Locator »).
En outre, vous pouvez visiter la plupart des sites web via "www.academind.com" ou seulement "academind.com". Techniquement, "www" est un sous-domaine mais la plupart des sites web redirigent simplement le trafic vers "www" vers la page principale.
Une adresse IP ressemble généralement à ceci : 172.56.180.5 (bien qu’il existe également une forme plus « moderne » appelée IPv6 – mais ignorons cela pour le moment). Vous pouvez en savoir plus sur les adresses IP sur Wikipedia.
Comment le domaine « academind.com » est traduit en son adresse IP ?
Il existe un type spécial de serveur sur Internet – pas seulement un mais plusieurs serveurs de ce type. Un serveur dit « serveur de noms » ou « serveur DNS » (où DNS = « Domain Name System »).
Le travail de ces serveurs DNS consiste à traduire les domaines en adresses IP. Vous pouvez imaginer ces serveurs comme d’énormes dictionnaires qui stockent des tables de traduction : Domaine => adresse IP.
Lorsque vous saisissez « academind.com », le navigateur va donc d’abord chercher l’adresse IP auprès d’un tel serveur DNS.
Au cas où vous vous poseriez la question : Le navigateur connaît les adresses de ces serveurs de domaine par cœur, elles sont programmées dans le navigateur pour ainsi dire.
Une fois l’adresse IP connue, nous avons avancé à l’étape 2.
Étape 2 – La requête est envoyée
Avec l’adresse IP résolue, le navigateur va de l’avant et fait une requête au serveur avec cette adresse IP.
« Une requête » n’est pas juste un terme. C’est vraiment une chose technique qui se passe dans les coulisses.
Le navigateur regroupe un ensemble d’informations (Quelle est l’URL exacte ? Quel type de requête doit être effectué ? Faut-il joindre des métadonnées) et envoie ce paquet de données à l’adresse IP.
Les données sont envoyées via le « HyperText Transfer Protocol » (connu sous le nom de « HTTP ») – un protocole standardisé qui définit à quoi doit ressembler une demande (et une réponse), quelles données peuvent être incluses (et sous quelle forme) et comment la demande sera soumise. Vous pouvez en savoir plus sur le protocole HTTP ici.
Parce que le protocole HTTP est utilisé, une URL complète ressemble en fait à ceci : http://academind.com. Le navigateur la complète automatiquement pour vous.
Et il y a aussi HTTPS – c’est comme HTTP mais crypté. La plupart des pages modernes (y compris academind.com) l’utilisent à la place de HTTP. Une URL complète devient alors : https://academind.com.
Puisque tout le processus et le format sont normalisés, il n’y a pas à deviner comment cette requête doit être lue par le serveur.
Le serveur traite alors la requête de manière appropriée et renvoie ce qu’on appelle une « réponse ». Encore une fois, une « réponse » est une chose technique et un peu similaire à une « demande ». Vous pourriez dire que c’est essentiellement une « demande » dans la direction opposée.
Comme une demande, une réponse peut contenir des données, des métadonnées, etc. Lors de la demande d’une page comme academind.com, la réponse contiendra le code qui est nécessaire pour rendre la page sur l’écran.
