SQL CHIT CHAT … Blog sobre Sql Server
On noviembre 29, 2021 by adminResumen
Las Expresiones de Tabla Comunes fueron introducidas en SQL Server 2005. Representan uno de los varios tipos de expresiones de tabla disponibles en Sql Server. Una CTE recursiva es un tipo de CTE que hace referencia a sí misma. Suele utilizarse para resolver jerarquías.
En este post intentaré explicar cómo funciona la recursión CTE, dónde se sitúa dentro del grupo de expresiones de tabla disponibles en Sql Server y unos cuantos escenarios de casos en los que la recursión brilla.
Expresiones de tabla
Una expresión de tabla es una expresión de consulta con nombre que representa una tabla relacional. Sql Server admite cuatro tipos de expresiones de tabla;
- Tablas derivadas
- Vistas
- ITVF (Inline Table Valued Functions aka parameterised views)
- CTE (Common Table Expressions)
- CTE recursivo
En general, las expresiones de tabla no se materializan en el disco. Son tablas virtuales presentes sólo en la memoria RAM (pueden derramarse al disco como resultado de, por ejemplo, la presión de la memoria, el tamaño de una tabla virtual, etc.). La visibilidad de las expresiones de tabla puede variar, es decir, las vistas y los ITVF son objetos de la base de datos visibles a nivel de la base de datos, mientras que su alcance es siempre a nivel de sentencia SQL – las expresiones de tabla no pueden operar a través de diferentes sentencias sql dentro de un lote.
Las ventajas de las expresiones de tabla no están relacionadas con el rendimiento de la ejecución de la consulta, sino con el aspecto lógico del código
Tablas derivadas
Las tablas derivadas son expresiones de tabla también conocidas como subconsultas. Las expresiones se definen en la cláusula FROM de una consulta externa. El ámbito de las tablas derivadas es siempre la consulta externa.
El siguiente código representa una tabla derivada llamada AUSCust.
Transact-SQL
|
1
2
3
4
5
6
7
8
|
SELECT AUSCust.*
FROM (
SELECT custid
,companyname
FROM dbo.Customers
WHERE country = N’Australia’
) AS AUSCust;
–AUSCust es una tabla derivada
|
La tabla derivada AUSCust sólo es visible para la consulta externa y el alcance se limita a la sentencia sql.
Vistas
Las vistas (a veces denominadas relaciones virtuales) son expresiones de tabla reutilizables. La definición de una vista se almacena como un objeto de Sql Server junto con objetos como: tablas definidas por el usuario, disparadores, funciones, procedimientos almacenados, etc.
La principal ventaja de las vistas sobre otros tipos de expresiones de tabla es su reutilización, es decir, las consultas derivadas y las CTE tienen un alcance limitado a una única sentencia.
Las vistas no se materializan, lo que significa que las filas producidas por las vistas no se almacenan permanentemente en el disco. Las vistas indexadas en Sql Server (similares pero no iguales a las vistas materializadas en otras plataformas db) son un tipo especial de vistas que pueden tener su conjunto de resultados almacenados permanentemente en el disco – se puede encontrar más información sobre las vistas indexadas aquí.
Sólo unas pocas directrices básicas sobre cómo definir Vistas SQL.
-
SELECT * en el contexto de una definición de Vista se comporta de manera diferente que cuando se utiliza como un elemento de consulta en un lote.
Transact-SQL
12345CREATE VIEW dbo.vwTestASSELECT *FROM dbo.T1…La definición de la vista incluirá todas las columnas de la tabla subyacente, dbo.T1 en el momento de la creación de la vista. Esto significa que si cambiamos el esquema de la tabla (es decir, añadimos y/o eliminamos columnas) los cambios no serán visibles para la vista – la definición de la vista no cambiará automáticamente para soportar los cambios de la tabla. Esto puede causar errores en situaciones en las que, por ejemplo, una vista intente seleccionar columnas inexistentes de una tabla subyacente.
Para solucionar el problema, podemos uno de los dos procedimientos del sistema: sys.sp_refreshview o sys.sp_refreshsqlmodule.
