SQL CHIT CHAT … Blog om Sql Server
On november 29, 2021 by adminSummary
Common Table Expressions blev introduceret i SQL Server 2005. De repræsenterer en af flere typer af tabeludtryk, der er tilgængelige i Sql Server. En rekursiv CTE er en type CTE, der henviser til sig selv. Den bruges normalt til at opløse hierarkier.
I dette indlæg vil jeg forsøge at forklare, hvordan CTE-rekursion fungerer, hvor den befinder sig i gruppen af tabeludtryk, der er tilgængelige i Sql Server, og et par casescenarier, hvor rekursionen brillerer.
Tabeludtryk
Et tabeludtryk er et navngivet forespørgselsudtryk, der repræsenterer en relationel tabel. Sql Server understøtter fire typer tabeludtryk;
- Derived tables
- Views
- ITVF (Inline Table Valued Functions aka parameteriserede views)
- CTE (Common Table Expressions)
- Recursive CTE
Generelt set materialiseres tabeludtryk ikke på disken. De er virtuelle tabeller, der kun findes i RAM-hukommelsen (de kan blive spildt til disken som følge af f.eks. hukommelsespres, størrelsen af en virtuel tabel osv.) Tabeludtrykkets synlighed kan variere, dvs. views og ITVF er db-objekter, der er synlige på databaseniveau, mens deres anvendelsesområde altid er på SQL-anvisningsniveau – tabeludtryk kan ikke fungere på tværs af forskellige SQL-anvisninger inden for en batch.
Fordelene ved tabeludtryk er ikke relateret til forespørgselsudførelsespræstationer, men til kodens logiske aspekt !
Derived Tables
Derived tables er tabeludtryk, også kendt som subqueries. Udtrykkene er defineret i FROM-klausulen i en ydre forespørgsel. Anvendelsesområdet for afledte tabeller er altid den ydre forespørgsel.
Den følgende kode repræsenterer en afledt tabel kaldet AUSCust.
Transact-SQL
|
1
2
3
3
4
5
6
7
8
|
SELECT AUSCust.*
FROM (
SELECT custid
,companyname
FROM dbo.Customers
WHERE country = N’Australia’
) AS AUSCust;
–AUSCust er en afledt tabel
|
Den afledte tabel AUSCust er kun synlig for den ydre forespørgsel, og omfanget er begrænset til sql-erklæringen.
Views
Views (nogle gange omtalt som virtuelle relationer) er genanvendelige tabeludtryk. En view-definition gemmes som et Sql Server-objekt sammen med objekter som f.eks. brugerdefinerede tabeller, triggers, funktioner, lagrede procedurer osv.
Den største fordel ved Views i forhold til andre typer tabeludtryk er deres genanvendelighed, dvs. at afledte forespørgsler og CTE’er har et omfang, der er begrænset til en enkelt erklæring.
Views er ikke materialiserede, hvilket betyder, at de rækker, der produceres af views, ikke gemmes permanent på disken. Indekserede views er Sql Server (ligner men er ikke det samme som materialiserede views i andre db-platforme) er en særlig type views, der kan have deres resultatsæt permanent gemt på disken – mere om indekserede views kan findes her.
Der er blot et par grundlæggende retningslinjer for, hvordan man definerer SQL Views.
-
SELECT * i forbindelse med en View-definition opfører sig anderledes end når det bruges som et forespørgselselement i en batch.
Transact-SQL
123345CREATE VIEW dbo.vwTestASSELECT *FROM dbo.T1…Viewdefinitionen vil omfatte alle kolonner fra den underliggende tabel, dbo.T1, på tidspunktet for oprettelsen af viewet. Det betyder, at hvis vi ændrer tabelskemaet (dvs. tilføjer og/eller fjerner kolonner), vil ændringerne ikke være synlige for visningen – visningsdefinitionen vil ikke automatisk ændre sig for at understøtte tabelændringerne. Dette kan forårsage fejl i situationer, hvor f.eks. en visning forsøger at vælge ikke-eksisterende kolonner fra en underliggende tabel.
For at løse problemet kan vi bruge en af de to systemprocedurer: sys.sp_refreshview eller sys.sp_refreshsqlmodule.
