Was sind Autoencoder?
On November 11, 2021 by adminEine sanfte Einführung in Autoencoder und ihre verschiedenen Anwendungen. Außerdem verwenden diese Tutorials tf.keras,die High-Level-Python-API von TensorFlow zum Erstellen und Trainieren von Deep Learning-Modellen.
常常見到 Autoencoder 的變形以及應用,打算花幾篇的時間好好的研究一下,順便練習 Tensorflow.keras 的 API 使用。
- Was ist Autoencoder
- Typen von Autoencoder
- Anwendung von Autoencoder
- Implementierung
- Große Beispiele
- Abschluss
Schwierigkeit: ★ ★ ☆ ☆ ☆
後記: 由於 Tensorflow 2.0 alpha 已於 3/8號釋出,但此篇是在1月底完成的,故大家可以直接使用安裝使用看看,但需要更新至相對應的 CUDA10。
Was ist Autoencoder?
首先,什麼是 Autoencoder 呢? 不囉唆,先看圖吧!

Das ursprüngliche Konzept des Autoencoders ist sehr einfach: Man gibt Eingabedaten ein und erhält über ein neural-ähnliches Netzwerk genau die gleichen Daten wie die Eingabedaten.Der Encoder nimmt zunächst die Eingabedaten auf, komprimiert sie in einen kleiner dimensionierten Vektor Z und gibt diesen dann in den Decoder ein, um die ursprüngliche Größe von Z zu erhalten.Das hört sich einfach an, aber sehen wir uns doch einmal genauer an, ob es wirklich so einfach ist.

Kodierer:
Der Kodierer ist für die Komprimierung der ursprünglichen Eingabedaten in einen niedrigdimensionalen Vektor C verantwortlich. Dieses C, das wir gewöhnlich als Code, latenter Vektor oder Merkmalsvektor bezeichnen, aber ich bin gewohnt, es latenten Raum zu nennen, weil C ein verborgenes Merkmal darstellt.Der Encoder kann die Originaldaten in einen aussagekräftigen niedrigdimensionalen Vektor komprimieren, was bedeutet, dass der Autoencoder eine Dimensionalitätsreduktion hat, und die versteckte Schicht hat eine nicht-lineare Transformationsaktivierungsfunktion, so dass dieser Encoder wie eine leistungsstarke Version der PCA ist, da der Encoder nicht-lineare Transformationen durchführen kann.Dimensionsreduktion!
Decoder:
Der Decoder stellt den latenten Raum in den Eingabedaten so weit wie möglich wieder her, was eine Transformation der Merkmalsvektoren vom niedrigdimensionalen Raum in den höherdimensionalen Raum ist.
Wie misst man also, wie gut der Autoencoder funktioniert? Einfach durch den Vergleich der Ähnlichkeit der beiden ursprünglichen Eingabedaten mit den rekonstruierten Daten.Unsere Verlustfunktion kann also als …. geschrieben werden.
Verlustfunktion:

Denn wir wollen die Differenz zwischen demAutoEncoder wird mit Backpropagation trainiert, um die Gewichte zu aktualisieren, genau wie ein normales neuronales Netzwerk.die Gewichte aktualisieren.
Zusammenfassend lässt sich sagen, dass Autoencoder …. ist.
1. eine sehr verbreitete Modellarchitektur, die auch häufig für unüberwachtes Lernen verwendet wird
2. kann als Methode zur Dimensionsreduzierung für nichtlineare
3. kann zum Erlernen der Datenrepräsentation, der repräsentativen Merkmalstransformation verwendet werden
An dieser Stelle sollte es einfach sein zu verstehen, wie Autoencoder funktioniert, die Architektur ist sehr einfach, also lasst uns einen Blick auf seine Transformationen werfen!
Typen von Autoencoder
Nachdem wir die grundlegenden Prinzipien von Autoencoder erklärt haben, ist es an der Zeit, einen Blick auf die erweiterte und fortgeschrittene Verwendung von Autoencoder zu werfen, so dass Sie die umfassende Verwendung von Autoencoder sehen können!
2-1. Unet:
Unet kann als eines der Mittel zur Bildsegmentierung verwendet werden, und die Unet-Architektur kann als eine Variante des Autoencoders betrachtet werden.