Para evitar este comportamiento siga la mejor práctica y nombre explícitamente las columnas en la definición de la vista. - Las vistas son expresiones de tabla y por lo tanto no pueden ser ordenadas. Las vistas no son cursores. Es posible, sin embargo, «abusar» de la construcción TOP/ORDER BY en la definición de la vista para intentar forzar una salida ordenada. ej. .
Transact-SQL
12345CREATE VIEW dbo.MyCursorViewASSELECT TOP(100 PERCENT) *FROM dbo.SomeTableORDER BY column1 DESCEl optimizador de consultas descartará el TOP/ORDER BY ya que el resultado de una expresión de tabla es siempre una tabla – seleccionar TOP(100 PERCENT) no tiene ningún sentido de todos modos. La idea detrás de las estructuras de tabla se deriva de un concepto en la teoría de bases de datos relacionales conocido como relación.
-
Durante el procesamiento de una consulta que hace referencia a una vista, la consulta de la definición de la vista se despliega o expande y se implementa en el contexto de la consulta principal. El código consolidado (consulta) será entonces optimizado y ejecutado.
ITVF (Inline Table Valued Functions)
Las ITVFs son expresiones de tabla reutilizables que soportan parámetros de entrada. Las funciones pueden tratarse como vistas parametrizadas.
CTE (Common Table Expressions)
Las expresiones de tabla comunes son similares a las tablas derivadas pero con varias ventajas importantes;
Una CTE se define utilizando una sentencia WITH, seguida de una definición de expresión de tabla. Para evitar la ambigüedad (TSQL utiliza la palabra clave WITH para otros propósitos, por ejemplo, WITH ENCRYPTION, etc.) la declaración que precede a la cláusula WITH de la CTE DEBE terminar con una semicolumna. Esto no es necesario si la cláusula WITH es la primera sentencia en un lote, es decir, en una definición de VIEW/ITVF)
NOTA: La semicolumna, el terminador de la sentencia, está soportada por el estándar ANSI y se recomienda encarecidamente su uso como parte de la práctica de programación TSQL.
CTE recursivo
SQL Server soporta las capacidades de consulta recursiva implementadas a través de CTEs recursivos desde la versión 2005(Yukon).
Elementos de una CTE recursiva
- Miembro(s) ancla(s) – Las definiciones de consulta que;
- devuelven una tabla de resultados relacional válida
- se ejecutan SOLO UNA VEZ al principio de la ejecución de la consulta
- se posicionan siempre antes de la definición del primer miembro recursivo
- el último miembro ancla debe ir seguido del operador UNION ALL. El operador combina el último miembro ancla con el primer miembro recursivo
- operador UNION ALL multi-set. El operador opera sobre
- Miembro(s) recursivo(s) – Las definiciones de consulta que;
- devuelven una tabla de resultados relacional válida
- tienen referencia al nombre CTE. La referencia al nombre del CTE representa lógicamente el conjunto de resultados anterior en una secuencia de ejecuciones. es decir, el primer conjunto de resultados «anterior» en una secuencia es el resultado que devolvió el miembro ancla.
- Invocación del CTE – Sentencia final que invoca la recursividad
- Mecanismo a prueba de fallos – La opción MAXRECURSION evita que el sistema de base de datos realice bucles infinitos. Este es un elemento opcional.
Comprobación de terminación
El miembro recursivo de CTE no tiene una comprobación explícita de terminación de la recursión.
En muchos lenguajes de programación, podemos diseñar un método que se llama a sí mismo – un método recursivo. Cada método recursivo necesita ser terminado cuando se satisfacen ciertas condiciones. Esto es la terminación explícita de la recursión. Después de este punto el método comienza a devolver valores. Sin punto de terminación la recursión puede terminar llamándose a sí misma «sin fin».
La comprobación de terminación de miembros recursivos de CTE es implícita , lo que significa que la recursión se detiene cuando no se devuelven filas de la ejecución anterior de CTE.
Aquí hay un ejemplo clásico de una recursión en programación imperativa. El código de abajo calcula el factorial de un entero usando una llamada a una función(método) recursiva.
El código completo del programa de consola se puede encontrar aquí.
