Wie man Tesseract unter Windows benutzt
On Januar 14, 2022 by admin
Tesseract ist eine Software zur optischen Zeichenerkennung, die von Google entwickelt wurde. Es ist ein Open-Source-OCR-Tool. Es gibt viele Versionen von Tesseract, aber wir werden die Version 4.0 verwenden.
In Version 4 hat Tesseract eine auf Long Short Term Memory (LSTM) basierende Erkennungsmaschine implementiert. LSTM ist eine Art rekurrentes neuronales Netzwerk (RNN). Die LSTM-basierte Erkennung arbeitet viel effektiver als die alten (CNN-basierten) Erkennungsprozesse.
Dank Tesseract werden wir in der Lage sein, den Inhalt unserer Bilder als Textdateien zu speichern.
Installation
Die Installation ist abhängig von Ihrem Betriebssystem. Jetzt gehen wir durch die Fenster. Zuerst laden wir Tesseract über diesen Link herunter und installieren es. (Es wird eine Exe-Datei heruntergeladen.) Wir richten die Exe-Datei einfach ein.
Danach sollten wir einen PATH zu den Windows-Systemvariablen hinzufügen. Eigentlich ist das ein einfacher Schritt. Zuerst suchen wir das Stammverzeichnis der Tesseract-Installation und kopieren es. Es sollte so aussehen:
C:\Program Files\Tesseract-OCR
Und dann in der Suchleiste von Windows Erweiterte Systemeinstellungen
Erweiterte Systemeinstellungen > Erweitert > Umgebungsvariablen > PATH > Neu
Wir fügen den kopierten Quellpfad ein und speichern diese Konfiguration. Nach diesem Schritt muss der Computer neu gebootet werden, um die Konfigurationen zu übernehmen.
Die Installation von Tesseract ist abgeschlossen. Sie können die Installation über die Befehlszeile bestätigen. Wenn wir den Befehl tesseract auf der Kommandozeile ausführen, sollten wir Informationen über das Programm erhalten.
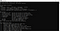
Nun können wir zum Python-Teil übergehen. Um Tesseract auf Python zu verwenden, sollten wir die pytesseract-Bibliothek herunterladen. Diese Bibliothek kann über pip in die von Ihnen verwendete Umgebung heruntergeladen werden.
pip install pytesseract
Nun ist Tesseract einsatzbereit!!!
Codierung
Es ist wirklich einfach Tesseract zu benutzen. Der schwierige Teil ist die Optimierung der Einstellungen.
Wenn man nämlich eine erfolgreiche OCR machen will, muss man bei der Bildverarbeitung und den OCR-Einstellungen vorsichtig sein.
Lassen Sie uns OCR auf den Beleg anwenden.

Importieren der Bibliotheken
import pytesseract
from PIL import Image
import cv2
import numpy as np
Einstellen des DPI-Wertes des Bildes
Dots per Inch (DPI, oder dpi) ist ein Maß für die Punktdichte eines Video- oder Bildscanners. Der DPI-Wert ist ein wichtiger Faktor bei der OCR-Ausführung. Wenn der DPI-Wert niedriger als 300 ist, kann dies den Erfolg der OCR verringern.
file_path= 'receipt.jpg'
im = Image.open(file_path)
im.save('ocr.png', dpi=(300, 300))
Einige Techniken anwenden, um das Bild sauberer zu machen
Zunächst skalieren wir unser Bild mit x2. Wenn die Zeichen klein sind, müssen wir das Bild skalieren, um sie zu erkennen. Danach wenden wir eine einfache Schwellenwerttechnik an. Es ist der binäre Schwellenwert. Zuerst sollte man es mit einem Wert von 127 versuchen, danach können verschiedene Variablen ausprobiert werden. Der Schwellenwert ändert das Pixel in schwarz, wenn der Pixelwert über dem Schwellenwert liegt. Wenn wir das Bild in Graustufen umwandeln, erhalten wir ein schwarz-weißes Bild.
Es gibt verschiedene Schwellenwerttechniken. Sie können die Quellen-Website mit diesem Link überprüfen.

Tesseract ausführen
Nun können wir Tesseract ausführen. Es hat eine image_to_string() Funktion. Sie liefert uns eine Zeichenkette als Ausgabe.
text = pytesseract.image_to_string(treshold)
Ausgabe speichern
Wir können die Ausgabe mit dem folgenden Code speichern.
with open("Output.txt", "w",5 ,"utf-8") as text_file:
text_file.write(text)
Die Ausgabe der OCR ist wie folgt:
Das Ergebnis ist sehr erfolgreich. Wenn ein höherer Erfolg gewünscht ist, können verschiedene Operationen auf das Bild angewendet werden.
Schreibe einen Kommentar