Wie das Web funktioniert
On Oktober 15, 2021 by adminDas Web ist überall!
Wir nutzen es mehr als je zuvor – auch an vielen Orten, wo man es vielleicht nicht sieht. Denn „das Web“ ist mehr als nur Websites, die man durch die Eingabe einer URL in den Browser besucht.
Ob Sie Ihre E-Mails auf dem Handy abrufen oder einen Tweet senden – Sie nutzen das Internet (also „das Web“).
Wie funktioniert das alles? Welche Technologien sind involviert und was müssen Sie lernen (und in welchem Umfang), wenn Sie Webentwickler werden wollen?
In diesem Artikel und Video (siehe oben) werde ich nicht in alle technischen Details eintauchen. Es soll ein guter Überblick über die Webfunktionalität sein.

CSS – Der komplette Leitfaden
Mit diesem umfassenden Kurs (20h+) kannst du CSS beherrschen und lernen, wie du schöne Webseiten erstellst.

JavaScript – The Complete Guide
Lernen Sie in diesem praxisorientierten Kurs JavaScript von Grund auf, um hochgradig interaktive und dynamische Websites zu erstellen!
# How Websites Work
Beginnen wir mit der offensichtlichsten Art, das Internet zu nutzen: Sie besuchen eine Website wie academind.com.
In dem Moment, in dem du diese Adresse in deinen Browser eingibst und auf ENTER drückst, passieren eine Menge verschiedener Dinge:
- Die URL wird aufgelöst
- Eine Anfrage wird an den Server der Website gesendet
- Die Antwort des Servers wird geparst
- Die Seite wird gerendert und angezeigt

Aktuell, könnte jeder einzelne Schritt in mehrere andere Schritte aufgeteilt werden, aber um einen guten Überblick darüber zu bekommen, wie alles funktioniert, können wir das hier ignorieren. Schauen wir uns alle vier Schritte an.
Schritt 1 – URL wird aufgelöst
Der Code der Website ist natürlich nicht auf Ihrem Rechner gespeichert und muss daher von einem anderen Computer geholt werden, auf dem er gespeichert ist. Dieser „andere Computer“ wird „Server“ genannt. Er dient nämlich einem bestimmten Zweck, in unserem Fall der Website.
Sie geben „academind.com“ (das nennt man „eine Domain“), aber eigentlich wird der Server, der den Quellcode einer Website hostet, über IP (= Internet Protocol)-Adressen identifiziert. Der Browser schickt eine „Anfrage“ (siehe Schritt 2) an den Server mit der von Ihnen eingegebenen IP-Adresse (indirekt – Sie haben natürlich „academind.com“ eingegeben).
In Wirklichkeit geben Sie auch oft "academind.com/learn" oder so etwas ein. "academind.com" ist die Domain, "/learn" ist der sogenannte Pfad. Zusammen bilden sie die „URL“ („Uniform Resource Locator“).
Außerdem kann man die meisten Websites über "www.academind.com" oder nur "academind.com" besuchen. Technisch gesehen ist "www" eine Subdomain, aber die meisten Websites leiten den Verkehr zu "www" einfach auf die Hauptseite um.
Eine IP-Adresse sieht normalerweise so aus: 172.56.180.5 (es gibt allerdings auch eine „modernere“ Form, die IPv6 genannt wird – aber das lassen wir jetzt mal außen vor). Mehr über IP-Adressen erfährst du auf Wikipedia.
Wie wird die Domain „academind.com“ in ihre IP-Adresse übersetzt?
Es gibt eine besondere Art von Server im Internet – nicht nur einen, sondern viele Server dieser Art. Ein so genannter „Namensserver“ oder „DNS-Server“ (DNS = „Domain Name System“).
Die Aufgabe dieser DNS-Server ist es, Domains in IP-Adressen zu übersetzen. Man kann sich diese Server als riesige Wörterbücher vorstellen, die Übersetzungstabellen speichern: Domain => IP-Adresse.
Wenn Sie „academind.com“ eingeben, holt sich der Browser also zuerst die IP-Adresse von einem solchen DNS-Server.
Wenn Sie sich wundern: Der Browser kennt die Adressen dieser Domain-Server auswendig, sie sind sozusagen in den Browser einprogrammiert.