For at forhindre denne adfærd skal du følge den bedste praksis og eksplicit navngive kolonnerne i definitionen af visningen. - Visninger er tabeludtryk og kan derfor ikke ordnes. Visninger er ikke cursors! Det er dog muligt at “misbruge” TOP/ORDER BY-konstruktionen i visningsdefinitionen i et forsøg på at fremtvinge sorteret output. f.eks .
Transact-SQL
123345CREATE VIEW dbo.MyCursorViewASSELECT TOP(100 PERCENT) *FROM dbo.SomeTableORDER BY column1 DESCQuery optimizer vil kassere TOP/ORDER BY, da resultatet af et tabeludtryk altid er en tabel – at vælge TOP(100 PERCENT) giver alligevel ikke nogen mening. Ideen bag tabelstrukturer er afledt af et begreb i relationel databaseteori kaldet Relation.
-
Ved behandling af en forespørgsel, der refererer til en visning, bliver forespørgslen fra visningsdefinitionen udfoldet eller udvidet og implementeret i forbindelse med hovedforespørgslen. Den konsoliderede kode (forespørgsel) optimeres og udføres derefter.
ITVF (Inline Table Valued Functions)
ITVF’er er genanvendelige tabeludtryk, der understøtter inputparametre. Funktionerne kan behandles som parametrerede visninger.
CTE (Common Table Expressions)
Common table expressions ligner afledte tabeller, men har flere vigtige fordele;
En CTE defineres ved hjælp af en WITH-erklæring efterfulgt af en definition af et tabeludtryk. For at undgå tvetydighed (TSQL bruger nøgleordet WITH til andre formål, f.eks. WITH ENCRYPTION osv.) SKAL den erklæring, der går forud for CTE’s WITH-klausul, afsluttes med en halvspalte. Dette er ikke nødvendigt, hvis WITH-klausulen er den allerførste erklæring i en batch, dvs. i en VIEW/ITVF-definition)
BEMÆRK: Semi-kolonne, erklæringsterminator understøttes af ANSI-standarden, og det anbefales stærkt at bruge den som en del af TSQL-programmeringspraksis.
Recursive CTE
SQL Server understøtter rekursive forespørgselsfunktioner, der er implementeret gennem rekursive CTE’er siden version 2005 (Yukon).
Elementer i en rekursiv CTE
- Ankerelement(er) – forespørgselsdefinitioner, der;
- giver en gyldig relationel resultattabel
- kun udføres KUN EN gang i begyndelsen af forespørgselsudførelsen
- altid placeres før den første rekursive medlemsdefinition
- det sidste ankerelement skal være efterfulgt af UNION ALL-operatoren. Operatoren kombinerer det sidste ankerelement med det første rekursive element
- giver en gyldig relationel resultattabel
- har henvisning til CTE-navnet. Referencen til CTE-navnet repræsenterer logisk set det foregående resultatsæt i en sekvens af udførelser. dvs. det første “foregående” resultatsæt i en sekvens er det resultat, som ankerelementet returnerede.
Terminationskontrol
CTE’s rekursive member har ingen eksplicit kontrol af rekursionsafslutning.
I mange programmeringssprog kan vi designe en metode, der kalder sig selv – en rekursiv metode. Enhver rekursiv metode skal afsluttes, når en bestemt betingelse er opfyldt. Dette er eksplicit rekursionsafslutning. Efter dette punkt begynder metoden at returnere værdier. Uden afslutningspunkt kan rekursion ende med at kalde sig selv “i det uendelige”.
CTE’s rekursive member termination check er implicit , hvilket betyder, at rekursionen stopper, når der ikke returneres nogen rækker fra den foregående CTE-eksekvering.
Her er et klassisk eksempel på en rekursion i imperativ programmering. Koden nedenfor beregner faktorialen af et heltal ved hjælp af et rekursivt funktions(metode)kald.
Komplet kode til konsolprogrammet findes her.
MAXRECURSION
Som nævnt ovenfor kan rekursive CTE’er samt enhver rekursiv operation forårsage uendelige sløjfer, hvis de ikke er designet korrekt. Denne situation kan have en negativ indvirkning på databasens ydeevne. Sql Server-motoren har en fejlsikker mekanisme, der ikke tillader uendelige udførelser.
Det antal gange, rekursivt medlem kan påberåbes, er som standard begrænset til 100 (dette tæller ikke den engangsudførelse af ankeret med). Koden vil mislykkes ved 101. udførelse af det rekursive medlem.
