SQL CHIT CHAT … Blog o Sql Serveru
On 29 listopadu, 2021 by adminSouhrn
V SQL Serveru 2005 byly zavedeny společné tabulkové výrazy. Představují jeden z několika typů tabulkových výrazů dostupných v systému Sql Server. Rekurzivní CTE je typ CTE, který odkazuje sám na sebe. Obvykle se používá k řešení hierarchií.
V tomto příspěvku se pokusím vysvětlit, jak rekurze CTE funguje, kde se nachází ve skupině tabulkových výrazů dostupných v Sql Serveru a několik případových scénářů, kde rekurze zazáří.
Tabulkové výrazy
Tabulkový výraz je pojmenovaný dotazový výraz, který reprezentuje relační tabulku. Sql Server podporuje čtyři typy tabulkových výrazů;
- Odvozené tabulky
- Pohledy
- ITVF (Inline Table Valued Functions alias parametrizované pohledy)
- CTE (Common Table Expressions)
- Rekurzivní CTE
Obecně se tabulkové výrazy na disku nematerializují. Jsou to virtuální tabulky přítomné pouze v paměti RAM (na disk se mohou přelévat v důsledku mj. vytížení paměti, velikosti virtuální tabulky atd…). Viditelnost tabulkových výrazů se může lišit, tj. pohledy a ITVF jsou db objekty viditelné na úrovni databáze, zatímco jejich rozsah je vždy na úrovni SQL příkazu – tabulkové výrazy nemohou pracovat napříč různými sql příkazy v rámci dávky.
Výhody tabulkových výrazů nesouvisí s výkonností provádění dotazů, ale s logickou stránkou kódu !
Odvozené tabulky
Odvozené tabulky jsou tabulkové výrazy známé také jako poddotazy. Tyto výrazy jsou definovány v klauzuli FROM vnějšího dotazu. Obsahem odvozených tabulek je vždy vnější dotaz.
Následující kód představuje odvozenou tabulku s názvem AUSCust.
Transact-.SQL
|
1
2
3
4
5
6
7
8
|
SELECT AUSCust.*
FROM (
SELECT custid
,companyname
FROM dbo.Customers
WHERE country = N’Australia‘
) AS AUSCust;
–AUSCust je odvozená tabulka
|
Odvozená tabulka AUSCust je viditelná pouze pro vnější dotaz a její rozsah je omezen na příkaz sql.
Pohledy
Pohledy (někdy označované jako virtuální vztahy) jsou opakovaně použitelné tabulkové výrazy. Definice pohledu je uložena jako objekt Sql Serveru spolu s objekty, jako jsou; uživatelsky definované tabulky, spouštěče, funkce, uložené procedury atd.
Hlavní výhodou pohledů oproti jiným typům tabulkových výrazů je jejich opakované použití, tj. odvozené dotazy a CTE mají rozsah omezený na jeden příkaz.
Pohledy nejsou materializovány, což znamená, že řádky vytvořené pohledy nejsou trvale uloženy na disku. Indexované pohledy je Sql Server(podobné, ale ne stejné jako materializované pohledy v jiných db platformách) jsou speciálním typem pohledů, které mohou mít svou výslednou sadu trvale uloženou na disku – více o indexovaných pohledech najdete zde.
Jen několik základních pokynů, jak definovat SQL pohledy.
-
Vybrat * v kontextu definice pohledu se chová jinak, než když je použit jako prvek dotazu v dávce.
Transact-SQL
12345CREATE VIEW dbo.vwTestASSELECT *FROM dbo.T1…Definice zobrazení bude obsahovat všechny sloupce z podkladové tabulky dbo.T1 v době vytvoření zobrazení. To znamená, že pokud změníme schéma tabulky (tj. přidáme a/nebo odebereme sloupce), změny se v pohledu neprojeví – definice pohledu se automaticky nezmění tak, aby podporovala změny v tabulce. To může způsobit chyby v situacích, kdy se např. pohled snaží vybrat neexistující sloupce z podkladové tabulky.
Problém můžeme vyřešit jednou ze dvou systémových procedur: sys.sp_refreshview nebo sys.sp_refreshsqlmodule.
Chceme-li tomuto chování předejít, dodržujeme osvědčený postup a v definici pohledu explicitně pojmenováváme sloupce. - Pohledy jsou tabulkové výrazy, a proto je nelze uspořádat. Pohledy nejsou kurzory! Je však možné „zneužít“ konstrukci TOP/ORDER BY v definici pohledu ve snaze vynutit si setříděný výstup. např.