MAXRECURSION
Como se mencionó anteriormente, los CTEs recursivos así como cualquier operación recursiva pueden causar bucles infinitos si no se diseñan correctamente. Esta situación puede tener un impacto negativo en el rendimiento de la base de datos. El motor de Sql Server tiene un mecanismo de seguridad que no permite ejecuciones infinitas.
Por defecto, el número de veces que el miembro recursivo puede ser invocado está limitado a 100 (esto no cuenta la ejecución de anclaje una vez). El código fallará en la 101ª ejecución del miembro recursivo.
Msg 530, Nivel 16, Estado 1, Línea xxx
La sentencia ha terminado. La recursión máxima 100 se ha agotado antes de la finalización de la sentencia.
El número de recursividades se gestiona mediante la opción de consulta MAXRECURSION n. La opción puede anular el número predeterminado de recurrencias máximas permitidas. El parámetro (n) representa el nivel de recursión. 0<=n <=32767
Nota importante:: MAXRECURSION 0 – ¡desactiva el límite de recursión!
La figura 1 muestra un ejemplo de una CTE recursiva con sus elementos

Figura 1, Elementos de la CTE recursiva
La recursión declarativa es bastante diferente a la recursión tradicional, imperativa. Aparte de la diferente estructura del código, podemos observar la diferencia entre la comprobación de terminación explícita e implícita. En el ejemplo de CalculateFactorial, el punto de terminación explícito está claramente definido por la condición: if (number == 0) then return 1.
En el caso de la CTE recursiva anterior, el punto de terminación está implícitamente definido por la operación INNER JOIN, más concretamente por el resultado de la expresión lógica en su cláusula ON: ON e.MgrId = c.EmpId. El resultado de la operación de la tabla dirige el número de recurrencias. Esto quedará más claro en las siguientes secciones.
Utilizar CTE recursivos para resolver la jerarquía de Empleados
Hay muchos escenarios en los que podemos utilizar CTEs recursivos, es decir, para separar elementos, etc. El escenario más común con el que me he encontrado durante muchos años de secuenciación ha sido utilizar CTE recursivos para resolver varios problemas jerárquicos.
La jerarquía de árboles de Empleados es un ejemplo clásico de un problema jerárquico que se puede resolver utilizando CTEs recursivos.
Ejemplo
Supongamos que tenemos una organización con 12 empleados. Se aplican las siguientes reglas de negocio;
- Un empleado debe tener un id único, EmpId
- reforzado por: Restricción de clave primaria en la columna EmpId
- Un empleado puede ser manejado por 0 o 1 gerente.
- reforzado por: PK en EmpId, FK en MgrId y columna MgrId nula
- Un gerente puede gestionar uno o más empleados.
- reforzado por: Restricción de clave foránea (auto-referenciada) en la columna MgrId
- Un gerente no puede gestionarse a sí mismo.
- reforzada por: CHECK constraint on MgrId column
La jerarquía de árbol se implementa en una tabla llamada dbo.Employees. Los scripts se pueden encontrar aquí.

Figura 2, tabla Empleados
Presentemos la forma en que operan los CTE recursivos respondiendo a la pregunta: ¿Quiénes son los subordinados directos e indirectos del gerente con EmpId = 3?
Desde el árbol jerárquico de la Figura 2 podemos ver claramente que el Gerente (EmpId = 3) gestiona directamente a los empleados; EmpId=7, EmpId=8 y EmpId=9 y gestiona indirectamente; EmpId=10, EmpId=11 y EmpId=12.
La Figura 3 muestra la jerarquía EmpId=3 y el resultado esperado. El código se puede encontrar aquí.

Figura 3, EmpId=3 subordinados directos e indirectos
Entonces, cómo conseguimos el resultado final.