Msg 530, Level 16, State 1, Line xxx
Der blev afsluttet. Den maksimale rekursion 100 er blevet udtømt før erklæringens afslutning.
Antal rekursioner styres af MAXRECURSION n forespørgselsindstillingen. Indstillingen kan tilsidesætte standardantallet af maksimalt tilladte rekursioner. Parameteren (n) repræsenterer rekursionsniveauet. 0<=n <=32767
Vigtig bemærkning:: MAXRECURSION 0 – deaktiverer rekursionsgrænsen!
Figur 1 viser et eksempel på en rekursiv CTE med dens elementer

Figur 1, rekursive CTE-elementer
Deklarativ rekursion er helt anderledes end traditionel, imperativ rekursion. Ud over den forskellige kodestruktur kan vi observere forskellen mellem den eksplicitte og den implicitte afslutningskontrol. I CalculateFactorial-eksemplet er det eksplicitte afslutningspunkt klart defineret af betingelsen: if (number == 0) then return 1.
I tilfældet med rekursiv CTE ovenfor er afslutningspunktet implicit defineret af INNER JOIN-operationen, mere specifikt af resultatet af det logiske udtryk i dets ON-klausul: ON e.MgrId = c.EmpId. Resultatet af tabeloperationen bestemmer antallet af rekursioner. Dette vil blive mere klart i de følgende afsnit.
Brug rekursiv CTE til at opløse medarbejderhierarki
Der er mange scenarier, hvor vi kan bruge rekursive CTE’er, dvs. til at adskille elementer osv. Det mest almindelige scenarie, som jeg er stødt på i løbet af mange års sekvensering, har været at bruge rekursiv CTE til at løse forskellige hierarkiske problemer.
Medarbejdertræhierarkiet er et klassisk eksempel på et hierarkisk problem, der kan løses ved hjælp af rekursive CTE’er.
Eksempel
Lad os sige, at vi har en organisation med 12 medarbejdere. Følgende forretningsregler gælder;
- En medarbejder skal have et unikt id, EmpId
- håndhæves af: En medarbejder kan være administreret af 0 eller 1 leder.
- Styret af: Primary Key constraint on EmpId column
- En medarbejder kan være administreret af 0 eller 1 leder.
- Styret af: Primary Key constraint on EmpId column
- Foreign Key constraint (selvrefereret) på kolonnen MgrId
- håndhæves af: En medarbejder kan være administreret af 0 eller 1 leder.
- En leder kan ikke lede sig selv.
- forstærket af: CHECK-begrænsning på kolonnen MgrId
Træthierarkiet er implementeret i en tabel kaldet dbo.Employees. Skripterne kan findes her.

Figur 2, tabel Employees
Lad os præsentere den måde rekursive CTE fungerer på ved at besvare spørgsmålet:
Figur 3 viser hierarkietræet i figur 2, hvor vi tydeligt kan se, at Manager (EmpId = 3) direkte leder medarbejdere; EmpId=7, EmpId=8 og EmpId=9 og indirekte leder; EmpId=10, EmpId=11 og EmpId=12.
Figur 3 viser EmpId=3-hierarkiet og det forventede resultat. Koden kan findes her.

Figur 3, EmpId=3 direkte og indirekte underordnede
Så, hvordan fik vi det endelige resultat.
Den rekursive del i den aktuelle iteration refererer altid til sit tidligere resultat fra den forrige iteration. Resultatet er et tabeludtryk(eller virtuel tabel) kaldet cte1(tabellen på højre side af INNER JOIN’en). Som vi kan se, indeholder cte1 også ankerdelen. I den allerførste kørsel(den første iteration) kan den rekursive del ikke henvise til sit tidligere resultat, fordi der ikke var nogen tidligere iteration. Derfor er det i den første iteration kun ankerdelen, der udføres, og kun én gang i løbet af hele processen. Ankerforespørgselsresultatet giver den rekursive del sit tidligere resultat i den anden iteration. Ankeret fungerer om man vil som et svinghjul 🙂
Det endelige resultat opbygges gennem iterationer dvs. ankerresultat + iteration 1-resultat + iteration 2-resultat …
Den logiske udførelsessekvens
Testforespørgslen udføres ved at følge nedenstående logiske sekvens:
- SELECT-anvisningen uden for cte1-udtrykket påkalder rekursionen. Ankerforespørgslen udføres og returnerer en virtuel tabel kaldet cte1. Den rekursive del returnerer en tom tabel, da den ikke har noget tidligere resultat. Husk, at udtrykkene i den sætbaserede tilgang evalueres alle på én gang.