Wenn die IP-Adresse bekannt ist, geht es weiter zu Schritt 2.
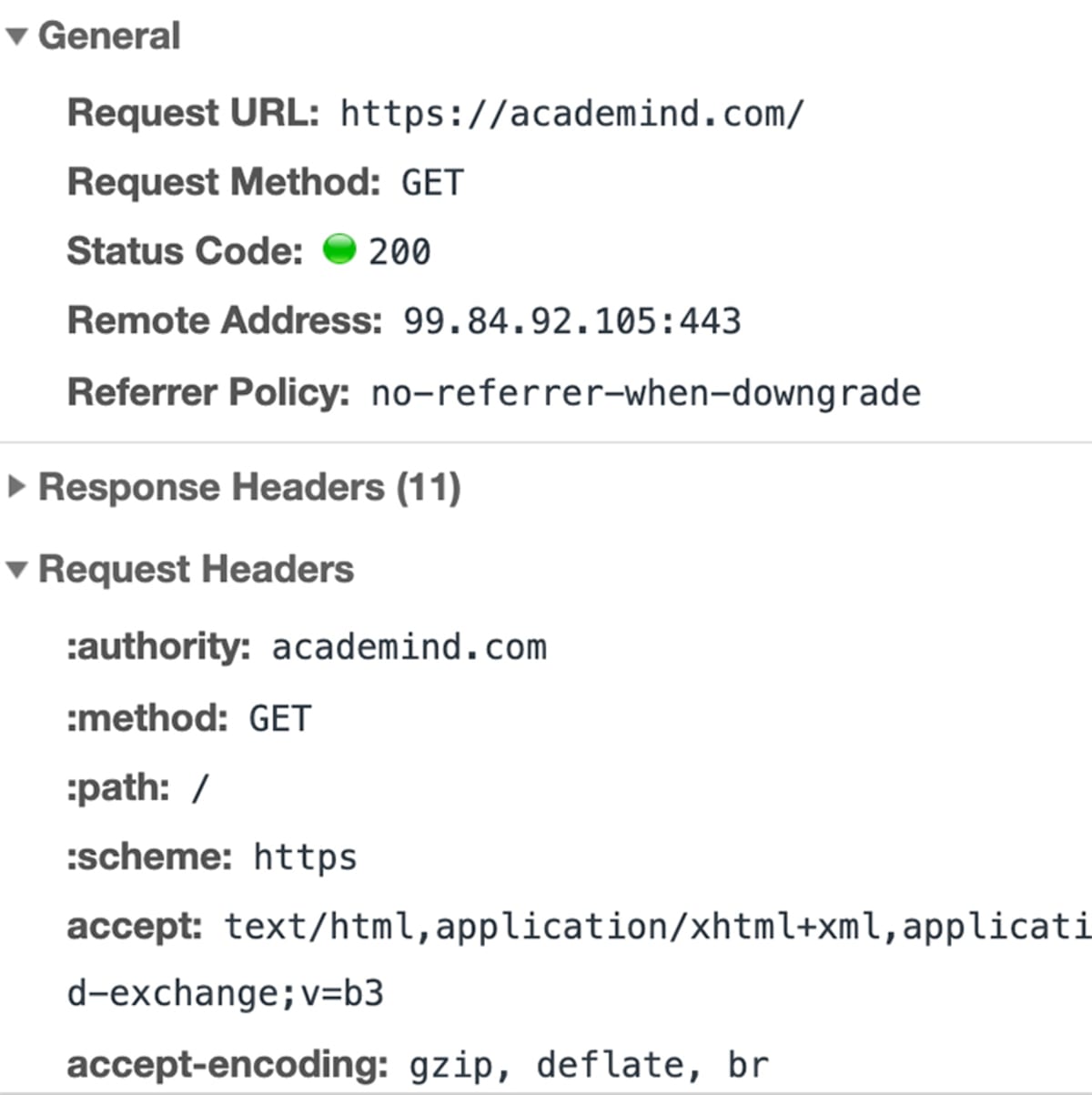
Schritt 2 – Anfrage wird gesendet
Wenn die IP-Adresse geklärt ist, stellt der Browser eine Anfrage an den Server mit dieser IP-Adresse.
