Sådan bruger du Tesseract på Windows
On januar 14, 2022 by admin
Tesseract er et program til optisk tegngenkendelse, som er udviklet af Google. Det er et open source OCR-værktøj. Der findes mange versioner af tesseract, men vi vil bruge version 4.0.
I version 4 har Tesseract implementeret en LSTM (Long Short Term Memory)-baseret genkendelsesmotor. LSTM er en slags Recurrent Neural Network (RNN). Den LSTM-baserede genkendelse fungerer meget mere effektivt end de gamle (CNN-baserede) genkendelsesprocesser.
Takket være tesseract vil vi kunne gemme indholdet af vores billeder som tekstfiler.
Installation
Den isntallation er afhænger af dit operativsystem. Nu skal vi gå igennem vinduerne. Lad os først downloade og installere tesseract gennem dette link. (Den downloader en exe-fil.) Vi konfigurerer exe-filen nemt.
Derpå skal vi tilføje en PATH til Windows-systemvariabler. Faktisk er det et nemt skridt. Først finder vi og kopierer rodmappen for tesseract-installationen. Den skal se sådan ud :
C:\Program Files\Tesseract-OCR
Og derefter i søgelinjen i Windows Advanced System Settings
Advanced system settings > Advanced > Environment variables > PATH > New
Vi indsætter kildestien, som er kopieret, og vi gemmer disse konfigurationer. Efter dette trin skal computeren genstartes for at anvende konfigurationer.
Den tesseract-installation er afsluttet. Du kan bekræfte installationen fra kommandolinjen. Når vi kører tesseract-kommandoen på kommandolinjen, bør den give os oplysninger om programmet.
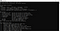
Nu kan vi gå videre til python-delen. For at bruge tesseract på python skal vi downloade pytesseract-biblioteket. Dette bibliotek kan downloades via pip til det miljø, du bruger.
pip install pytesseract
Nu er tesseract klar til brug!!!
Kodning
Det er virkelig simpelt at bruge tesseract. Den svære del er optimeringen af indstillingerne.
For hvis du vil lave en vellykket ocr, skal du være omhyggelig i billedbehandlingstrin og ocr-indstillinger.
Lad os anvende OCR på kvitteringen.

Import af bibliotekerne
import pytesseract
from PIL import Image
import cv2
import numpy as np
Indstilling af DPI-værdi for billede
Dots per inch (DPI, eller dpi) er et mål for video eller billedscannerens punkttæthed. DPI-værdien er en vigtig ting for at køre OCR. Fordi hvis DPI-værdien er lavere end 300, kan det reducere succesen af OCR.
file_path= 'receipt.jpg'
im = Image.open(file_path)
im.save('ocr.png', dpi=(300, 300))
Anvendelse af nogle teknikker til at gøre billedet renere
Først skalerer vi vores billede med x2. Hvis tegnene er små, skal vi skalere billedet for at kunne genkende det. Derefter anvender vi en simpel tærskelteknik. Det er en binær tærskel. Først skal du prøve med 127-værdien, hvorefter du kan prøve forskellige variabler. Tærskelværdien ændrer pixelen med sort, hvis pixelværdien er over tærskelværdien. Hvis vi laver billedet i gråskala, vil det give os et sort-hvidt billede.
Der findes forskellige tærskelteknikker. Du kan tjekke kildewebstedet med dette link.

Kørsel af Tesseract
Nu kan vi køre Tesseract. Den har en image_to_string()-funktion. Den giver os en streng som output.
text = pytesseract.image_to_string(treshold)
Save Output
Vi kan gemme outputtet med følgende kode.
with open("Output.txt", "w",5 ,"utf-8") as text_file:
text_file.write(text)
OCR-outputtet fra OCR’en ser således ud:
Resultatet er meget vellykket. Hvis der ønskes større succes, kan man anvende forskellige operationer på billedet.
Skriv et svar