2-2. rekursive Autoencoder:
Dies ist ein Netz, das neuen Eingabetext mit latentem Raum aus anderen Eingaben kombiniert; der Zweck dieses Netzes ist die Gefühlsklassifizierung.Dies kann auch als eine Variante des Autoencoders angesehen werden, der den spärlichen Text während der Eingabe extrahiert und den latenten Raum findet, der wichtig ist.

2-Seq2Seq:
Sequence to Sequence ist ein generatives Modell, das sich seit einiger Zeit großer Beliebtheit erfreut. Es ist eine wunderbare Lösung für das Dilemma, dass RNN-Typen nicht in der Lage sind, mit unbestimmten Paaren umzugehen, und hat sich bei Themen wie Chatbot- und Texterstellung bewährt.Dies kann auch als eine Art Autoencoder-Architektur angesehen werden.

Anwendungen von Autoencoder
Nachdem wir uns die vielen und vielfältigen Variationen von Autoencoder angesehen haben, wollen wir sehen, wo Autoencoder sonst noch eingesetzt werden kann!
3-1. pretrained weight
Autoencoder kann auch für pretrain of weight verwendet werden, was bedeutet, dass das Modell einen besseren Startwert findet.Zum Beispiel, wenn wir das Ziel Modell wie Ziel zu vervollständigen. versteckte Schicht ist:, so dass am Anfang verwenden wir das Konzept der Autoencoder zu 784 Dimensionen eingeben, und der latente Raum in der Mitte ist 1000 Dimensionen, um die Pretrain ersten tun, so dass diese 1000 Dimensionen können gut behalten die EingabeDann entfernen wir die ursprüngliche Ausgabe und fügen die zweite Schicht hinzu, und so weiter.Auf diese Weise erhält das gesamte Modell einen besseren Startwert.
Huh! Wenn man 1000 Neuronen verwendet, um 784 Eingabedimensionen zu repräsentieren, bedeutet das dann nicht, dass man das Netzwerk einfach noch einmal kopieren muss? Was ist der Sinn einer Ausbildung? Ja, deshalb fügen wir bei einem Pre-Training wie diesem normalerweise den L1-Norm-Regulierer hinzu, damit die versteckte Schicht nicht noch einmal kopiert wird.

Nach Aussage von Herrn Li HongyiIn der Vergangenheit war es üblicher, eine solche Methode für das Vortraining zu verwenden, aber jetzt, aufgrund der Zunahme der Ausbildungsfähigkeiten, ist es nicht mehr notwendig, diese Methode zu verwenden.Wenn Sie jedoch nur sehr wenige beschriftete Daten, aber eine Menge unbeschrifteter Daten haben, können Sie diese Methode für das Pre-Training der Gewichte verwenden, da Autoencoder selbst eine unüberwachte Lernmethode ist.Wir verwenden die unmarkierten Daten zunächst für das Pre-Training der Gewichte und verwenden dann die markierten Daten zur Feinabstimmung der Gewichte, um ein gutes Modell zu erhalten.Weitere Einzelheiten finden Sie im Video von Herrn Li, das sehr gut erklärt ist!
3-2 Bildsegmentierung
Das Unet-Modell, das wir gerade gesehen haben, sollten wir uns noch einmal ansehen, denn es ist im Grunde das häufigste Problem bei der Fehlererkennung in der taiwanesischen Fertigungsindustrie.
Zunächst müssen wir die Eingabedaten, die unsere Ausgabe sein werden, beschriften. Wir müssen ein Netz konstruieren, das Originalbild (links, Röntgenbilder von Zähnen) eingeben und die Ausgabe (rechts, Klassifizierung der Zahnstruktur) erzeugen.In diesem Fall wird der Kodierer & Dekodierer eine Faltungsschicht mit einer starken grafischen Beurteilung sein, die aussagekräftige Merkmale extrahiert und im Dekodierer wieder dekonvolutioniert, um das Segmentierungsergebnis zu erhalten.

3-3 Video zu Text
Für ein Bildbeschriftungsproblem wie dieses verwenden wir das Sequenz-zu-Sequenz-Modell, bei dem die Eingabedaten eine Reihe von Fotos sind und die Ausgabe ein Text ist, der die Fotos beschreibt.Das Sequenz-zu-Sequenz-Modell verwendet LSTM + Conv-Netz als Kodierer & Dekodierer, der eine Sequenz von aufeinanderfolgenden Aktionen & beschreiben kann, wobei der CNN-Kernel verwendet wird, um den erforderlichen latenten Raum im Bild zu extrahieren.aber diese Aufgabe ist sehr schwer zu bewältigen, also lasse ich Sie es ausprobieren, wenn Sie daran interessiert sind!