„Eine Anfrage“ ist nicht nur ein Begriff. Es ist wirklich eine technische Sache, die hinter den Kulissen passiert.
Der Browser bündelt eine Reihe von Informationen (Wie lautet die genaue URL? Welche Art von Anfrage soll gestellt werden? Sollen Metadaten angehängt werden?) und sendet dieses Datenpaket an die IP-Adresse.
Die Daten werden über das „HyperText Transfer Protocol“ (bekannt als „HTTP“) gesendet – ein standardisiertes Protokoll, das festlegt, wie eine Anfrage (und Antwort) auszusehen hat, welche Daten enthalten sein dürfen (und in welcher Form) und wie die Anfrage übermittelt wird. Mehr über HTTP erfahren Sie hier.
Da HTTP verwendet wird, sieht eine vollständige URL eigentlich so aus: http://academind.com. Der Browser vervollständigt sie automatisch für Sie.
Und es gibt auch HTTPS – es ist wie HTTP, aber verschlüsselt. Die meisten modernen Seiten (einschließlich academind.com) verwenden dies anstelle von HTTP. Eine vollständige URL lautet dann: https://academind.com.
Da der gesamte Prozess und das Format standardisiert sind, gibt es kein Rätselraten darüber, wie diese Anfrage vom Server gelesen werden muss.
Der Server bearbeitet die Anfrage dann entsprechend und gibt eine so genannte „Antwort“ zurück. Wiederum ist eine „Antwort“ eine technische Sache und ähnlich wie eine „Anfrage“. Man könnte sagen, sie ist im Grunde eine „Anfrage“ in umgekehrter Richtung.
Wie eine Anfrage kann auch eine Antwort Daten, Metadaten usw. enthalten. Wenn eine Seite wie academind.com angefordert wird, enthält die Antwort den Code, der erforderlich ist, um die Seite auf dem Bildschirm darzustellen.
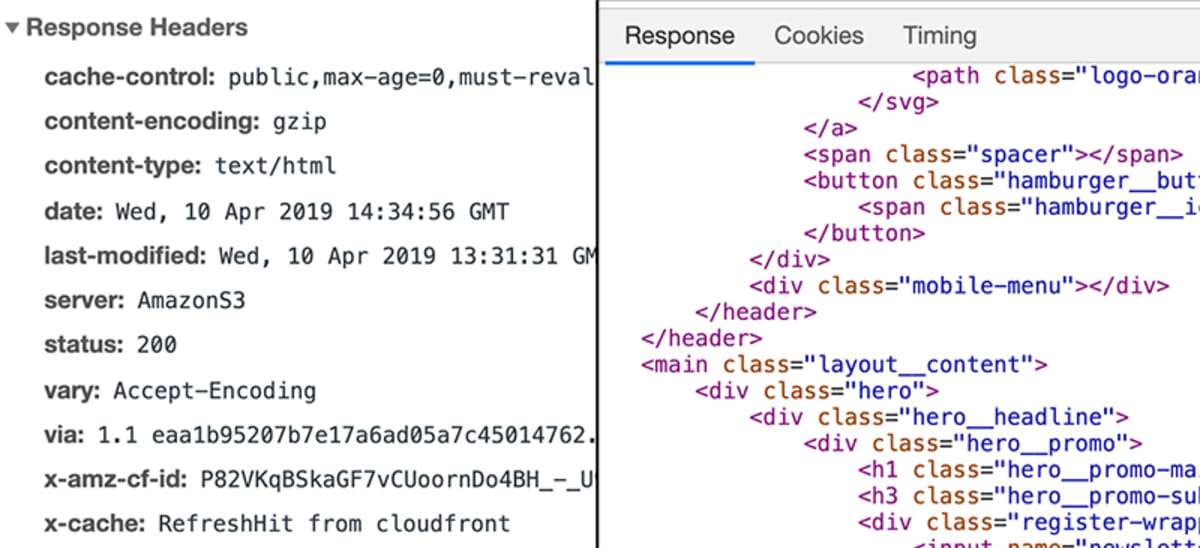
Was passiert auf dem Server?