La parte recursiva en la iteración actual siempre hace referencia a su resultado previo de la iteración anterior. El resultado es una expresión de tabla(o tabla virtual) llamada cte1(la tabla del lado derecho del INNER JOIN). Como podemos ver, cte1 contiene también la parte de anclaje. En la primera ejecución (la primera iteración), la parte recursiva no puede hacer referencia a su resultado anterior porque no había ninguna iteración anterior. Por eso en la primera iteración sólo se ejecuta la parte de anclaje y sólo una vez en todo el proceso. El conjunto de resultados de la consulta ancla proporciona a la parte recursiva su resultado anterior en la segunda iteración. El ancla actúa como un volante si se quiere 🙂
El resultado final se acumula a través de iteraciones es decir Resultado del ancla + resultado de la iteración 1 + resultado de la iteración 2 …
La secuencia lógica de ejecución
La consulta de prueba se ejecuta siguiendo la secuencia lógica siguiente:
- La sentencia SELECT fuera de la expresión cte1 invoca la recursión. La consulta ancla se ejecuta y devuelve una tabla virtual llamada cte1. La parte recursiva devuelve una tabla vacía ya que no tiene su resultado anterior. Recuerda que las expresiones en el enfoque basado en conjuntos se evalúan todas a la vez.
 Figura 4, valor de cte1 tras la 1ª iteración
Figura 4, valor de cte1 tras la 1ª iteración - Comienza la segunda iteración.Esta es la primera recursión. La parte de anclaje hizo su parte en la primera iteración y a partir de ahora devuelve sólo conjuntos vacíos. Sin embargo, la parte recursiva puede ahora hacer referencia a su resultado anterior (valor de cte1 después de la primera iteración) en el operador INNER JOIN. La operación de tabla produce el resultado de la segunda iteración como se muestra en la figura siguiente.
 FIgure 5, valor de cte1 después de la segunda iteración
FIgure 5, valor de cte1 después de la segunda iteración - La segunda iteración produce un conjunto no vacío, por lo que el proceso continúa con la tercera iteración – la segunda recursión. El elemento recursivo ahora hace referencia al resultado cte1 de la segunda iteración.
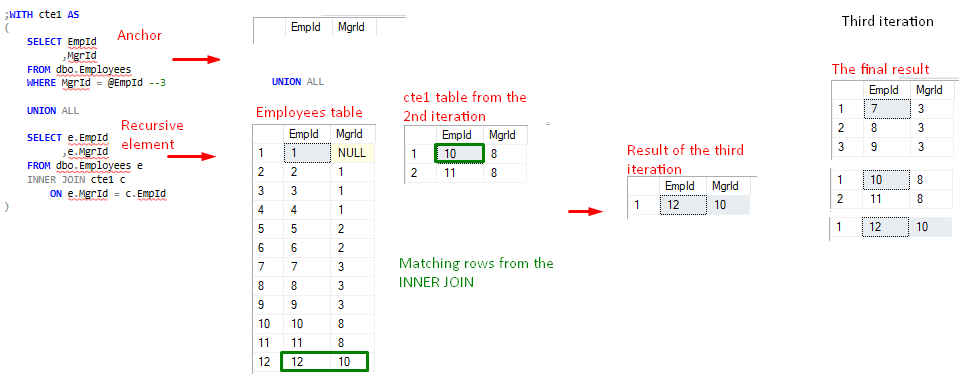
Figura 6, valor de cte1 después de la tercera iteración - En la cuarta iteración -el tercer intento de recursión- ocurre algo interesante. Siguiendo el patrón anterior, el elemento recursivo utiliza el resultado cte1 de la iteración anterior. Sin embargo, esta vez no hay filas devueltas como resultado de la operación INNER JOIN, y el elemento recursivo devuelve un conjunto vacío. Este es el punto de terminación implícito mencionado anteriormente. En este caso, la evaluación de la expresión lógica de INNER JOIN dicta el número de recursiones.
Debido a que el último resultado de cte1 es un conjunto de resultados vacío, la 4ª iteración (o 3ª recursión) se «cancela» y el proceso finaliza con éxito.
Figura 7, La iteración final
La cancelación lógica de la 3ª recursión (la última recursión que produjo un conjunto de resultados vacío no cuenta) quedará más clara en la siguiente sección de análisis del plan de ejecución del CTE recursivo.Podemos añadir la opción de consulta OPTION(MAXRECURSION 2) al final de la consulta que limitará el número de recursiones permitidas a 2. La consulta producirá el resultado correcto demostrando que sólo se requieren dos recursiones para esta tarea.Nota: Desde el punto de vista de la ejecución física, el conjunto de resultados se envía progresivamente (a medida que las filas suben) a los búferes de la red y de vuelta a la aplicación cliente.