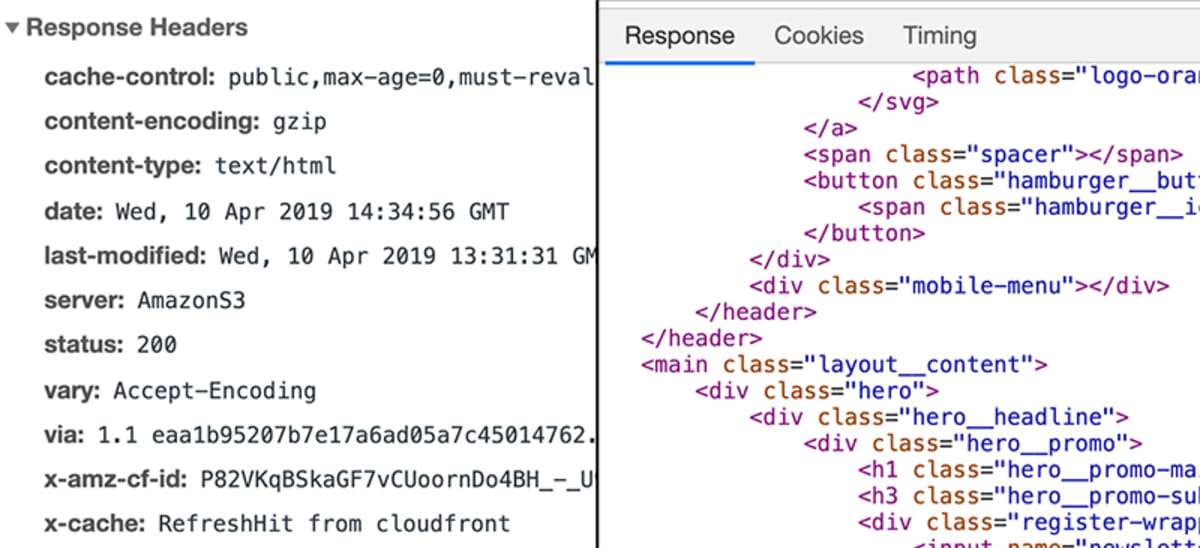
Que se passe-t-il sur le serveur ?
Ceci est défini par les développeurs web. Au final, une réponse doit être envoyée. Cette réponse ne doit pas nécessairement contenir « un site web ». Elle peut contenir n’importe quelle donnée – y compris des fichiers ou des images.
Certains serveurs sont programmés pour générer des sites web de manière dynamique en fonction de la demande (par exemple une page de profil qui contient vos données personnelles), d’autres serveurs renvoient des pages HTML pré-générées (par exemple une page d’actualité). Ou encore, on fait les deux – pour différentes parties d’une page web. Il existe également une troisième solution : Les sites web qui sont pré-générés mais qui changent leur apparence et leurs données dans le navigateur.
Les différents types de sites web ne sont pas vraiment le sujet de cet article. Si vous voulez en savoir plus, consultez cet article + vidéo.
Pour notre cas simple, nous avons un serveur qui renvoie le code pour afficher un site web. Alors continuons avec l’étape 3.
Étape 3 – La réponse est analysée
Le navigateur reçoit la réponse envoyée par le serveur. Cela seul, n’affiche rien à l’écran cependant.
Au contraire, l’étape suivante est que le navigateur analyse la réponse. Tout comme le serveur l’a fait avec la requête. Encore une fois, la normalisation imposée par HTTP aide bien sûr.
Le navigateur vérifie les données et les métadonnées qui sont incluses dans la réponse. Et en fonction de cela, il décide de ce qu’il faut faire.
Vous avez peut-être eu des cas où un PDF s’est ouvert dans votre navigateur. Cela s’est produit parce que la réponse a informé le navigateur que les données ne sont pas un site Web, mais plutôt un document PDF. Et le navigateur essaie de choisir le meilleur mécanisme de traitement pour tout type de données qu’il détecte.
Retour à notre scénario de site web.
Dans ce cas, la réponse contiendrait un élément spécifique de métadonnées, qui indique au navigateur que les données de la réponse sont de type text/html.