Das wird von Webentwicklern festgelegt. Am Ende muss eine Antwort gesendet werden. Diese Antwort muss nicht unbedingt „eine Website“ enthalten. Sie kann beliebige Daten enthalten – auch Dateien oder Bilder.
Einige Server sind so programmiert, dass sie Websites dynamisch auf der Grundlage der Anfrage generieren (z. B. eine Profilseite mit Ihren persönlichen Daten), andere Server geben vorgenerierte HTML-Seiten zurück (z. B. eine Nachrichtenseite). Oder es wird beides gemacht – für verschiedene Teile einer Webseite. Es gibt auch noch eine dritte Alternative: Webseiten, die vorgeneriert sind, aber ihr Aussehen und ihre Daten im Browser ändern.
Die verschiedenen Arten von Webseiten sind nicht wirklich der Schwerpunkt dieses Artikels. Wenn Sie mehr darüber erfahren möchten, schauen Sie sich diesen Artikel + Video an.
Für unseren einfachen Fall haben wir einen Server, der den Code zur Anzeige einer Website zurückgibt. Fahren wir also mit Schritt 3 fort.
Schritt 3 – Antwort wird analysiert
Der Browser empfängt die vom Server gesendete Antwort. Damit allein wird aber noch nichts auf dem Bildschirm angezeigt.
Der nächste Schritt ist, dass der Browser die Antwort analysiert. Genauso wie es der Server mit der Anfrage gemacht hat. Auch hier hilft natürlich die durch HTTP erzwungene Standardisierung.
Der Browser überprüft die Daten und Metadaten, die in der Antwort enthalten sind. Auf dieser Grundlage entscheidet er, was zu tun ist.
Vielleicht haben Sie schon einmal eine PDF-Datei in Ihrem Browser geöffnet. Das geschah, weil die Antwort dem Browser mitteilte, dass es sich bei den Daten nicht um eine Website, sondern um ein PDF-Dokument handelt. Und der Browser versucht, für jeden Datentyp, den er erkennt, den besten Verarbeitungsmechanismus zu wählen.
Zurück zu unserem Website-Szenario.
In diesem Fall würde die Antwort ein bestimmtes Stück Metadaten enthalten, das dem Browser sagt, dass die Antwortdaten vom Typ text/html sind.
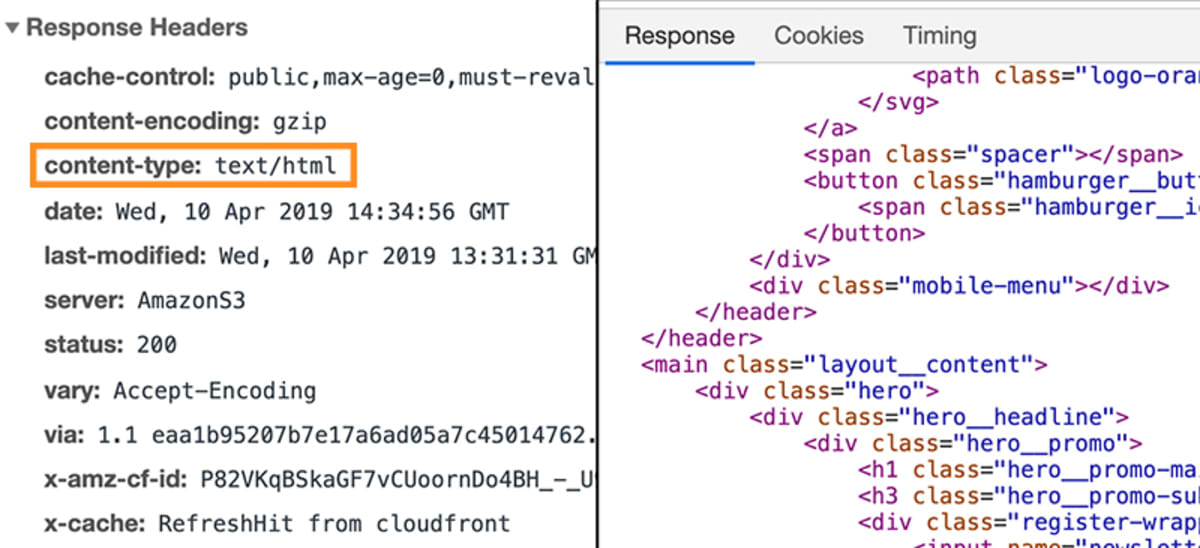
Dies ermöglicht es dem Browser, die eigentlichen Daten, die an die Antwort angehängt sind, als HTML-Code zu parsen.