Por último, la respuesta a la pregunta anterior es :
Hay seis empleados que dependen directa o indirectamente del Emp=3. Tres empleados, EmpId= 7, EmpId=8 y EmpId=9 son subordinados directos y EmpId=10, EmpId=11 y EmpId=12 son subordinados indirectos.
Conociendo la mecánica del CTE recursivo, podemos resolver fácilmente los siguientes problemas.
- Buscar todos los empleados que están jerárquicamente por encima del EmpId = 10 (codificar aquí)
- Buscar los subordinados directos y de segundo nivel del EmpId=8(codificar aquí)
En el segundo ejemplo controlamos la profundidad de la jerarquía restringiendo el número de recursiones.
El elemento ancla nos da el primer nivel de jerarquía, en este caso, los subordinados directos. Cada recursión se mueve entonces un nivel de jerarquía hacia abajo desde el primer nivel. En el ejemplo, el punto de partida es EmpId=8 y sus subordinados directos. La primera recursión se mueve un nivel más abajo en la jerarquía donde «viven» los subordinados de segundo nivel de EmpId=8.
Problema de la referencia circular
Una de las cosas interesantes de las jerarquías es que los miembros de una jerarquía pueden formar un bucle cerrado donde el último elemento de la jerarquía hace referencia al primer elemento. El bucle cerrado también se conoce como referencia circular.
En los casos como este, el punto de terminación implícito, como la operación INNER JOIN explicada anteriormente, simplemente no funcionará porque siempre devolverá un conjunto de resultados no vacío para que la siguiente recursión continúe. La parte de la recursión seguirá rodando hasta que llegue a la seguridad de Sql Server, la opción de consulta MAXRECURSION.
Para demostrar la situación de referencia circular utilizando el entorno de prueba previamente configurado, necesitaremos
- Eliminar las restricciones de clave primaria y foránea de la tabla dbo.Employees para permitir los escenarios de bucles cerrados.
- Crear una referencia circular (EmpId=10 manejará a su gerente indirecto , EmpId = 3)
- Extender la consulta de prueba utilizada en los ejemplos anteriores, para poder analizar la jerarquía de los elementos en el bucle cerrado.
La consulta de prueba extendida se puede encontrar aquí.
Antes de continuar con el ejemplo de la ref. circular, veamos cómo funciona la consulta de prueba extendida. Comente los predicados de la cláusula WHERE (las dos últimas líneas) y ejecute la consulta contra la tabla original dbo.Employee
 Figura 8, Detección de la existencia de bucles circulares en jerarquías
Figura 8, Detección de la existencia de bucles circulares en jerarquías
El resultado de la consulta extendida es exactamente el mismo que el resultado presentado en el experimento anterior en la Figura 3. La salida se amplía para incluir las siguientes columnas
- pth – Representa gráficamente la jerarquía actual. Inicialmente, dentro de la parte de anclaje, simplemente añade el primer subordinado a MgrId=3, el gestor del que partimos. Ahora, cada elemento recursivo toma el valor anterior de pth y le añade el siguiente subordinado.
- recLvl – representa el nivel actual de recursión. La ejecución del ancla se cuenta como recLvl=0
- isCircRef – detecta la existencia de una referencia circular en la jerarquía actual(fila). Como parte del elemento recursivo, busca la existencia de un EmpId que fue incluido previamente en la cadena pth.
i.e si el pth anterior se parece a 3->8->10 y la recursión actual añade » ->3 «, (3->8 >10 -> 3) lo que significa que EmpId=3 no sólo es un superior indirecto de EmpId=10, sino que también es el subordinado de EmpId=10 – soy jefe o tu jefe, y tú eres mi jefe tipo de situación 😐
Hagamos ahora los cambios necesarios en dbo.Empleados para ver la consulta de prueba extendida en acción.
Quitemos las restricciones PK y FK para permitir las referencias circulares y añadamos una «ref circular de chico malo» a la tabla.
