¿Qué son los Autoencoders?
On noviembre 11, 2021 by adminUna suave introducción a los Autoencoders y sus diversas aplicaciones. Además, estos tutoriales utilizan tf.keras,la API Python de alto nivel de TensorFlow para construir y entrenar modelos de aprendizaje profundo.
常常見到 Autoencoder 的變形以及應用,打算花幾篇的時間好好的研究一下,順便練習 Tensorflow.keras 的 API 使用。
- Qué es Autoencoder
- Tipos de Autoencoder
- Aplicación de Autoencoder
- Implementación
- Grandes ejemplos
- Conclusión
Dificultad: ★★☆☆
後記: 由於 Tensorflow 2.0 alpha 已於 3/8號釋出,但此篇是在1月底完成的,故大家可以直接使用安裝使用看看,但需要更新至相對應的 CUDA10。
¿Qué es el Autoencoder?
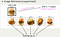
首先,什麼是 Autoencoder 呢? 不囉唆,先看圖吧!

El concepto original de Autoencoder es muy sencillo, consiste en lanzar un dato de entrada y obtener exactamente los mismos datos que el de entrada a través de una red de tipo neuronal.El codificador primero toma los datos de entrada, los comprime en un vector de menor dimensión Z, y luego introduce el Z en el decodificador para restaurar el Z a su tamaño original.Esto parece fácil, pero veamos con más detalle si es tan fácil.

Codificador:
El codificador se encarga de comprimir los datos de entrada originales en un vector de baja dimensión C. Este C, que solemos llamar código, vector latente o vector de características, pero yo suelo llamarlo espacio latente, porque C representa una característica oculta.El codificador puede comprimir los datos originales en un vector significativo de baja dimensión, lo que significa que el autocodificador tiene una reducción de la dimensionalidad, y la capa oculta tiene una función de activación de transformación no lineal, por lo que este codificador es como una versión poderosa de PCA, porque el codificador puede hacer no linealreducción de la dimensión!
Decodificador:
Lo que hace el Decodificador es devolver el espacio latente a los datos de entrada en la medida de lo posible, lo que supone una transformación de los vectores de características desde el espacio dimensional inferior al espacio dimensional superior.
Entonces, ¿cómo se mide lo bien que funciona el Autoencoder? Simplemente comparando la similitud de los dos datos de entrada originales con los datos reconstruidos.Así que nuestra función de pérdida puede escribirse como ….
Función de pérdida:

Porque queremos minimizar la diferencia entre elEl autocodificador se entrena utilizando la retropropagación para actualizar los pesos, al igual que una red neuronal normal.actualizar los pesos.
En resumen, Autoencoder es ….
1. una arquitectura de modelo muy común, también se utiliza comúnmente para el aprendizaje no supervisado
2. se puede utilizar como un método de reducción de la dimensión para no lineal
3. se puede utilizar para aprender la representación de datos, la transformación de características representativas
Llegados a este punto, debería ser fácil entender cómo es Autoencoder, la arquitectura es muy sencilla, así que ¡vamos a ver sus transformaciones!
Tipos de Autoencoder
Después de explicar los principios básicos de Autoencoder, es el momento de echar un vistazo al uso extendido y avanzado de Autoencoder, ¡para que puedas ver el amplio uso de Autoencoder!
2-1. Unet:
Unet puede utilizarse como uno de los medios de segmentación de imágenes, y la arquitectura de Unet puede verse como una variante de Autoencoder.

2-2. Autocodificadores recursivos:
Se trata de una red que combina el nuevo texto de entrada con el espacio latente de otras entradas, el propósito de esta red es la clasificación de sentimientos.Esto también puede verse como una variante del Autoencoder, que extrae el texto disperso a medida que se escribe y encuentra el espacio latente que es importante.

2-Seq2Seq:
Sequence to Sequence es un modelo generativo que ha sido muy popular desde hace tiempo. Es una maravillosa solución al dilema de que los tipos de RNN no son capaces de manejar emparejamientos indeterminados, y ha tenido un buen rendimiento en temas como la generación de chatbot y de texto.Esto también puede verse como una especie de arquitectura de autocodificador.

Aplicaciones del Autoencoder
Después de ver las muchas y variadas variaciones de Autoencoder, ¡vamos a ver dónde más se puede utilizar Autoencoder!
3-1. Peso preentrenado del modelo
También se puede utilizar el autoencoder para preentrenar el peso, lo que significa que el modelo encuentra un mejor valor de partida.Por ejemplo, cuando queremos completar el modelo de objetivo como objetivo. capa oculta es:, por lo que al principio utilizamos el concepto de autoencoder para la entrada de 784 dimensiones, y el espacio latente en el medio es de 1000 dimensiones para hacer el preentrenamiento primero, por lo que estas 1000 dimensiones pueden retener bien la entradaLuego eliminamos la salida original y añadimos la segunda capa, y así sucesivamente.De este modo, todo el modelo obtendrá un mejor valor de partida.
¡Eh! Hay una parte extraña… si usas 1000 neuronas para representar 784 dimensiones de entrada, ¿no significa eso que la red sólo necesita ser copiada de nuevo? ¿Para qué sirve la formación? Sí, por eso en un pre-entrenamiento como éste, solemos añadir el regularizador de la norma L1 para que la capa oculta no se copie de nuevo.