HTML ist die zentrale „Programmiersprache“ (technisch gesehen ist es keine Programmiersprache – man kann damit keine Logik schreiben) des Webs. HTML steht für „Hyper Text Markup Language“ und beschreibt die Struktur einer Webseite.
Der Code sieht so aus:
<h1>Breaking News!</h1><p>Websites work because browser understand HTML!</p><h1> und <p> sind so genannte „HTML-Tags“ und wenn du mehr über HTML lernen willst, ist diese Serie ein guter Anlaufpunkt.
Jeder HTML-Tag hat eine semantische Bedeutung, die der Browser versteht, denn HTML ist auch standardisiert. Daher gibt es kein Rätselraten darüber, was ein <h1>-Tag bedeutet.
Der Browser weiß, wie man HTML parst und geht nun einfach durch die gesamten Antwortdaten (auch „Antwortkörper“ genannt), um die Website zu rendern.
Schritt 4 – Die Seite wird angezeigt
Wie bereits erwähnt, geht der Browser die vom Server zurückgegebenen HTML-Daten durch und erstellt daraus eine Website.
Es ist jedoch wichtig zu wissen, dass HTML keine Anweisungen darüber enthält, wie die Website aussehen soll (d.h. wie sie gestaltet werden soll). Es definiert lediglich die Struktur und teilt dem Browser mit, welcher Inhalt eine Überschrift ist, welcher Inhalt ein Bild ist, welcher Inhalt ein Absatz ist usw. Dies ist besonders wichtig für die Zugänglichkeit – Bildschirmlesegeräte erhalten alle nützlichen Informationen aus der HTML-Struktur.
Eine Seite, die nur HTML enthält, würde allerdings so aussehen:

Nicht so schön, oder?
Deshalb gibt es eine weitere wichtige Technologie (eine weitere „Programmiersprache“, die eigentlich keine Programmiersprache ist): CSS („Cascading Style Sheets“).
Bei CSS geht es darum, die Website zu gestalten. Das geschieht über „CSS-Regeln“:
h1 { color: blue;}Diese Regel würde alle <h1>-Tags blau einfärben.
Regeln wie diese können in den HTML-Code eingefügt werden, aber normalerweise sind sie Teil separater .css-Dateien, die separat angefordert werden.
Ohne hier zu sehr ins Detail zu gehen, hat das eine wichtige Bedeutung: Eine Website kann aus mehr als den Daten der ersten Antwort bestehen, die wir erhalten.
In der Praxis holen Websites eine Menge zusätzlicher Daten ab (über zusätzliche Anfragen und Antworten), die ausgelöst werden, sobald die erste Antwort angekommen ist.
Wie funktioniert das?
Nun, der HTML-Code der ersten Antwort enthält einfach Anweisungen, weitere Daten über neue Anfragen zu holen – und der Browser versteht diese Anweisungen:
<link rel="stylesheet" href="/page-styles.css" />
Auch hier werde ich nicht weiter ins Detail gehen. Wenn Sie mehr über CSS erfahren wollen, ist unser vollständiger Leitfaden sehr nützlich!
Zusammen mit CSS ist der Browser in der Lage, Webseiten wie diese darzustellen:

Es gibt noch eine weitere Programmiersprache (diesmal ist es wirklich eine Programmiersprache!): JavaScript.
Es ist nicht immer sichtbar, aber alle dynamischen Inhalte, die Sie auf einer Website finden (z. B. Tabs, Overlays usw.), sind eigentlich nur dank JavaScript möglich. Es ermöglicht Webentwicklern, Code zu definieren, der im Browser (und nicht auf dem Server) ausgeführt wird, so dass JavaScript verwendet werden kann, um die Website zu verändern, während der Benutzer sie anschaut.
Wenn Sie mehr erfahren möchten, sehen Sie sich unsere JavaScript-Ressourcen an, z. B. unseren vollständigen Kurs.
