Sådan fungerer nettet
On oktober 15, 2021 by adminNettet er overalt!
Vi bruger det mere end nogensinde før – også mange steder, hvor du måske ikke ser det. For “nettet” er mere end blot websteder, som du besøger ved at indtaste en URL i din browser.
Uanset om du tjekker dine e-mails på din mobiltelefon, eller om du sender et tweet – du bruger internettet (dvs. “nettet”).
Hvordan fungerer det hele? Hvilke teknologier er involveret, og hvad skal du lære (og i hvilket omfang), hvis du vil blive webudvikler?
I denne artikel og video (se ovenfor) vil jeg ikke dykke ned i alle de tekniske detaljer. Det er ment som et godt overblik over webfunktionaliteten.

CSS – Den komplette guide
Tiltræd dette omfattende kursus på 20 timer og derover for at mestre CSS og lære at skabe smukke hjemmesider.

JavaScript – Den komplette guide
Lær JavaScript fra bunden for at bygge meget interaktive og dynamiske websteder på dette praktiske kursus!
# Sådan fungerer websteder
Lad os starte med den mest indlysende måde at bruge internettet på: Du besøger et websted som academind.com.
Det øjeblik du indtaster denne adresse i din browser og trykker på ENTER, sker der en masse forskellige ting:
- URL’en bliver opløst
- En forespørgsel sendes til webstedets server
- Serverens svar analyseres
- Siden bliver gengivet og vist

Tilstede, hvert enkelt trin kunne opdeles i flere andre trin, men for at få et godt overblik over, hvordan det hele fungerer, er det noget, vi kan ignorere her. Lad os se på alle fire trin.
Strin 1 – URL bliver opløst
Webstedskoden er naturligvis ikke gemt på din maskine og skal derfor hentes fra en anden computer, hvor den er gemt. Denne “anden computer” kaldes en “server”. Fordi den tjener et eller andet formål, i vores tilfælde tjener den webstedet.
Du indtaster “academind.com” (det kaldes “et domæne”), men faktisk identificeres den server, som er vært for kildekoden til et websted, via IP-adresser (= Internet Protocol). Browseren sender en “anmodning” (se trin 2) til serveren med den IP-adresse, du har indtastet (indirekte – du har naturligvis indtastet “academind.com”).
I virkeligheden indtaster man også ofte "academind.com/learn" eller noget i den stil. "academind.com" er domænet, "/learn" er den såkaldte sti. Sammen udgør de “URL” (“Uniform Resource Locator”).
Dertil kommer, at du kan besøge de fleste websteder via "www.academind.com" eller blot "academind.com". Teknisk set er "www" et subdomæne, men de fleste websteder omdirigerer blot trafikken til "www" til hovedsiden.
En IP-adresse ser typisk sådan her ud: 172.56.180.5 (der findes dog også en mere “moderne” form kaldet IPv6 – men lad os ignorere den for nu). Du kan lære mere om IP-adresser på Wikipedia.
Hvordan oversættes domænet “academind.com” til dets IP-adresse?
Der er en særlig type server derude på internettet – ikke bare én, men mange servere af den type. En såkaldt “navneserver” eller “DNS-server” (hvor DNS = “Domain Name System”).
Disse DNS-servere har til opgave at oversætte domæner til IP-adresser. Man kan forestille sig disse servere som enorme ordbøger, der gemmer oversættelsestabeller: Domæne => IP-adresse.
Når du indtaster “academind.com”, henter browseren derfor først IP-adressen fra en sådan DNS-server.
Hvis du nu skulle undre dig: Når IP-adressen er kendt, går vi videre til trin 2.
Strin 2 – Anmodning sendes
Med IP-adressen løst, går browseren videre og sender en anmodning til serveren med den pågældende IP-adresse.
“En anmodning” er ikke bare et udtryk. Det er virkelig en teknisk ting, der sker bag kulisserne.
Browseren samler en masse oplysninger (Hvad er den nøjagtige URL-adresse? Hvilken type forespørgsel skal der foretages? Skal der vedhæftes metadata) og sender denne datapakke til IP-adressen.