3-4 Bildsuche
Bildsuche Man gibt ein Bild ein und versucht, die nächstgelegene Übereinstimmung zu finden, aber wenn man pixelweise vergleicht, ist es wirklich einfach, dieWenn Sie Autoencoder verwenden, um das Bild zuerst in den latenten Raum zu komprimieren und dann die Ähnlichkeit auf dem latenten Raum des Bildes zu berechnen, wird das Ergebnis viel besser sein.Das Ergebnis ist wesentlich besser, da jede Dimension im latenten Raum ein bestimmtes Merkmal darstellen kann.Wenn der Abstand auf dem latenten Raum berechnet wird, ist es sinnvoll, ähnliche Bilder zu finden.Insbesondere wäre dies eine großartige Möglichkeit des unüberwachten Lernens, ohne Daten zu kennzeichnen!
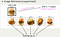
Hier sindDie Arbeit von Georey E. Hinton, dem berühmten Gott des Deep Learning, zeigt den Graphen, nach dem Sie suchen möchten, in der oberen linken Ecke, während die anderen Graphen alle Graphen sind, die der Autoencoder für sehr ähnlich hält.7133>

inhaltsbasierteBildsuche
3-5 Erkennung von Anomalien
Kann kein gutes Bild finden, also musste ich dieses nehmen LOL
Das Auffinden von Anomalien ist auch ein sehr häufiges Problem in der Produktion, also kann dieses Problem auch mit Autoencoder versucht werdenWir können es mit Autoencoder versuchen!Lassen Sie uns zunächst über das tatsächliche Auftreten von Anomalien sprechen. Anomalien treten in der Regel sehr selten auf, z. B. anormale Signale von der Maschine, plötzliche Temperaturspitzen ……, usw.Wenn alle 10 Sekunden Daten gesammelt werden, werden jeden Monat 260.000 Daten gesammelt, aber nur ein Zeitraum ist anomal, was eigentlich eine sehr unausgewogene Datenmenge ist.
Der beste Weg, mit dieser Situation umzugehen, ist also, die Originaldaten zu verwenden, die schließlich die größte Datenmenge darstellen, die wir haben!Wenn wir die guten Daten nehmen und einen guten Autoencoder trainieren können, dann werden die rekonstruierten Grafiken natürlich kaputt gehen, wenn Anomalien auftauchen.So kamen wir auf die Idee, Autoencoder zum Auffinden von Anomalien einzusetzen!

Implementierung
Hier verwenden wir Mnist als Spielzeugbeispiel und implementieren einen Autoencoder mit Hilfe der Tensorflow.keras High-Level-API! Da das neue Paket für tf.keras in Kürze veröffentlicht wurde, üben wir die Verwendung der Model-Subklassifizierungsmethode in der Datei
4-1. Ein Modell erstellen – Vallina_AE:
Zuerst importieren Sie tensorflow!7133>

Die Verwendung von tf.keras ist denkbar einfach, geben Sie einfach tf.keras ein!(Ich weiß nicht, wovon ich rede lol)
Lade Daten & Modellvorverarbeitung
Zuerst nehmen wir die Mnist-Daten aus tf.keras.dataset und machen eine kleine Vorverarbeitung
Nomalisieren: Komprimieren der Werte auf einen Wert zwischen 0 und 1, das Training wird leichter konvergieren
Binarisieren: Hervorheben der offensichtlicheren Bereiche, das Training wird bessere Ergebnisse liefern.
Create a Model – Vallina_AE:
Dies ist die Methode, die vom Tensorflow-Dokument für die Erstellung von Modellen bereitgestellt wird.komplexer.
Was ich bisher gelernt habe, ist, die Schicht in der __init __ Stelle zu erstellen und den Vorwärtspass in dem Aufruf zu definieren.
Wir verwenden also zwei sequenzielle Modelle, um den Encoder & Decoder zu erstellen. zwei sind eine symmetrische Struktur, der Encoder ist mit der Eingabeschicht verbunden, die für die Übertragung der Eingabedaten verantwortlich ist und dann mit den drei dichten Schichten. der Decoder ist der gleiche.
Auch hier müssen wir unter dem Aufruf den Kodierer & Dekodierer verketten, indem wir zunächst den latenten Raum als Ausgabe von self.encoder definieren.Raum als Ausgabe von self.encoder und dann die Rekonstruktion als Ergebnis des Durchlaufs des Decoders.Wir verwenden dann tf.keras.Model(), um die beiden in __init__ definierten Modelle zu verbinden.AE_model = tf.keras.Model(inputs = self.encoder.input, outputs = reconstruction) gibt input als den Eingang des Encoders und output als den Ausgang des Decoders an, und das war’s!Dann geben wir das AE_model zurück und das war’s!
Modell kompilieren & Training
Bevor Keras ein Modell trainieren kann, muss es kompiliert werden, bevor es in das Training aufgenommen werden kann.Bei der Kompilierung geben Sie den zu verwendenden Optimierer und den zu berechnenden Verlust an.
Für das Training verwenden Sie VallinaAE.fit, um die Daten einzugeben, aber denken Sie daran, dass wir uns selbst wiederherstellen, also müssen X und Y in die gleichen Daten geworfen werden.
Schauen wir uns die Ergebnisse des Trainings von 100 Epochen an, es sieht so aus, dass die Rekonstruktionsergebnisse nicht so gut sind, wie wir dachten.