Dies sind die vier Schritte, die immer ablaufen, wenn du eine Seitenadresse wie academind.com eingibst und danach den Inhalt der Website in deinem Browser siehst.
# Serverseite vs. Browserseite
Aus den obigen vier Schritten hast du gelernt, dass wir zwei grundlegende „Seiten“ unterscheiden können, wenn wir über das Web sprechen: Serverseite und Browserseite (oder: Clientseite, da wir auch ohne Browser auf das Internet zugreifen können – siehe unten!).
Wenn du dich dafür interessierst, Webentwickler zu werden, ist es wichtig zu wissen, dass du für diese Seiten unterschiedliche Technologien und Programmiersprachen verwendest.
Serverseitig
Du brauchst serverseitige Programmiersprachen – also Sprachen, die nicht im Browser funktionieren, sondern auf einem normalen Computer laufen können (ein Server ist ja schließlich auch nur ein normaler Computer).
Beispiele wären:
- Node.js
- PHP
- Python
Wichtig: Mit Ausnahme von PHP kann man diese Programmiersprachen auch für andere Zwecke als die Webentwicklung verwenden.
Während Node.js in der Tat hauptsächlich für die serverseitige Programmierung verwendet wird (obwohl es technisch nicht darauf beschränkt ist), ist Python auch sehr beliebt für Data Science und maschinelles Lernen.
Browserseitig
Im Browser gibt es genau drei Sprachen/Technologien, die du lernen musst. Aber während die serverseitigen Sprachen Alternativen waren, sind diese drei browserseitigen Sprachen alle obligatorisch zu kennen und zu verstehen:
- HTML (für die Struktur)
- CSS (für das Styling)
- JavaScript (für dynamische Inhalte)
# „Hinter den Kulissen“ Internet
Bis jetzt haben wir über Websites gesprochen. D.h. der Fall, in dem man eine URL (z.B. „academind.com/learn“) in den Browser eingibt und eine Website zurückbekommt.
Aber das Internet ist mehr als das. In der Tat nutzen Sie es jeden Tag für mehr als nur das!
Der Kerngedanke von Anfragen und Antworten ist immer derselbe. Aber nicht jede Antwort ist unbedingt eine Website. Und nicht jede Anfrage will eine Website.
Die Metadaten, die an Anfragen und Antworten angehängt werden, steuern, welche Daten gewünscht und zurückgegeben werden. Natürlich müssen beide beteiligten Parteien (d.h. Client und Server) die angefragten und gesendeten Daten unterstützen.
Sie können z.B. nicht ein PDF von "academind.com" anfordern. Sie könnten eine solche Anfrage senden, aber Sie würden kein PDF zurückbekommen – ganz einfach, weil wir diese Art von angeforderten Daten für diese spezifische URL nicht unterstützen.
Aber es gibt viele Server, die sich darauf spezialisiert haben, URLs bereitzustellen, die bestimmte Daten zurückgeben. Solche Dienste werden auch als „APIs“ („Application Programming Interface“) bezeichnet.
Zum Beispiel senden mobile Anwendungen „unsichtbare“ HTTP-Anfragen an solche APIs (an bestimmte URLs, die ihnen bekannt sind), um Daten zu erhalten oder zu speichern. Twitter holt zum Beispiel den Tweet-Feed ab.
Und auch auf Webseiten werden solche „unsichtbaren“ Anfragen gesendet. Wenn Sie sich für unseren Newsletter anmelden (was Sie natürlich tun sollten!), wird keine neue Seite geladen. Denn die Daten werden hinter den Kulissen ausgetauscht. Auch wenn der Client in diesem Fall der Browser ist, will die Anfrage, die gesendet wird, keine Website als Gegenleistung. Und die Server-URL, die sie empfängt, bietet keine Website an – stattdessen weiß der Server, wie er mit Ihrer E-Mail-Adresse umzugehen hat.
Wir könnten hier noch viel mehr ins Detail gehen, aber dies ist bereits ein langer Artikel. Sie sollten jetzt ein gutes Verständnis dafür haben, wie das Web funktioniert und welche Kerntechnologien beteiligt sind.
Schreibe einen Kommentar