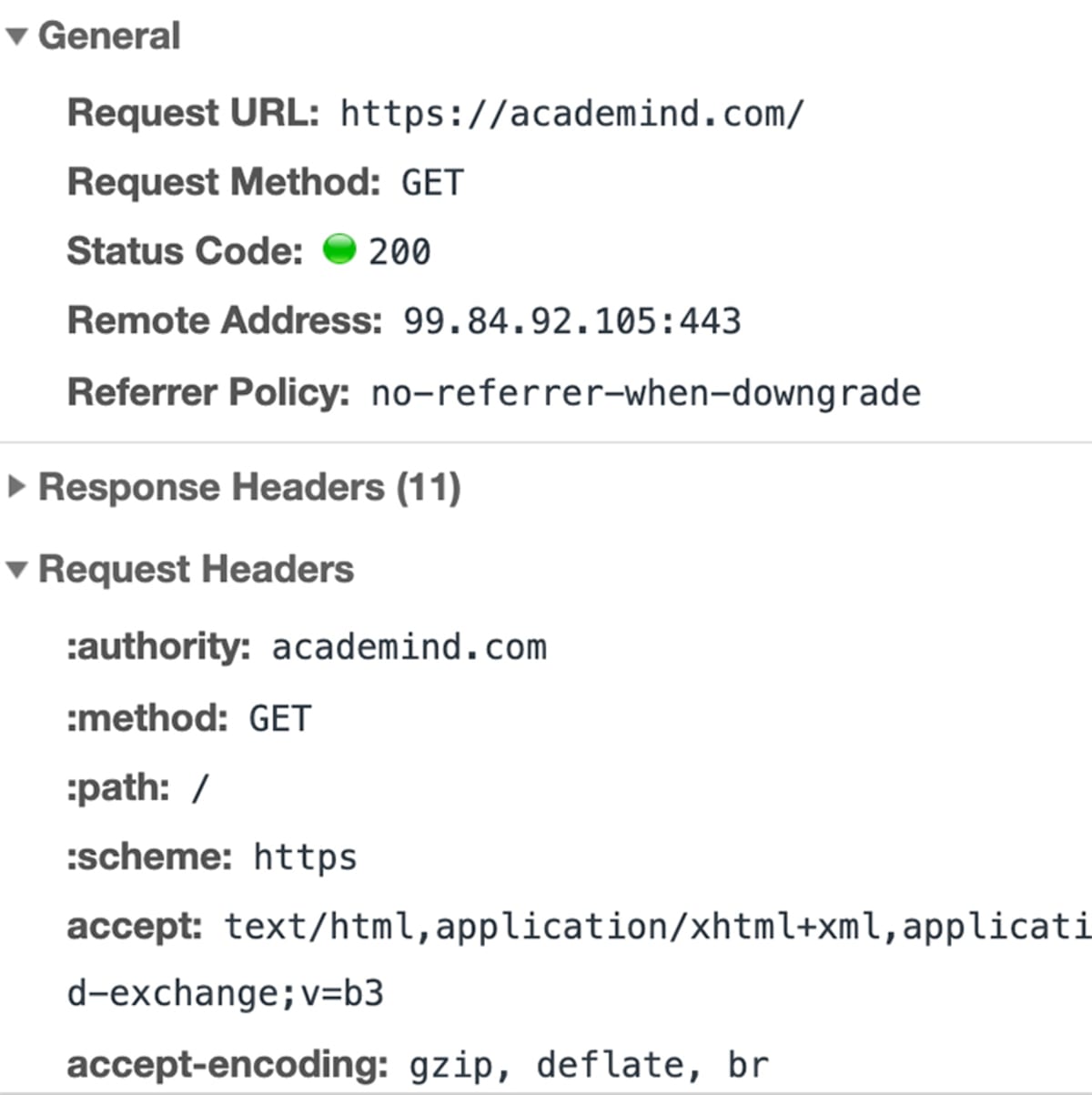
Dataene sendes via “HyperText Transfer Protocol” (kendt som “HTTP”) – en standardiseret protokol, der definerer, hvordan en anmodning (og et svar) skal se ud, hvilke data der må medtages (og i hvilken form), og hvordan anmodningen skal sendes. Du kan få mere at vide om HTTP her.
Da HTTP anvendes, ser en fuld URL faktisk sådan her ud: http://academind.com. Browseren udfylder den automatisk for dig.
Og der er også HTTPS – det er ligesom HTTP, men krypteret. De fleste moderne sider (herunder academind.com) bruger det i stedet for HTTP. En fuld URL bliver så til: https://academind.com.
Da hele processen og formatet er standardiseret, er der ikke noget at gætte på, hvordan denne anmodning skal læses af serveren.
Serveren behandler derefter anmodningen på passende vis og returnerer et såkaldt “svar”. Igen, et “svar” er en teknisk ting og svarer lidt til en “anmodning”. Man kan sige, at det grundlæggende er en “anmodning” i den modsatte retning.