Según el Sr. Li HongyiEn el pasado, era más común utilizar este método para la formación previa, pero ahora, debido al aumento de las habilidades de formación, ya no es necesario utilizar este método.Pero si tienes muy pocos datos etiquetados pero un montón de datos sin etiquetar, puedes usar este método para hacer el pre-entrenamiento del peso porque el Autoencoder en sí mismo es un método de aprendizaje no supervisado, usamos los datos sin etiquetar para obtener el pre-entrenamiento del peso primero, y luego usamos los datos sin etiquetar para obtener el pre-entrenamiento del peso.Primero utilizamos los datos no etiquetados para obtener el preentrenamiento de los pesos, y luego utilizamos los datos etiquetados para afinar los pesos, de modo que podamos obtener un buen modelo.Para más detalles, vea el vídeo del Sr. Li, ¡está muy bien explicado!
3-2. Segmentación de imágenes
El modelo Unet que acabamos de ver, vamos a verlo de nuevo, porque es básicamente el problema de detección de defectos más común en la industria manufacturera de Taiwán.
Primero tenemos que etiquetar los datos de entrada, que serán nuestra salida. Lo que tenemos que hacer es construir una red, introducir la imagen original (izquierda, radiografía del diente) y generar la salida (derecha, clasificación de la estructura del diente).En este caso, el codificador & decodificador será una capa de convolución con un fuerte juicio gráfico, la extracción de características significativas y deconvolución de nuevo en el decodificador para obtener el resultado de la segmentación.

3-3. Vídeo a texto
Para un problema de pies de foto como éste, utilizamos el modelo de secuencia a secuencia, donde los datos de entrada son un montón de fotos y la salida es un texto que describe las fotos.El modelo de secuencia a secuencia utiliza la red LSTM + Conv como codificador & decodificador, que puede describir una secuencia de acciones secuenciales & utilizando el núcleo CNN para extraer el espacio latente requerido en la imagen.pero esta tarea es muy difícil de hacer, ¡así que te dejaré intentarlo si estás interesado!

3-4. Recuperación de imágenes
Recuperación de imágenes Lo que hay que hacer es introducir una imagen y tratar de encontrar la más parecida, pero si se compara por píxeles, entonces es muy fácilSi se utiliza el Autoencoder para comprimir primero la imagen en el espacio latente y luego calcular la similitud en el espacio latente de la imagen, el resultado será mucho mejor.El resultado es mucho mejor porque cada dimensión del espacio latente puede representar una determinada característica.Si la distancia se calcula sobre el espacio latente, es razonable encontrar imágenes similares.En particular, esta sería una gran forma de aprendizaje no supervisado, ¡sin etiquetar datos!
Aquí estánEl documento de Georey E. Hinton, el famoso dios del aprendizaje profundo, muestra el gráfico que se quiere buscar en la esquina superior izquierda, mientras que los demás son todos los gráficos que el autoencoder piensa que son muy similares.7133>

Content-BasedRecuperación de imágenes
3-5. Detección de anomalías
No encontré una buena imagen, así que tuve que usar esta LOL
Encontrar anomalías también es un problema de fabricación súper común, así que este problema también se puede intentar con Autoencoder¡Podemos probarlo con Autoencoder!En primer lugar, hablemos de la aparición real de anomalías. Las anomalías suelen producirse con muy poca frecuencia, por ejemplo, señales anormales en la máquina, picos de temperatura repentinos ……, etc.Si los datos se recogen cada 10 segundos, entonces se recogerán 260.000 datos cada mes, pero sólo un periodo de tiempo son anomalías, lo que en realidad es una cantidad de datos muy desequilibrada.
Así que la mejor manera de afrontar esta situación es ir a por los datos originales, ¡que al fin y al cabo es la mayor cantidad de datos que tenemos!Si podemos tomar los datos buenos y entrenar un buen autoencoder, entonces si aparecen anomalías, naturalmente los gráficos reconstruidos se romperán.Así es como empezamos la idea de utilizar el autocodificador para encontrar anomalías.