 Figur 4, cte1-værdi efter 1. iteration
Figur 4, cte1-værdi efter 1. iteration - Den anden iteration begynder.Dette er den første rekursion. Ankerdelen spillede sin rolle i den første iteration og returnerer fra nu af kun tomme sæt. Den rekursive del kan dog nu henvise til sit tidligere resultat (cte1-værdien efter den første iteration) i INNER JOIN-operatoren. Tabeloperationen giver resultatet af den anden iteration som vist i nedenstående figur.
 FIgure 5, cte1-værdi efter 2. iteration
FIgure 5, cte1-værdi efter 2. iteration - Den anden iteration giver et ikke-tomt sæt, så processen fortsætter med den tredje iteration – den anden rekursion. Rekursivt element refererer nu til cte1-resultatet fra anden iteration.
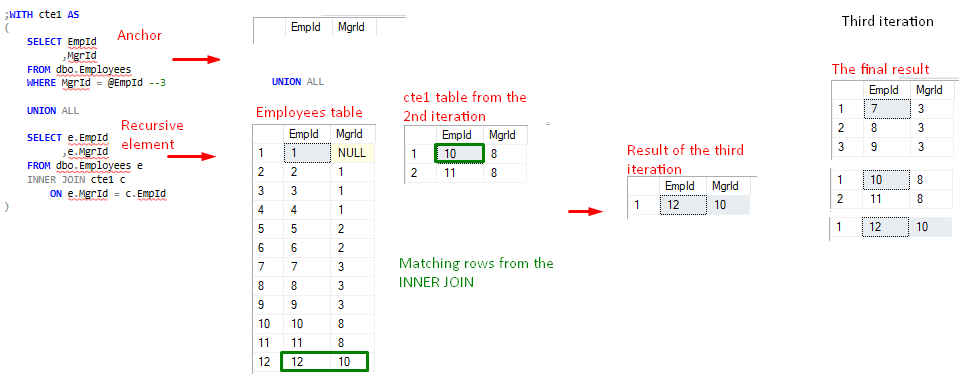
FIgure 6, cte1-værdi efter 3. iteration - Der sker en interessant ting i den 4. iteration – det tredje rekursionsforsøg. Efter det foregående mønster anvender det rekursive element cte1-resultatet fra den foregående iteration. Denne gang er der imidlertid ingen rækker, der returneres som resultat af INNER JOIN-operationen, og det rekursive element returnerer et tomt sæt. Dette er det tidligere nævnte implicitte afslutningspunkt. I dette tilfælde dikterer INNER JOIN’s logiske udtryksevaluering antallet af rekursioner.
Da det sidste cte1-resultat er et tomt resultatmængde, “annulleres” den 4. iteration (eller 3. rekursion), og processen er afsluttet med succes.
Figur 7, Den sidste iteration
Den logiske annullering af den 3. rekursion (den sidste rekursion, der producerede et tomt resultatsæt, tæller ikke) vil blive mere tydelig i det følgende afsnit om analyse af den rekursive CTE-eksekveringsplan.Vi kan tilføje OPTION(MAXRECURSION 2) forespørgselsindstillingen i slutningen af forespørgslen, hvilket vil begrænse antallet af tilladte rekursioner til 2. Forespørgslen vil give det korrekte resultat, hvilket beviser, at der kun er behov for to rekursioner til denne opgave.Bemærk: Fra det fysiske udførelsesperspektiv sendes resultatsættet progressivt(efterhånden som rækker bobler op) til netværksbufferne og tilbage til klientapplikationen.
Endeligt er svaret på ovenstående spørgsmål :
Der er seks medarbejdere, der direkte eller indirekte rapporterer til Emp = 3. Tre medarbejdere, EmpId= 7, EmpId=8 og EmpId=9 er direkte underordnede og EmpId=10, EmpId=11 og EmpId=12 er indirekte underordnede.