Som en anmodning kan et svar indeholde data, metadata osv. Når der anmodes om en side som academind.com, vil svaret indeholde den kode, der er nødvendig for at gengive siden på skærmen.
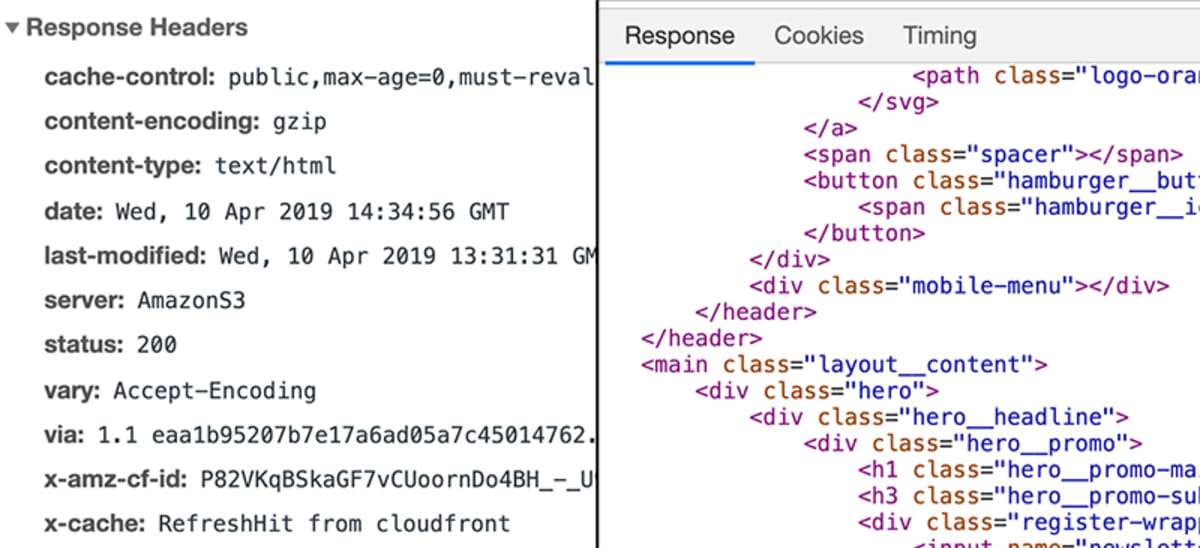
Hvad sker der på serveren?
Det er defineret af webudviklere. I sidste ende skal der sendes et svar. Dette svar behøver ikke at indeholde “et websted”. Det kan indeholde alle data – herunder filer eller billeder.
Nogle servere er programmeret til at generere websteder dynamisk på baggrund af anmodningen (f.eks. en profilside, der indeholder dine personlige data), andre servere returnerer på forhånd genererede HTML-sider (f.eks. en nyhedsside). Eller begge dele gøres – for forskellige dele af en webside. Der findes også et tredje alternativ: Websites, der er genereret på forhånd, men som ændrer udseende og data i browseren.
De forskellige typer websites er egentlig ikke fokus for denne artikel. Hvis du vil vide mere om det, kan du tjekke denne artikel + video.
I vores simple tilfælde har vi en server, der returnerer koden til at vise et websted. Så lad os fortsætte med trin 3.
Stræk 3 – Svaret analyseres
Browseren modtager det svar, som serveren har sendt. Dette alene viser dog ikke noget på skærmen.
I stedet er det næste trin, at browseren analyserer svaret. Ligesom serveren gjorde det med anmodningen. Igen hjælper den standardisering, som HTTP påtvinger, naturligvis.
Browseren kontrollerer de data og metadata, der er vedlagt i svaret. Og på baggrund af det beslutter den, hvad den skal gøre.
Du har måske oplevet tilfælde, hvor en PDF-fil blev åbnet i din browser. Det skete, fordi svaret informerede browseren om, at dataene ikke er et websted, men i stedet et PDF-dokument. Og browseren forsøger at vælge den bedste håndteringsmekanisme for enhver datatype, den registrerer.
Tilbage til vores webstedsscenarie.
I det tilfælde ville svaret indeholde et specifikt stykke metadata, der fortæller browseren, at svardataene er af typen text/html.