4-2. Ein Modell erstellen- Conv_AE:
Wie der Name schon sagt, können wir die Faltungsschicht als versteckte Schicht verwenden, um Merkmale zu lernen, die wieder rekonstruiert werden können.
Nachdem Sie das Modell geändert haben, können Sie sich die Ergebnisse ansehen, um zu sehen, ob es eine Verbesserung gibt.

Es scheint, dass die Ergebnisse der Rekonstruktion viel besser sind, mit etwa 10 Epochen des Trainings.
4-3: Erstellen eines Modells – denoise_AE:
Auch der Autoencoder kann zur Rauschunterdrückung verwendet werden, so dass wir hier
Zunächst können wir dem Originalbild Rauschen hinzufügen. Die Logik des Hinzufügens von Rauschen besteht darin, eine einfache Verschiebung der Originalpixel vorzunehmen und dann Zufallszahlen hinzuzufügen.Der Teil der Bildvorverarbeitung kann durchgeführt werden, indem der Clip einfach auf 0 gesetzt wird, wenn er kleiner als 0 ist, und auf 1, wenn er größer als 1 ist. Wie unten gezeigt, können wir nach der Bildverarbeitung des Clips das Bild schärfer machen und die offensichtlichen Bereiche werden besser sichtbar.So erhalten wir ein besseres Ergebnis, wenn wir Autoencoder einsetzen.

und dem Modell selbst und Conv_AEEs gibt keinen Unterschied zwischen dem Modell selbst und Conv_AE, außer dass es während der Anpassung in
denoise_AE.fit(train_images_noise, train_images, epochs=100, batch_size=128, shuffle=True)
geändert werden muss, um die ursprünglichen noise_data auf die ursprünglichen Eingabedaten zurückzuführen

Wie Sie sehen können, erzielt ein einfacher Autoencoder auf Mnist einen sehr schnellen Entrauschungseffekt.
Große Beispiele
Dies ist eine gute Ressource für diejenigen, die mehr darüber lernen wollen
- Building Autoencoders in Keras autoencoder series is clearly written.
- Tensorflow 2.0 offizielle Dokumentation Tutorial, etwas sehr vollständig, schreiben Sie einfach ein wenig schwierig, eine ganze Menge Zeit zu verbringen, um zu sehen (zumindest ich ziehen XD)
3. Li Hongyi Lehrer des tiefen Lernens ist auch sehr zu empfehlen, sprechen sehr klar und leicht zu verstehen, nicht
Abschluss
Nutzen Sie diesen Artikel, um schnell das Grundkonzept des Autoencoders, einige Variationen des Autoencoders und die Anwendung vonSzenarien.4310>
Die nächsten Artikel beginnen mit generativen Modellen, die sich vom Konzept des Autoencoders über VAE bis hin zu GAN und weiteren Erweiterungen und Abwandlungen erstrecken.
Wenn dir der Artikel gefällt, klicke bitte noch ein paar Mal (nicht nur einmal) als Ermutigung!
Lesen Sie den vollständigen Code für diesen Artikel:https://github.com/EvanstsaiTW/Generative_models/blob/master/AE_01_keras.ipynb
Schreibe einen Kommentar