Ved kendskab til mekanikken i rekursiv CTE kan vi nemt løse følgende problemer.
- find alle de medarbejdere, der er hierarkisk over EmpId = 10 (kode her)
- find EmpId=8 ‘s direkte og det andet niveau underordnede(kode her)
I det andet eksempel styrer vi hierarkiets dybde ved at begrænse antallet af rekursioner.
Ankerelementet giver os det første niveau i hierarkiet, i dette tilfælde de direkte underordnede. Hver rekursion bevæger sig derefter et hierarkiniveau nedad fra det første niveau. I eksemplet er udgangspunktet EmpId=8 og hans/hendes direkte underordnede medarbejdere. Den første rekursion flytter endnu et niveau ned i hierarkiet, hvor EmpId=8 ‘s underordnede på andet niveau “bor”.
Cirkulært referenceproblem
En af de interessante ting ved hierarkier er, at medlemmerne af et hierarki kan danne en lukket sløjfe, hvor det sidste element i hierarkiet refererer til det første element. Den lukkede løkke er også kendt som cirkulær reference.
I tilfælde som dette vil det implicitte afslutningspunkt, som INNER JOIN-operationen, der er forklaret tidligere, simpelthen ikke fungere, fordi den altid vil returnere et ikke-tomt resultatsæt, så den næste rekursion kan gå videre. Rekursionsdelen vil blive ved med at rulle, indtil den rammer Sql Server’s fail-safe, MAXRECURSION forespørgselsindstillingen.
For at demonstrere cirkulær referencesituation ved hjælp af tidligere opsat testmiljø, skal vi
- Fjern Primary og Foreign key begrænsninger fra dbo.Employees tabellen for at tillade de lukkede loops scenarier.
- Skab en cirkulær reference (EmpId=10 vil administrere sin indirekte chef , EmpId = 3)
- Udvider testforespørgslen, der blev brugt i de tidligere eksempler, for at kunne analysere hierarkiet af elementerne i det lukkede loop.
Den udvidede testforespørgsel kan findes her.
Hvor vi fortsætter med eksemplet med den cirkulære ref., skal vi se, hvordan den udvidede testforespørgsel fungerer. Kommenter WHERE-klausulens prædikater (de sidste to linjer) og kør forespørgslen mod den oprindelige tabel dbo.Employee
 Figur 8, Detektering af eksistensen af cirkulære loops i hierarkier
Figur 8, Detektering af eksistensen af cirkulære loops i hierarkier
Resultatet af den udvidede forespørgsel er nøjagtig det samme som det resultat, der blev præsenteret i det foregående eksperiment i figur 3. Outputtet er udvidet til at omfatte følgende kolonner
- pth – repræsenterer grafisk det aktuelle hierarki. I første omgang, inden for ankerdelen, tilføjer den blot den første underordnede til MgrId=3, den leder, vi starter fra. Nu tager hvert rekursivt element den tidligere pth-værdi og tilføjer den næste underordnede til den.
- recLvl – repræsenterer det aktuelle rekursionsniveau. Ankerudførelse tælles som recLvl=0
- isCircRef – registrerer eksistensen af en cirkulær reference i det aktuelle hierarki(række). Som en del af det rekursive element søger den efter eksistensen af et EmpId, der tidligere var inkluderet i pth-strengen.
i.e hvis den tidligere pth ser ud som 3->8->10 og den aktuelle rekursion tilføjer ” ->3 “, (3->8 >10 -> 3) hvilket betyder at EmpId=3 ikke kun er indirekte overordnet til EmpId=10, men også er EmpId=10’s underordnede – jeg er chef eller din chef, og du er min chef slags situation 😐
Lader os nu foretage de nødvendige ændringer på dbo.Employees for at se den udvidede test forespørgsel i aktion.
Fjern PK og FK begrænsninger for at tillade cirkulære referencer og tilføj en “bad boy circular ref” til tabellen.
Kør den udvidede test forespørgsel, og analysér resultaterne (glem ikke at un-commet tidligere kommenteret WHERE klausul i slutningen af scriptet)
Scriptet vil udføre 100 rekursioner før bliver afbrudt af standard MAXRECURSION. Det endelige resultat vil være begrænset til to rekursioner … AND cte1.recLvl <= 2; hvilket er nødvendigt for at opløse EmpId=3’s hierarki.