Ejecutamos la consulta de prueba extendida, y analizamos los resultados (no olvidemos des-cometer la cláusula WHERE previamente comentada al final del script)
El script ejecutará 100 recursiones antes de ser interrumpido por el MAXRECURSION por defecto. El resultado final estará restringido a dos recursiones .. Y cte1.recLvl <= 2; lo cual es necesario para resolver la jerarquía de EmpId=3.
La figura 9 muestra una jerarquía de bucle cerrado, el número máximo permitido de recursiones agotó el error y la salida que muestra el bucle cerrado.
Figura 10, Referencia circular detectada
Algunas notas sobre el script de referencia circular.
El script es sólo una idea de cómo encontrar bucles cerrados en jerarquías. Sólo informa de la primera ocurrencia de una referencia circular – intente eliminar la cláusula WHERE y observe el resultado.
En mi opinión, el script (o una versión similar del mismo) puede ser utilizado en un entorno de producción para, por ejemplo, solucionar problemas o para prevenir la creación de referencias circulares en una jerarquía existente. Sin embargo, necesita ser asegurado por un MAXRECURSION n apropiado, donde n es la profundidad esperada de la jerarquía.
Este script no es relacional y se basa en una técnica de travesía. Siempre es el mejor enfoque para utilizar las restricciones declarativas (PK, FK, CHECK..) para evitar cualquier bucle cerrado en los datos.
Análisis del plan de ejecución
Este segmento explica cómo el optimizador de consultas de Sql Server(QO) implementa un CTE recursivo. Hay un patrón común que QO utiliza cuando construye el plan de ejecución. Ejecuta la consulta de prueba original e incluye el plan de ejecución real
Al igual que la consulta de prueba, el plan de ejecución tiene dos ramas: la rama ancla y la rama recursiva. El operador de concatenación, que implementa el operador UNION ALL, conecta los resultados de las dos partes formando el resultado de la consulta.
Intentemos conciliar la secuencia de ejecución lógica antes mencionada y la implementación real del proceso.
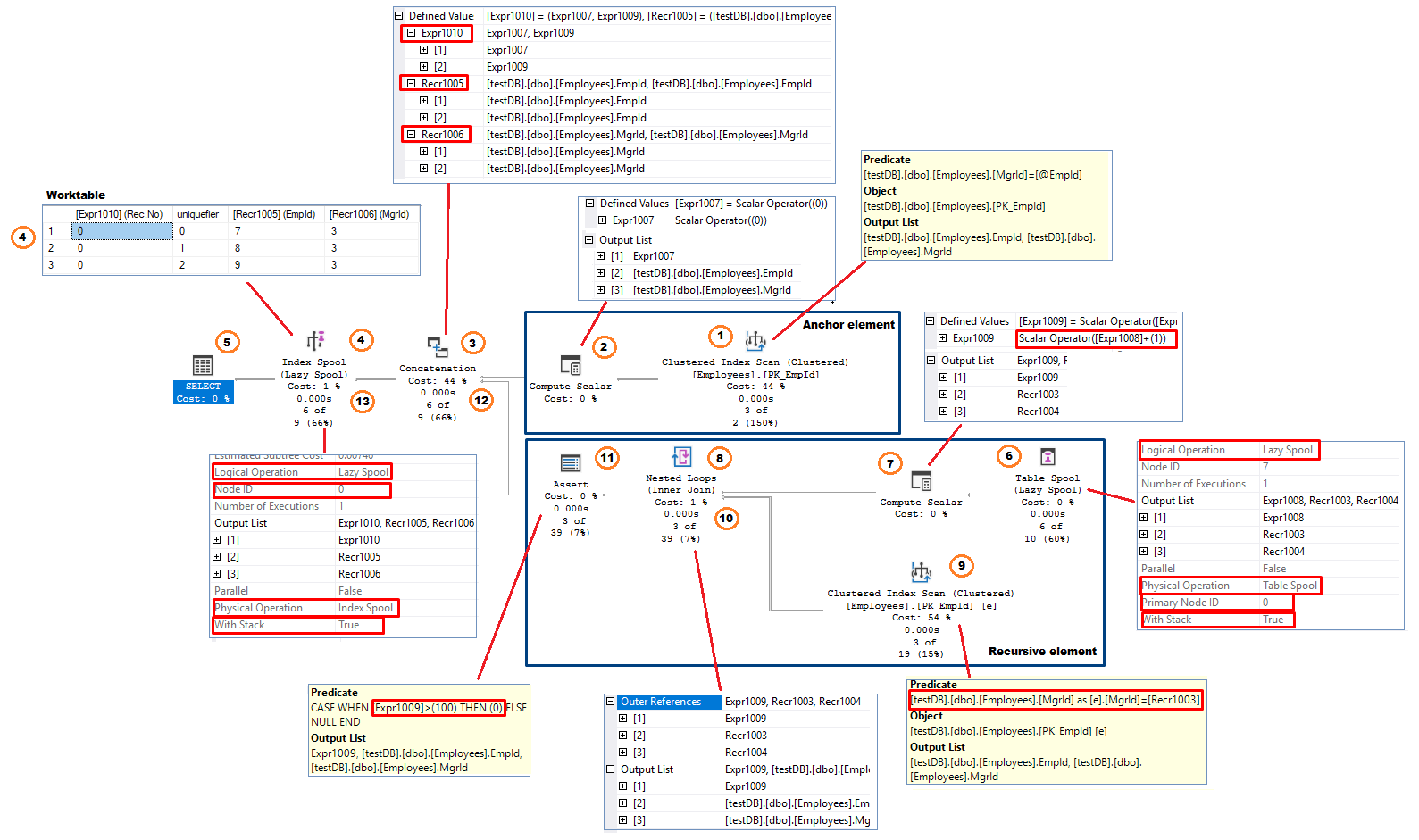
Figura 11, Plan de ejecución del CTE recursivo
Siguiendo el flujo de datos (dirección de derecha a izquierda) el proceso tiene el siguiente aspecto:
Elemento de anclaje (se ejecuta una sola vez)