Implementación
¡Aquí usamos Mnist como un ejemplo de juguete e implementamos un Autoencoder usando la API de alto nivel de Tensorflow.keras! Desde que el nuevo paquete para tf.keras fue liberado en breve, practicamos usando el método de subclase Model en el archivo
4-1. Crear un modelo – Vallina_AE:
¡Primero, importa tensorflow!7133>

El uso de tf.keras es tan sencillo como eso, ¡sólo tienes que escribir tf.keras!(No sé de qué estoy hablando lol)
Carga de datos & preproceso del modelo
Primero cogemos los datos de Mnist de tf.keras.dataset y hacemos un pequeño preproceso
Nomalizar: comprimir los valores entre 0 y 1, el entrenamiento será más fácil de converger
Binarización: resaltar las zonas más evidentes, el entrenamiento dará mejores resultados.
Crear un modelo – Vallina_AE:
Este es el método que proporciona el documento de Tensorflow para crear modelos.más complejas.
Lo que he aprendido hasta ahora es crear la capa en el lugar __init __ y definir el pase hacia adelante en la llamada.
Así que utilizamos dos modelos secuenciales para crear el Codificador & decodificador. dos son una estructura simétrica, el codificador está conectado a la capa de entrada que es responsable de llevar los datos de entrada y luego a las tres capas densas. el decodificador es el mismo.
De nuevo, bajo la llamada, necesitamos concatenar el codificador & decodificador, definiendo primero el espacio latente como la salida de self.encoder.espacio como la salida de self.encoder, y luego la reconstrucción como el resultado de pasar el decodificador.A continuación, utilizamos tf.keras.Model() para conectar los dos modelos que definimos en __init__.AE_model = tf.keras.Model(inputs = self.encoder.input, outputs = reconstruction) especifica input como entrada del codificador y output como salida del decodificador, ¡y ya está!Luego devolvemos el AE_model y ¡ya está!
Compilación de modelos & entrenamiento
Antes de que Keras pueda entrenar un modelo, tiene que ser compilado antes de que pueda ser lanzado al entrenamiento.En la compilación se especifica el optimizador que se quiere utilizar y la pérdida que se quiere calcular.
Para el entrenamiento se utiliza VallinaAE.fit para introducir los datos, pero recuerda que nos estamos restaurando, por lo que X e Y tienen que ser lanzados en los mismos datos.
Veamos los resultados del entrenamiento de 100 épocas, parece que los resultados de la reconstrucción no son tan buenos como pensábamos.

4-2. Crear un modelo- Conv_AE:
Como su nombre indica, podemos utilizar la capa de Convolución como capa oculta para aprender características que puedan ser reconstruidas.
Después de cambiar el modelo, puedes echar un vistazo a los resultados para ver si hay alguna mejora.

Parece que los resultados de Reconstrucción son mucho mejores, con unas 10 épocas de entrenamiento.
4-3. Crear un modelo – denoise_AE:
Además, el autocodificador puede utilizarse para eliminar el ruido, por lo que aquí
Primero, podemos añadir ruido a la imagen original. La lógica de añadir ruido es hacer un simple desplazamiento en el píxel original y luego añadir números aleatorios.La parte de preprocesamiento de la imagen se puede hacer simplemente haciendo que el clip sea 0 si es menor que 0 y 1 si es mayor que 1. Como se muestra a continuación, después del procesamiento de la imagen del clip, podemos hacer que la imagen sea más nítida y las áreas obvias más visibles.Esto nos da un mejor resultado cuando lanzamos el Autoencoder.

y el propio modelo y Conv_AENo hay ninguna diferencia entre el modelo en sí y Conv_AE, excepto que durante el ajuste hay que cambiar a
denoise_AE.fit(train_images_noise, train_images, epochs=100, batch_size=128, shuffle=True)
para restablecer el ruido_datos original a los datos de entrada originales

.
Como se puede ver, en Mnist, un simple Autoencoder consigue un efecto de denoising muy rápido.
Grandes ejemplos
Este es un buen recurso para aquellos interesados en aprender más sobre él
- Construir Autoencoders en Keras autoencoder serie está claramente escrito.
- Tutorial de la documentación oficial de Tensorflow 2.0, algo muy completo, sólo escribir un poco difícil, para pasar bastante tiempo para ver (al menos yo tiro XD)
3. Li Hongyi profesor de aprendizaje profundo también es muy recomendable, hablar muy claro y fácil de entender, no
Conclusión
Utilice este artículo para establecer rápidamente el concepto básico de Autoencoder, algunas variaciones de Autoencoder y la aplicación deescenarios.4310>
Los próximos artículos comenzarán con los modelos generativos, extendiéndose desde el concepto de autoencoder, VAE, hasta GAN, y otras extensiones y transformaciones a lo largo del camino.¡
Si te gusta el artículo, por favor, pulsa unas cuantas palmas más (no sólo una) como estímulo!
Lee el código completo de este artículo:https://github.com/EvanstsaiTW/Generative_models/blob/master/AE_01_keras.ipynb
Deja una respuesta