Cómo usar Tesseract en Windows
On enero 14, 2022 by admin
Tesseract es un software de reconocimiento óptico de caracteres desarrollado por Google. Es una herramienta de OCR de código abierto. Hay muchas versiones de tesseract pero nosotros utilizaremos la versión 4.0.
En la versión 4, Tesseract ha implementado un motor de reconocimiento basado en la memoria a largo plazo (LSTM). La LSTM es un tipo de red neuronal recurrente (RNN). El reconocimiento basado en LSTM funciona de forma mucho más eficaz que los antiguos procesos de reconocimiento (basados en CNN).
Gracias a tesseract, podremos guardar el contenido de nuestras imágenes como archivos de texto.
Instalación
La instalación depende de tu sistema operativo. Ahora vamos a ir a través de las ventanas. Primero, vamos a descargar e instalar tesseract a través de este enlace. (Se descarga un archivo exe.) Configuramos el archivo exe fácilmente.
Después debemos añadir un PATH a las variables del sistema de windows. En realidad es un paso fácil. Primero buscamos y copiamos la carpeta raíz de la instalación de tesseract. Deberá ser así :
C:\Program Files\Tesseract-OCR
Y luego en la barra de búsqueda de windows Configuración avanzada del sistema
Configuración avanzada del sistema > Avanzado > Variables de entorno > PATH > Nuevo
Pegamos la ruta de origen que hemos copiado y guardamos esta configuración. Después de este paso hay que reiniciar el ordenador para aplicar las configuraciones.
La instalación de tesseract se ha completado. Se puede confirmar la instalación desde la línea de comandos. Cuando ejecutamos el comando tesseract en la línea de comandos, debería darnos información sobre el programa.
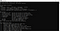
Ahora podemos pasar a la parte de python. Para utilizar tesseract en python, debemos descargar la biblioteca pytesseract. Esta librería puede descargarse mediante pip en el entorno que estemos utilizando.
pip install pytesseract
¡Ahora el tesseract está listo para usarse!!!
Codificación
Es realmente sencillo utilizar tesseract. Lo difícil es la optimización de la configuración.
Porque si quieres hacer un ocr exitoso, necesitas ser cuidadoso en el paso de procesamiento de la imagen y la configuración del ocr.
Apliquemos el OCR al recibo.

Importar las bibliotecas
import pytesseract
from PIL import Image
import cv2
import numpy as np
Configurar el valor DPI de la imagen
Los puntos por pulgada (DPI, o dpi) es una medida de la densidad de puntos del escáner de vídeo o imagen. El valor DPI es una cosa importante para ejecutar el OCR. Porque si el valor DPI es inferior a 300, puede reducir el éxito del OCR.
file_path= 'receipt.jpg'
im = Image.open(file_path)
im.save('ocr.png', dpi=(300, 300))
Aplicando algunas técnicas para hacer la imagen más limpia
Primero escalamos nuestra imagen con x2. Si los caracteres son pequeños entonces necesitamos escalar la imagen para reconocerla. Después de eso aplicamos una técnica de umbral simple. Su umbral binario. Primero hay que probar con el valor 127, después se pueden probar diferentes variables. El umbral cambia el píxel a negro si el valor del píxel supera el valor del umbral. Si hacemos la imagen en escala de grises, nos dará una imagen en blanco y negro.
Hay diferentes técnicas de umbral. Puedes consultar el sitio web de origen con este enlace.

Ejecución de Tesseract
Ahora podemos ejecutar tesseract. Tiene una función image_to_string(). Nos da una cadena como salida.
text = pytesseract.image_to_string(treshold)
Guardando la salida
Podemos guardar la salida con el siguiente código.
with open("Output.txt", "w",5 ,"utf-8") as text_file:
text_file.write(text)
La salida del OCR es la siguiente:
El resultado es muy exitoso. Si se desea un mayor éxito, se pueden aplicar diferentes operaciones a la imagen.
Deja una respuesta