- Operador de escaneo de índices agrupados – el sistema realiza el escaneo de índices. En este ejemplo, aplica la expresión MgrId = @EmpId como predicado residual. Las filas seleccionadas (columnas EmpId y MgrId) se pasan (fila por fila) de vuelta al operador anterior.
- Compute Scalar El operador añade una columna a la salida. En este ejemplo, el nombre de la columna añadida es . Esto representa el Número de Recurrencias. La columna tiene un valor inicial de 0; =0
- Concatenación – combina las entradas de las dos ramas. En la primera iteración, el operador recibe filas sólo de la rama ancla. También cambia los nombres de las columnas de salida. En este ejemplo los nuevos nombres de las columnas son:
- = o * * mantiene el número de recursiones asignadas en la rama recursiva. No tiene valor en la primera iteración.
- = EmpId(de la parte ancla) o EmpId(de la parte recursiva)
- = MgrId(de la parte ancla) o MgrId (de la parte recursiva)
- Index Spool (Lazy Spool) Este operador almacena el resultado recibido del operador Concatenación en una tabla de trabajo. Tiene la propiedad «Operación Lógica» ajustada a «Carrete Perezoso». Esto significa que el operador devuelve sus filas de entrada inmediatamente y no acumula todas las filas hasta que obtiene el conjunto de resultados final (Eager Spool) . La tabla de trabajo está estructurada como un índice agrupado con la columna clave – el número de recursión. Como la clave del índice no es única, el sistema añade un unificador interno de 4 bytes a la clave del índice para asegurar que todas las filas del índice son, desde la perspectiva de la implementación física, identificables de forma única. El operador también tiene la propiedad «With Stack» establecida en «True» lo que hace que esta versión del operador de spool sea un Stack Spool Un operador Stack Spool siempre tiene dos componentes – un Index Spool que construye la estructura del índice y un Table Spool que actúa como consumidor de las filas almacenadas en la mesa de trabajo que fue construida por el Index Spool.
En esta etapa, el operador Index Spool devuelve filas al operador SELECT y almacena las mismas filas en la mesa de trabajo. - El operador SELECT devuelve EmpId y MgrId ( , ). Excluye del resultado. Las filas se envían al buffer de red a medida que llegan desde los operadores posteriores
Después de agotar todas las filas del operador Index Scan, el operador Concatenation cambia el contexto a la rama recursiva. La rama de anclaje no se ejecutará de nuevo durante el proceso.