Figur 9 viser et lukket loop-hierarki, maksimalt tilladt antal rekursioner udtømt fejl og output, der viser det lukkede loop.
Figur 10, Cirkulær reference opdaget
Et par bemærkninger om scriptet med cirkulær reference:
Scriptet er blot en idé om, hvordan man finder lukkede loops i hierarkier. Det rapporterer kun den første forekomst af en cirkulær reference – prøv at fjerne WHERE-klausulen og se resultatet.
Scriptet (eller en lignende version af scriptet) kan efter min mening bruges i produktionsmiljøet til f.eks. fejlfinding eller som forebyggelse af at skabe cirkulære referencer i et eksisterende hierarki. Det skal dog sikres med passende MAXRECURSION n, hvor n er den forventede dybde af hierarkiet.
Dette script er ikke-relationelt og er baseret på en traversal-teknik. Det er altid den bedste fremgangsmåde at bruge deklarative begrænsninger (PK, FK, CHECK..) for at forhindre lukkede sløjfer i data.
Udførelsesplananalyse
Dette segment forklarer, hvordan Sql Server’s query optimizer(QO) implementerer en rekursiv CTE. Der er et fælles mønster, som QO bruger, når han konstruerer udførelsesplanen. Kør den oprindelige testforespørgsel og medtag den faktiske udførelsesplan
Som testforespørgslen har udførelsesplanen to grene: ankergrenen og den rekursive gren. Concatenation-operatoren, som implementerer UNION ALL-operatoren, forbinder resultaterne fra de to dele, der danner forespørgselsresultatet.
Lad os prøve at forene den logiske udførelsessekvens, der er nævnt før, og den faktiske implementering af processen.
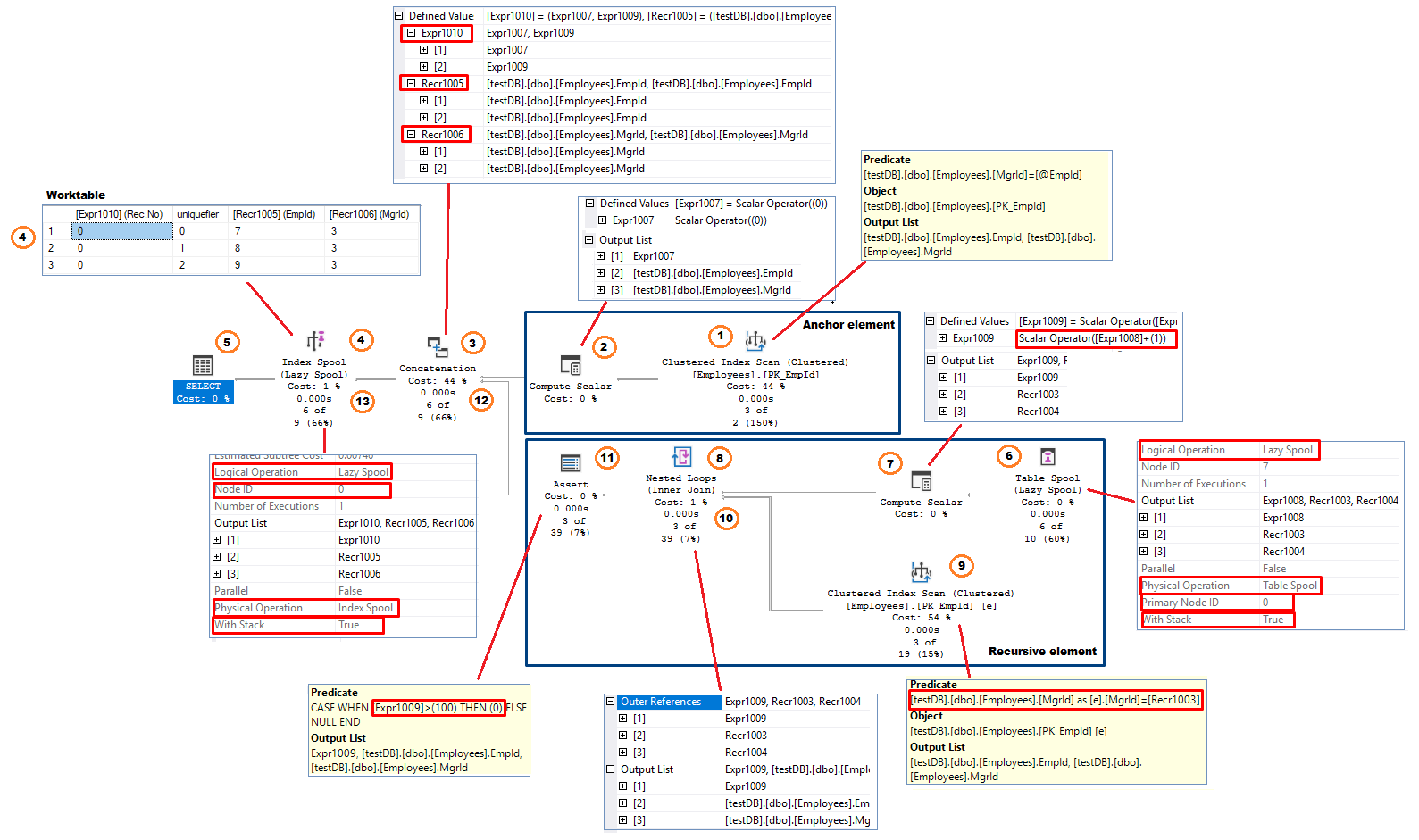
Figur 11, rekursiv CTE-udførelsesplan
Følge datastrømmen (fra højre til venstre retning) ser processen ud som:
Ankerelement (udføres kun én gang)
- Operatøren Clustered Index Scan – systemet udfører indeksscanning. I dette eksempel anvender det udtrykket MgrId = @EmpId som et residualprædikat. Udvalgte rækker (kolonnerne EmpId og MgrId) sendes (række for række) tilbage til den foregående operatør.