Transakce-SQL
12345CREATE VIEW dbo.MyCursorViewASSELECT TOP(100 PERCENT) *FROM dbo.SomeTableORDER BY column1 DESCOptimalizátor dotazu zahodí TOP/ORDER BY, protože výsledkem tabulkového výrazu je vždy tabulka – výběr TOP(100 PERCENT) stejně nemá smysl. Myšlenka struktur tabulek je odvozena z konceptu teorie relačních databází známého jako relace.
-
Při zpracování dotazu, který se odkazuje na zobrazení, se dotaz z definice zobrazení rozbalí neboli Expanduje a implementuje v kontextu hlavního dotazu. Konsolidovaný kód(dotaz) se pak optimalizuje a provede.
ITVF (Inline Table Valued Functions)
ITVF jsou opakovaně použitelné tabulkové výrazy, které podporují vstupní parametry. S funkcemi lze zacházet jako s parametrizovanými pohledy.
CTE (Common Table Expressions)
Obvyklé tabulkové výrazy jsou podobné odvozeným tabulkám, ale mají několik důležitých výhod;
CTE se definuje pomocí příkazu WITH, po kterém následuje definice tabulkového výrazu. Aby se předešlo nejasnostem (TSQL používá klíčové slovo WITH pro jiné účely, tj. WITH ENCRYPTION atd.), MUSÍ být příkaz předcházející klauzuli WITH CTE ukončen polosloupcem. To není nutné, pokud je klauzule WITH úplně prvním příkazem v dávce, tj. v definici VIEW/ITVF)
POZNÁMKA: Polosloupec, ukončovač příkazu, je podporován normou ANSI a v rámci programátorské praxe TSQL se důrazně doporučuje jej používat.
Rekurzivní CTE
SQL Server podporuje možnosti rekurzivního dotazování implementované prostřednictvím rekurzivních CTE od verze 2005(Yukon).
Elementy rekurzivního CTE
- Kotevní člen(y) – definice dotazu, který;
- vrací platnou relační tabulku výsledků
- se provádí POUZE JEDNOU na začátku provádění dotazu
- je umístěn vždy před první definicí rekurzivního členu
- za posledním kotevním členem musí následovat operátor UNION ALL. Operátor kombinuje poslední kotevní člen s prvním rekurzivním členem
- Operátor vícenásobné množiny UNION ALL. Operátor operuje s
- rekurzivním členem (členy) – Definice dotazů, které;
- vracejí platnou relační tabulku výsledků
- mají odkaz na název CTE. Odkaz na název CTE logicky představuje předchozí sadu výsledků v posloupnosti provedení. tj. první „předchozí“ sada výsledků v posloupnosti je výsledek, který vrátil kotevní člen.
- Invokace CTE – Závěrečný příkaz, který vyvolává rekurzi
- Mechanismus zabezpečení proti selhání – volba MAXRECURSION zabraňuje databázovému systému v nekonečných smyčkách. Jedná se o nepovinný prvek.
Kontrola ukončení
Rekurzivní člen CTE nemá explicitní kontrolu ukončení rekurze.
V mnoha programovacích jazycích můžeme navrhnout metodu, která volá sama sebe – rekurzivní metodu. Každá rekurzivní metoda musí být ukončena při splnění určitých podmínek. Jedná se o explicitní ukončení rekurze. Po tomto okamžiku začne metoda vracet hodnoty. Bez bodu ukončení může rekurze skončit voláním sebe sama „donekonečna“.
Kontrola ukončení rekurzivního členu CTE je implicitní , což znamená, že rekurze se zastaví, když z předchozího provedení CTE nejsou vráceny žádné řádky.
Tady je klasický příklad rekurze v imperativním programování. Níže uvedený kód počítá faktoriál celého čísla pomocí rekurzivního volání funkce(metody).
Kompletní kód konzolového programu naleznete zde.
MAXRECURSION
Jak bylo uvedeno výše, rekurzivní CTE i jakákoli rekurzivní operace může způsobit nekonečné smyčky, pokud není správně navržena. Tato situace může mít negativní dopad na výkon databáze. Stroj Sql Serveru má mechanismus zabezpečení proti selhání, který nedovoluje nekonečné provádění.
Ve výchozím nastavení je počet vyvolání rekurzivního členu omezen na 100 (nepočítá se jednorázové provedení kotvy). Kód selže při 101. provedení rekurzivního členu.
Msg 530, Level 16, State 1, Line xxx
Příkaz byl ukončen. Maximální počet rekurzí 100 byl vyčerpán před dokončením příkazu.
Počet rekurzí se řídí volbou dotazu MAXRECURSION n. Tato volba může přepsat výchozí počet maximálních povolených rekurzí. Parametr (n) představuje úroveň rekurze. 0<=n <=32767
Důležitá poznámka:: MAXRECURSION 0 – zakazuje omezení rekurze!