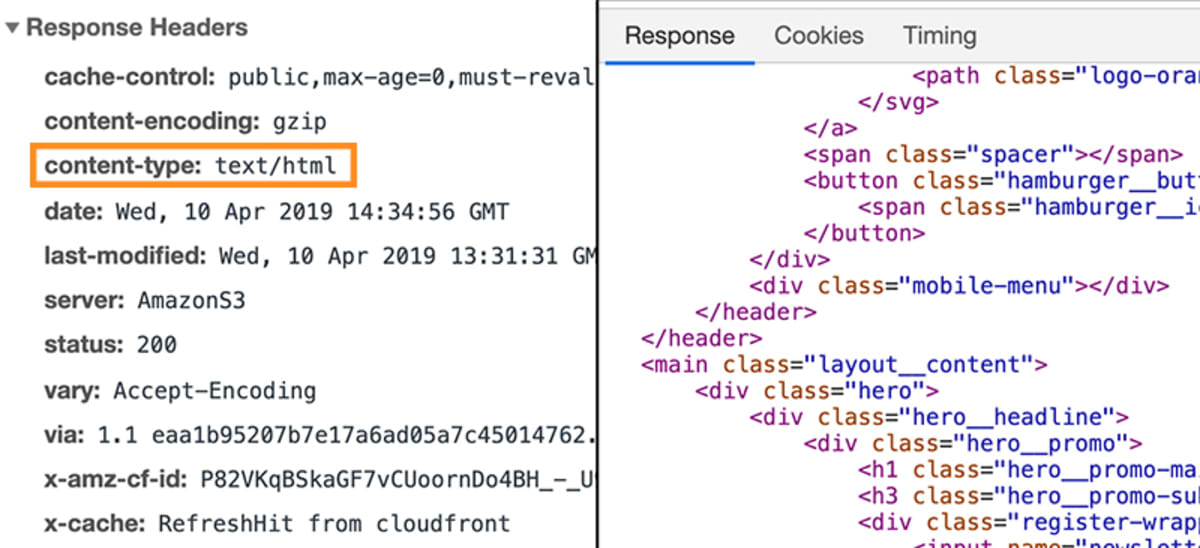
Ceci permet au navigateur d’analyser ensuite les données réelles qui sont attachées à la réponse sous forme de code HTML.
Le HTML est le « langage de programmation » de base (techniquement, ce n’est pas un langage de programmation – vous ne pouvez pas écrire de logique avec) du web. HTML signifie « Hyper Text Markup Language » et décrit la structure d’une page web.
Le code ressemble à ceci:
<h1>Breaking News!</h1><p>Websites work because browser understand HTML!</p><h1> et <p> sont ce qu’on appelle des « balises HTML » et si vous voulez en savoir plus sur le HTML, cette série est un excellent endroit pour aller.
Chaque balise HTML a une certaine signification sémantique que le navigateur comprend, parce que le HTML est également normalisé. Par conséquent, il n’y a pas à deviner ce que signifie une balise <h1>.
Le navigateur sait comment analyser le HTML et il suffit maintenant de parcourir l’ensemble des données de la réponse (également appelé « le corps de la réponse ») pour rendre le site Web.
Étape 4 – La page est affichée
Comme mentionné, le navigateur parcourt les données HTML renvoyées par le serveur et construit un site web sur cette base.
Il est important de savoir, que le HTML ne comprend aucune instruction concernant l’aspect du site (c’est-à-dire comment il doit être stylé). Il ne fait que définir la structure et indiquer au navigateur quel contenu est un titre, quel contenu est une image, quel contenu est un paragraphe, etc. C’est particulièrement important pour l’accessibilité – les lecteurs d’écran récupèrent toutes les informations utiles de la structure HTML.
Une page qui ne comprendrait que du HTML ressemblerait cependant à ceci :

Pas si beau, non ?
C’est pourquoi il existe une autre technologie importante (un autre « langage de programmation », qui n’en est pas vraiment un) : CSS (« Cascading Style Sheets »).
CSS consiste à ajouter du style au site web. Cela se fait par le biais de « règles CSS »:
h1 { color: blue;}Cette règle colorerait toutes les balises <h1> en bleu.
Des règles comme celle-ci peuvent être ajoutées à l’intérieur du code HTML, mais typiquement, elles font partie de fichiers .css distincts qui sont demandés séparément.
Sans plonger dans trop de détails ici, cela détient une implication importante : Un site web peut être composé de plus que les données de la première réponse que nous recevons.
En pratique, les sites web récupèrent beaucoup de données supplémentaires (via des demandes et des réponses supplémentaires) qui sont lancées une fois que la première réponse est arrivée.
Comment cela fonctionne-t-il ?
Eh bien, le code HTML de la première réponse contient simplement des instructions pour aller chercher plus de données via de nouvelles requêtes – et le navigateur comprend ces instructions :
<link rel="stylesheet" href="/page-styles.css" />
Encore, je ne vais pas plonger dans plus de détails ici. Si vous voulez en savoir plus sur les CSS, notre Guide complet vous sera très utile!
Avec les CSS, le navigateur est capable d’afficher des pages web comme ceci:

Il y a en fait un autre langage de programmation impliqué (cette fois, c’est vraiment un langage de programmation !): JavaScript.