- Compute Scalar Operatøren tilføjer en kolonne til output. I dette eksempel er navnet på den tilføjede kolonne . Dette repræsenterer antallet af rekursioner. Kolonnen har den oprindelige værdi 0; =0
- Sammenkædning – kombinerer indgange fra de to grene. I den første iteration modtager operatoren kun rækker fra ankergrenen. Den ændrer også navnene på udgangskolonnerne. I dette eksempel er de nye kolonnenavne:
- = eller * * * indeholder antallet af rekursioner, der er tildelt i den rekursive gren. Den har ikke værdi i den første iteration.
- = EmpId(fra ankerdelen) eller EmpId(fra den rekursive del)
- = MgrId(fra ankerdelen) eller MgrId (fra den rekursive del)
- Index Spool (Lazy Spool) Denne operatør gemmer det resultat, der er modtaget fra operatoren Concatenation, i en arbejdstabel. Den har egenskaben “Logical Operation” sat til “Lazy Spool”. Det betyder, at operatoren returnerer sine inputrækker straks og ikke akkumulerer alle rækker, før den får det endelige resultatsæt (Eager Spool) . Arbejdstabellen er struktureret som et clusteret indeks med nøglekolonnen – rekursionsnummeret. Da indeksnøglen ikke er entydig, tilføjer systemet en intern 4-bytes entydighedskode til indeksnøglen for at sikre, at alle rækker i indekset ud fra et fysisk implementeringsperspektiv er entydigt identificerbare. Operatoren har også egenskaben “With Stack” sat til “True”, hvilket gør denne version af spool-operatoren til en Stack Spool En Stack Spool-operator har altid to komponenter – en Index Spool, der opbygger indeksstrukturen, og en Table Spool, der fungerer som forbruger af de rækker, der er lagret i den arbejdstabel, som blev opbygget af Index Spool’en.
På dette stadium returnerer Index Spool-operatoren rækker til SELECT-operatoren og gemmer de samme rækker i arbejdstabellen. - SELECT-operatoren returnerer EmpId og MgrId ( , ). Den udelukker fra resultatet. Rækkerne sendes til netværksbufferen, efterhånden som de ankommer fra operatørerne nedstrøms
Når alle rækker fra operatoren Index Scan er opbrugt, skifter Concatenation-operatoren kontekst til den rekursive gren. Ankergrenen vil ikke blive udført igen i løbet af processen.