Obrázek 1 ukazuje příklad rekurzivního CTE s jeho prvky

Obrázek 1, Prvky rekurzivního CTE
Deklarativní rekurze je zcela jiná než tradiční, imperativní rekurze. Kromě odlišné struktury kódu můžeme pozorovat rozdíl mezi explicitní a implicitní kontrolou ukončení. V příkladu CalculateFactorial je explicitní bod ukončení jasně definován podmínkou: if (number == 0) then return 1.
V případě výše uvedeného rekurzivního CTE je bod ukončení implicitně definován operací INNER JOIN, konkrétně výsledkem logického výrazu v její klauzuli ON: ON e.MgrId = c.EmpId. Výsledek operace tabulky určuje počet rekurzí. To bude jasnější v následujících kapitolách.
Použití rekurzivních CTE k řešení hierarchie zaměstnanců
Existuje mnoho scénářů, kdy můžeme použít rekurzivní CTE, tj. k oddělení prvků atd. Nejčastějším scénářem, se kterým jsem se během mnoha let sekvencování setkal, bylo použití rekurzivních CTE k řešení různých hierarchických problémů.
Stromová hierarchie zaměstnanců je klasickým příkladem hierarchického problému, který lze řešit pomocí rekurzivních CTE.
Příklad
Řekněme, že máme organizaci s 12 zaměstnanci. Platí následující obchodní pravidla;
- Zaměstnanec musí mít jedinečné ID, EmpId
- vynucené: Primární klíč omezení na sloupci EmpId
- Zaměstnanec může být řízen 0 nebo 1 manažerem.
- vynuceno:
- Manažer může řídit jednoho nebo více zaměstnanců.
- vynuceno: PK na EmpId, FK na MgrId a NULLable MgrId sloupec
- Manažer může řídit jednoho nebo více zaměstnanců: MgrId
- vynuceno: Stromová hierarchie je implementována v tabulce s názvem dbo.Employees. Skripty naleznete zde.

Obrázek 2, tabulka ZaměstnanciPředstavíme si způsob fungování rekurzivních CTE odpovědí na otázku:
Z hierarchického stromu na obrázku 2 jasně vidíme, že manažer (EmpId = 3) přímo řídí zaměstnance; EmpId=7, EmpId=8 a EmpId=9 a nepřímo řídí; EmpId=10, EmpId=11 a EmpId=12.
Obrázek 3 ukazuje hierarchii EmpId=3 a očekávaný výsledek. Kód naleznete zde.

Obrázek 3, EmpId=3 přímí a nepřímí podřízeníJak jsme tedy získali konečný výsledek.
Rekurzivní část v aktuální iteraci vždy odkazuje na svůj předchozí výsledek z předchozí iterace. Výsledkem je tabulkový výraz(nebo virtuální tabulka) s názvem cte1(tabulka na pravé straně INNER JOIN). Jak vidíme, cte1 obsahuje i kotevní část. Při úplně prvním spuštění(první iterace) se rekurzivní část nemůže odkazovat na svůj předchozí výsledek, protože žádná předchozí iterace neproběhla. Proto se v první iteraci provede pouze kotevní část, a to pouze jednou během celého procesu. Množina výsledků dotazu kotvy poskytne rekurzivní části její předchozí výsledek ve druhé iteraci. Kotva funguje jako setrvačník, chcete-li 🙂
Konečný výsledek se vytváří prostřednictvím iterací, tj. výsledek kotvy + výsledek iterace 1 + výsledek iterace 2 …
Logická posloupnost provádění
Testovací dotaz se provádí podle následující logické posloupnosti:
- Příkaz SELECT mimo výraz cte1 vyvolá rekurzi. Zakotvený dotaz se provede a vrátí virtuální tabulku s názvem cte1. Rekurzivní část vrátí prázdnou tabulku, protože nemá svůj předchozí výsledek. Nezapomeňte, že výrazy v přístupu založeném na množině se vyhodnocují všechny najednou.
 Obrázek 4, hodnota cte1 po 1. iteraci
Obrázek 4, hodnota cte1 po 1. iteraci - Začíná druhá iterace. to je první rekurze. V první iteraci sehrála svou roli kotevní část, která od této chvíle vrací pouze prázdné množiny. Rekurzivní část se však nyní může odkazovat na svůj předchozí výsledek(hodnota cte1 po první iteraci) v operátoru INNER JOIN. Operace tabulky vytvoří výsledek druhé iterace, jak ukazuje obrázek níže.
 FIgure 5, cte1 value after 2nd iteration
FIgure 5, cte1 value after 2nd iteration - Druhá iterace vytvoří neprázdnou množinu, takže proces pokračuje třetí iterací – druhou rekurzí. Rekurzivní prvek nyní odkazuje na výsledek cte1 z druhé iterace.