Ce n’est pas toujours visible mais tout le contenu dynamique que vous trouvez sur un site web (par exemple, les onglets, les superpositions, etc.) n’est en fait possible que grâce à JavaScript. Il permet aux développeurs web de définir un code qui s’exécute dans le navigateur (et non sur le serveur), d’où la possibilité d’utiliser JavaScript pour modifier le site web pendant que l’utilisateur le consulte.
Comme précédemment, si vous voulez en savoir plus, consultez nos ressources JavaScript, par exemple notre cours complet.
Ce sont les quatre étapes qui sont toujours impliquées lorsque vous entrez une adresse de page comme academind.com et que vous voyez par la suite le contenu du site web dans votre navigateur.
# Server-side vs Browser-side
Depuis les quatre étapes ci-dessus, vous avez appris que nous pouvons différencier deux « côtés » fondamentaux lorsque nous parlons du web : Côté serveur et Côté navigateur (ou : Côté client puisque nous pouvons également accéder à Internet sans navigateur – voir ci-dessous !).
Si vous souhaitez devenir développeur web, il est important de savoir que vous utilisez différentes technologies et langages de programmation pour ces côtés.
Côté serveur
Vous avez besoin de langages de programmation côté serveur – c’est-à-dire des langages qui ne fonctionnent pas dans le navigateur mais qui peuvent fonctionner sur un ordinateur normal (un serveur n’est finalement qu’un ordinateur normal).
Des exemples seraient :
- Node.js
- PHP
- Python
Important : à l’exception de PHP, vous pouvez également utiliser ces langages de programmation à d’autres fins que le développement web.
Alors que Node.js est en effet principalement utilisé pour la programmation côté serveur (bien qu’il ne soit techniquement pas limité à cela), Python est également très populaire pour la science des données et l’apprentissage automatique.
Côté navigateur
Dans le navigateur, il y a exactement trois langages/technologies que vous devez apprendre. Mais alors que les langages côté serveur étaient des alternatives, ces trois langages côté navigateur sont tous obligatoires à connaître et à comprendre :
- HTML (pour la structure)
- CSS (pour le style)
- JavaScript (pour le contenu dynamique)
# « Behind the Scenes » Internet
Jusqu’ici, nous avons discuté des sites Web. C’est-à-dire le cas où vous entrez une URL (par exemple « academind.com/learn ») dans le navigateur et vous obtenez un site web en retour.
Mais Internet est plus que cela. En effet, vous l’utilisez pour plus que cela tous les jours !
L’idée centrale des demandes et des réponses est toujours la même. Mais toutes les réponses ne sont pas nécessairement des sites web. Et toutes les demandes ne veulent pas un site web.
Les métadonnées qui sont attachées aux demandes et aux réponses contrôlent quelles données sont voulues et retournées. Bien sûr, les deux parties qui sont impliquées (c’est-à-dire le client et le serveur) doivent supporter les demandeurs et les données envoyées.
Vous ne pouvez pas demander un PDF à "academind.com" par exemple. Vous pourriez envoyer une telle demande mais vous ne recevriez pas de PDF en retour – simplement parce que nous ne supportons pas ce type de données demandées pour cette URL spécifique.
Mais il existe de nombreux serveurs spécialisés dans la fourniture d’URL qui renvoient certains éléments de données. Ces services sont également appelés « API » (« Application Programming Interface »).
Par exemple, les applications mobiles envoient des requêtes HTTP « invisibles » à ces API (à des URL spécifiques qui leur sont connues) pour obtenir ou stocker des données. Twitter récupère le flux de tweets par exemple.
Et même sur les pages web, de telles requêtes « invisibles » sont envoyées. Si vous vous inscrivez à notre bulletin d’information (ce que vous devriez bien sûr faire !), aucune nouvelle page ne sera chargée. Car les données sont échangées en coulisses. Même si le client est le navigateur dans ce cas, la demande envoyée ne veut pas de site web en retour. Et l’URL du serveur qui la reçoit n’offre aucun site web – au lieu de cela, le serveur sait comment gérer votre adresse e-mail.
Nous pourrions entrer dans beaucoup plus de détails ici mais c’est déjà un long article. Vous devriez maintenant avoir une bonne compréhension du fonctionnement du web et des technologies de base impliquées.
Laisser un commentaire