Elemento recursivo
- Carrete de tabla (Lazy Spool). El operador no tiene entradas y, como se menciona en (4) actúa como consumidor de las filas producidas por el Index Spool y almacenadas en una mesa de trabajo agrupada. Tiene la propiedad «Primary Node» (nodo primario) establecida en 0, que apunta al Id del nodo del Index Spool. Destaca la dependencia de los dos operadores. El operador
- elimina las filas que leyó en la recursión anterior. Esta es la primera recursión y no hay filas leídas previamente para ser eliminadas. La tabla de trabajo contiene tres filas (Figura 4).
- Lee las filas ordenadas por la clave del índice + el unificador en orden descendente. En este ejemplo, la primera fila leída es EmpId=9, MgrId=3.
Por último, el operador cambia el nombre de las columnas de salida. =, = y se convierte en .
NOTA: El operador de cola de la tabla puede observarse como la expresión cte1 en el lado derecho del INNER JOIN (figura 4) - Calcula el escalar El operador añade 1 al número actual de recurrencias previamente almacenado en la columna .El resultado se almacena en una nueva columna, . = + 1 = 0 + 1 = 1. El operador da salida a tres columnas, las dos del carrete de la tabla ( y ) y
- El operador Bucle anidado(I) recibe filas de su entrada externa, que es el Compute Scalar del paso anterior, y luego utiliza – representa EmpId del operador del carrete de la tabla, como predicado residual en el operador Index Scan posicionado en la entrada interna del Bucle. La entrada interna se ejecuta una vez por cada fila de la entrada externa.
- El operador Index Scan devuelve todas las filas calificadas de la tabla dbo.Employees (dos columnas; EmpId y MgrId) al operador de bucle anidado.
- Nested Loop(II): El operador combina desde la entrada exterior y EmpId y MgrId desde la entrada interior y pasa las tres filas de columnas al siguiente operador.
- El operador Assert se utiliza para comprobar las condiciones que requieren que la consulta se aborte con un mensaje de error. En el caso de los CTEs recursivos, el operador assert implementa la opción de consulta «MAXRECURSION n». Comprueba si la parte recursiva ha alcanzado el número permitido (n) de recurrencias o no. Si el número actual de recurrencias, (ver paso 7) es mayor que (n), el operador devuelve 0 provocando un error en tiempo de ejecución. En este ejemplo, Sql Server utiliza su valor MAXRECURSION por defecto de 100. La expresión tiene el siguiente aspecto CASE WHEN > 100 THEN 0 ELSE NULL Si decidimos excluir el failsafe añadiendo MAXRECURSION 0, el operador assert no se incluirá en el plan.
- La concatenación combina las entradas de las dos ramas. Esta vez recibe la entrada sólo de la parte recursiva y da salida a las columnas/filas como se muestra en el paso 3.
- Index Spool (Lazy Spool) añade la salida del operador de concatenación a la tabla de trabajo y luego la pasa al operador SELECT. En este punto la tabla de trabajo contiene un total de 4 filas: tres filas de la ejecución de anclaje y una de la primera recursión. Siguiendo la estructura de índices agrupados de la mesa de trabajo, la nueva fila se almacena al final de la mesa de trabajo
-
El proceso se reanuda ahora desde el paso 6. El operador de carrete de la tabla elimina las filas leídas previamente (las tres primeras filas) de la mesa de trabajo y lee la última fila insertada, la cuarta fila.
Conclusión
CTE(Common table expressions) es un tipo de expresiones de tabla disponibles en Sql Server. Una CTE es una expresión de tabla independiente que puede ser nombrada y referenciada una o más veces en la consulta principal.
Uno de los usos más importantes de las CTEs es escribir consultas recursivas. Las CTEs recursivas siempre siguen la misma estructura – consulta de anclaje, operador de conjunto múltiple UNION ALL, miembro recursivo y la declaración que invoca la recursión. La CTE recursiva es una recursión declarativa y como tal tiene diferentes propiedades que su contraparte imperativa, por ejemplo, la comprobación de terminación de la recursión declarativa es de naturaleza implícita – el proceso de recursión se detiene cuando no hay filas devueltas en la cte anterior.
Deja una respuesta