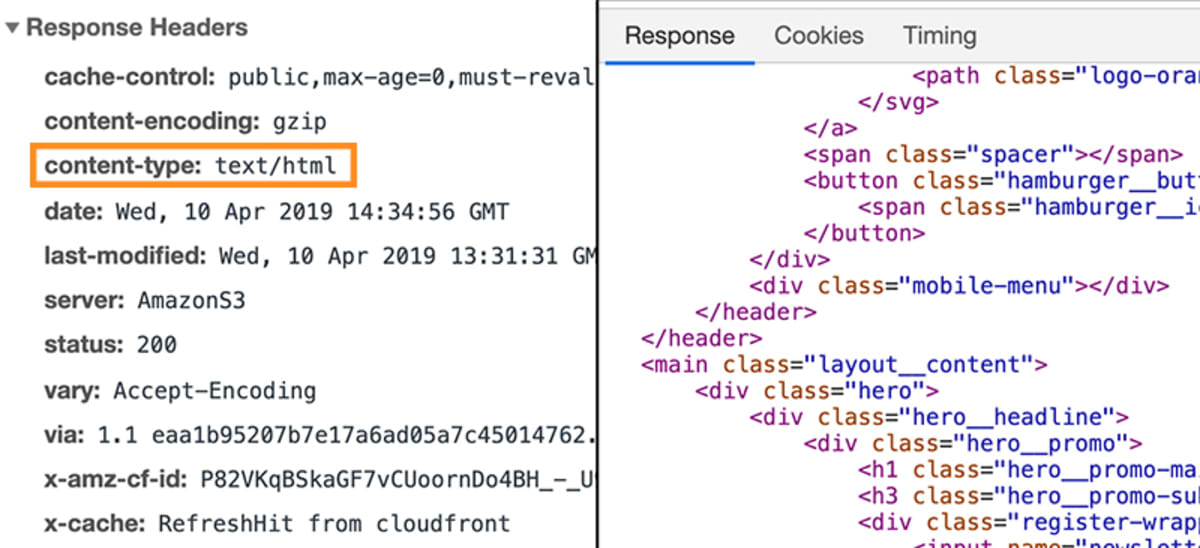
Dette gør det muligt for browseren at analysere de faktiske data, der er knyttet til svaret, som HTML-kode.
HTML er det centrale “programmeringssprog” (teknisk set er det ikke et programmeringssprog – man kan ikke skrive nogen logik med det) på internettet. HTML står for “Hyper Text Markup Language” og beskriver strukturen af en webside.
Koden ser således ud:
<h1>Breaking News!</h1><p>Websites work because browser understand HTML!</p><h1> og <p> er såkaldte “HTML-tags”, og hvis du vil lære mere om HTML, er denne serie et godt sted at gå hen.
Hvert HTML-tag har en eller anden semantisk betydning, som browseren forstår, fordi HTML også er standardiseret. Derfor skal man ikke gætte sig frem til, hvad et <h1>-tag betyder.
Browseren ved, hvordan HTML skal analyseres, og nu skal den blot gennemgå hele svardataene (også kaldet “response body”) for at gengive webstedet.
Strin 4 – Siden vises
Som nævnt gennemgår browseren de HTML-data, der returneres af serveren, og opbygger et websted på baggrund heraf.
Det er dog vigtigt at vide, at HTML ikke indeholder nogen instruktioner om, hvordan webstedet skal se ud (dvs. hvordan det skal være stylet). Det definerer egentlig kun strukturen og fortæller browseren, hvilket indhold der er en overskrift, hvilket indhold der er et billede, hvilket indhold der er et afsnit osv. Dette er især vigtigt for tilgængeligheden – skærmlæsere får alle de nyttige oplysninger ud af HTML-strukturen.
En side, der kun indeholder HTML, ville dog se således ud:

Det er ikke så smukt, vel?
Der er derfor, at der er en anden vigtig teknologi (et andet “programmeringssprog”, som egentlig ikke er et programmeringssprog): CSS (“Cascading Style Sheets”).
CSS handler om at tilføje styling til webstedet. Det sker via “CSS-regler”:
h1 { color: blue;}Denne regel ville farve alle <h1>-tags blå.
Regler som denne kan tilføjes inde i HTML-koden, men typisk er de en del af separate .css-filer, som der anmodes om separat.
Suden at dykke ned i for mange detaljer her, har det en vigtig konsekvens: Et websted kan bestå af mere end dataene i det første svar, vi får.
I praksis henter websteder en masse yderligere data (via yderligere forespørgsler og svar), som bliver sat i gang, når det første svar er kommet.
Hvordan fungerer det?