Rekursivt element
- Table Spool (Lazy Spool). Operatoren har ingen indgange og fungerer som nævnt i (4) som en forbruger af de rækker, der produceres af Index Spool og lagres i et klynget arbejdsbord. Den har egenskaben “Primary Node” sat til 0, som peger på Index Spool Node Id. Det viser, at de to operatører er afhængige af hinanden. Operatøren
- fjerner de rækker, den har læst i den foregående rekursion. Dette er den første rekursion, og der er ingen tidligere læste rækker, der skal slettes. Arbejdstabellen indeholder tre rækker (figur 4).
- Læste rækker sorteret efter indeksnøglen + entydighedsnøgle i faldende rækkefølge. I dette eksempel er den første læste række EmpId=9, MgrId=3.
Slutteligt omdøber operatøren outputkolonnens navne. =, = og bliver til .
BEMÆRK: Tabellen spool-operatoren kan observeres som cte1-udtrykket på højre side af INNER JOIN (figur 4) - Compute Scalar Operatoren tilføjer 1 til det aktuelle antal rekursioner, der tidligere er gemt i kolonne .Resultatet gemmes i en ny kolonne, . = + 1 = 0 + 1 = 1 = 1. Operatoren udsender tre kolonner, de to fra Table Spool ( og ) og
- Nested Loop(I) operatoren modtager rækker fra sit ydre input, som er Compute Scalar fra det foregående trin, og bruger derefter – repræsenterer EmpId fra Table Spool operatoren, som et restprædikat i Index Scan operatoren, der er placeret i Loopens indre input. Det indre input udføres én gang for hver række fra det ydre input.
- Operatoren Index Scan returnerer alle kvalificerede rækker fra tabellen dbo.Employees (to kolonner; EmpId og MgrId) til operatoren for den indlejrede løkke.
- Indlejret løkke(II): Operatoren kombinerer fra det ydre input og EmpId og MgrId fra det indre input og sender de tre kolonnerækker til den næste operatør.
- Assert-operatoren bruges til at kontrollere for betingelser, der kræver, at forespørgslen afbrydes med en fejlmeddelelse. I tilfælde af rekursive CTE’er implementerer assert-operatoren “MAXRECURSION n”-forespørgselsindstillingen. Den kontrollerer, om den rekursive del har nået det tilladte (n) antal rekursioner eller ej. Hvis det aktuelle antal rekursioner (se trin 7) er større end (n), returnerer operatoren 0, hvilket giver en køretidsfejl. I dette eksempel bruger Sql Server sin standardværdi MAXRECURSION på 100. Udtrykket ser således ud: CASE WHEN WHEN > 100 THEN 0 ELSE NULL Hvis vi beslutter at udelukke fejlsikringen ved at tilføje MAXRECURSION 0, vil assert-operatoren ikke blive medtaget i planen.
- Sammenkædning kombinerer input fra de to grene. Denne gang modtager den kun input fra den rekursive del og udsender kolonner/rækker som vist i trin 3.
- Index Spool (Lazy Spool) tilføjer output fra concatenation-operatoren til arbejdstabellen og sender den derefter videre til SELECT-operatoren. På dette tidspunkt indeholder arbejdstabellen i alt 4 rækker: tre rækker fra ankerudførelsen og én fra den første rekursion. I overensstemmelse med arbejdstabellens clusterede indeksstruktur lagres den nye række i slutningen af arbejdstabellen
-
Processen genoptages nu fra trin 6. Table spool-operatoren fjerner tidligere læste rækker (de første tre rækker) fra arbejdstabellen og læser den sidste indsatte række, den fjerde række.
Slutning
CTE(Common table expressions) er en type af tabeludtryk, der er tilgængelig i Sql Server. En CTE er et uafhængigt tabeludtryk, der kan navngives og refereres én eller flere gange i hovedforespørgslen.
En af de vigtigste anvendelser af CTE’er er at skrive rekursive forespørgsler. Rekursive CTE’er følger altid den samme struktur – anker forespørgsel, UNION ALL multi-sæt operatør, rekursivt medlem og den erklæring, der påkalder rekursion. Rekursiv CTE er deklarativ rekursion og har som sådan andre egenskaber end dens imperative modstykke, f.eks. er deklarativ rekursions afslutningstjek af implicit karakter – rekursionsprocessen stopper, når der ikke returneres nogen rækker i den foregående CTE.
Skriv et svar