Jamen, HTML-koden i det første svar indeholder simpelthen instruktioner om at hente flere data via nye anmodninger – og browseren forstår disse instruktioner:
<link rel="stylesheet" href="/page-styles.css" />
Og jeg vil ikke dykke ned i flere detaljer her. Hvis du vil lære mere om CSS, vil vores Complete Guide være meget nyttig!
Sammen med CSS er browseren i stand til at vise websider som denne:

Der er faktisk et andet programmeringssprog involveret (denne gang er det virkelig et programmeringssprog!): JavaScript.
Det er ikke altid synligt, men alt dynamisk indhold, som du finder på et websted (f.eks. faner, overlejringer osv.), er faktisk kun muligt takket være JavaScript. Det giver webudviklere mulighed for at definere kode, der kører i browseren (ikke på serveren), og derfor kan JavaScript bruges til at ændre webstedet, mens brugeren ser det.
Som tidligere, hvis du vil lære mere, kan du tjekke vores JavaScript-ressourcer, f.eks. vores komplette kursus.
Dette er de fire trin, der altid er involveret, når du indtaster en sideadresse som academind.com, og du herefter ser hjemmesidens indhold i din browser.
# Server-side vs. browser-side
Fra de fire trin ovenfor har du lært, at vi kan skelne mellem to centrale “sider”, når vi taler om internettet: Server-side og Browser-side (eller: Client-side, da vi også kan få adgang til internettet uden en browser – se nedenfor!).
Hvis du er interesseret i at blive webudvikler, er det vigtigt at vide, at man bruger forskellige teknologier og programmeringssprog til disse sider.
Server-side
Du har brug for server-side programmeringssprog – dvs. sprog, der ikke fungerer i browseren, men som kan køre på en normal computer (en server er i sidste ende bare en normal computer).
Eksempler kunne være:
- Node.js
- PHP
- Python
Vigtigt: Med undtagelse af PHP kan du også bruge disse programmeringssprog til andre formål end webudvikling.
Selv om Node.js faktisk primært bruges til server-side programmering (selv om det teknisk set ikke er begrænset til det), er Python også meget populært til datalogi og maskinlæring.
Browser-side
I browseren er der præcis tre sprog/teknologier, du skal lære. Men mens de server-side sprog var alternativer, er disse tre browser-side sprog alle obligatoriske at kende og forstå:
- HTML (for strukturen)
- CSS (for styling)
- JavaScript (for dynamisk indhold)
# “Behind the Scenes” Internet
Så langt har vi diskuteret websteder. Dvs. det tilfælde, hvor man indtaster en URL (f.eks. “academind.com/learn”) i browseren, og man får et websted tilbage.
Men internettet er mere end det. Du bruger det faktisk til mere end det hver dag!
Den centrale idé med forespørgsler og svar er altid den samme. Men ikke alle svar er nødvendigvis et websted. Og det er ikke alle anmodninger, der ønsker et websted.
De metadata, der er knyttet til anmodninger og svar, styrer, hvilke data der ønskes og returneres. Selvfølgelig skal begge parter, der er involveret (dvs. klient og server), understøtte requestes og sendte data.
Du kan f.eks. ikke anmode om en PDF fra "academind.com". Du kunne sende en sådan anmodning, men du ville ikke få en PDF tilbage – ganske enkelt fordi vi ikke understøtter denne type anmodede data for denne specifikke URL.
Men der er mange servere, der har specialiseret sig i at levere URL’er, der returnerer visse data. Sådanne tjenester kaldes også “API’er” (“Application Programming Interface”).
Mobilapps sender f.eks. “usynlige” HTTP-forespørgsler til sådanne API’er (til specifikke URL’er, som de kender) for at hente eller gemme data. Twitter henter f.eks. tweet-feed.
Og selv på websider sendes der sådanne “usynlige” anmodninger. Hvis du tilmelder dig vores nyhedsbrev (hvilket du naturligvis bør gøre!), bliver der ikke indlæst nogen ny side. Fordi der udveksles data bag kulisserne. Selv om klienten i dette tilfælde er browseren, ønsker den anmodning, der sendes, ingen hjemmeside til gengæld. Og den server-URL, der modtager den, tilbyder intet websted – i stedet ved serveren, hvordan den skal håndtere din e-mail-adresse.
Vi kunne gå meget mere i detaljer her, men dette er allerede en lang artikel. Du skulle nu have en god forståelse af, hvordan internettet fungerer, og hvilke centrale teknologier der er involveret.
Skriv et svar