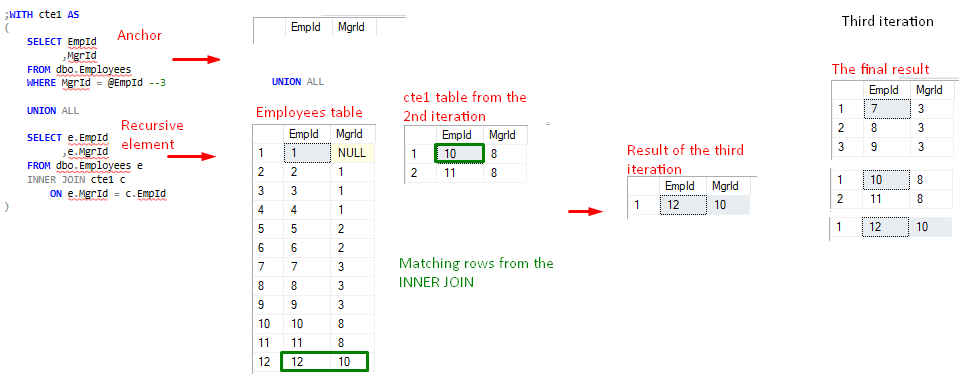
FIgure 6, cte1 value after 3rd iteration - Ve čtvrté iteraci – třetím pokusu o rekurzi – se stane zajímavá věc. Podle předchozího vzoru rekurzivní prvek použije výsledek cte1 z předchozí iterace. Tentokrát však nejsou vráceny žádné řádky jako výsledek operace INNER JOIN a rekurzivní prvek vrací prázdnou množinu. To je již zmíněný implicitní bod ukončení. V tomto případě diktuje počet rekurzí vyhodnocení logického výrazu INNER JOIN.
Protože posledním výsledkem cte1 je prázdná množina výsledků, je 4. iterace(neboli 3. rekurze) „zrušena“ a proces je úspěšně ukončen.
Obrázek 7, Závěrečná iterace
Logické zrušení 3. rekurze (poslední rekurze, která přinesla prázdnou množinu výsledků, se nepočítá) bude jasnější v následující, rekurzivní části analýzy plánu provádění CTE.Na konec dotazu můžeme přidat volbu OPTION(MAXRECURSION 2), která omezí počet povolených rekurzí na 2. Dotaz poskytne správný výsledek dokazující, že pro tuto úlohu jsou nutné pouze dvě rekurze.Poznámka: Z hlediska fyzického provedení je sada výsledků postupně(podle toho, jak řádky probublávají) odesílána do síťových vyrovnávacích pamětí a zpět do klientské aplikace.
Nakonec odpověď na výše uvedenou otázku zní :
Existuje šest zaměstnanců, kteří přímo nebo nepřímo podléhají společnosti Emp = 3.
Přímo nebo nepřímo podléhají společnosti Emp. Tři zaměstnanci, EmpId=7, EmpId=8 a EmpId=9 jsou přímí podřízení a EmpId=10, EmpId=11 a EmpId=12 jsou nepřímí podřízení.Známe-li mechaniku rekurzivního CTE, můžeme snadno vyřešit následující problémy.
- najít všechny zaměstnance, kteří jsou hierarchicky nad EmpId=10 (kód zde)
- najít EmpId=8 ‚přímé a druhé úrovně podřízené(kód zde)
V druhém příkladu kontrolujeme hloubku hierarchie omezením počtu rekurzí.
Prvkem kotva získáme první úroveň hierarchie, v tomto případě přímé podřízené. Každá rekurze pak posouvá první úroveň hierarchie o jednu úroveň níže. V příkladu je výchozím bodem EmpId=8 a jeho přímí podřízení. První rekurze posouvá hierarchii ještě o jednu úroveň níže, kde „žijí“ podřízení druhé úrovně EmpId=8.Problém kruhové reference
Jednou ze zajímavých věcí u hierarchií je, že členy hierarchie mohou tvořit uzavřenou smyčku, kde poslední prvek hierarchie odkazuje na první prvek. Uzavřená smyčka je také známá jako kruhová reference.
V takových případech implicitní ukončovací bod, jako je dříve vysvětlená operace INNER JOIN, jednoduše nebude fungovat, protože vždy vrátí neprázdnou množinu výsledků pro další pokračování rekurze. Část rekurze bude pokračovat, dokud nenarazí na pojistku Sql Serveru proti selhání, možnost dotazu MAXRECURSION.Pro demonstraci situace s kruhovou referencí pomocí dříve nastaveného testovacího prostředí budeme muset
- Odstranit omezení primárního a cizího klíče z tabulky dbo.Employees, abychom umožnili scénáře uzavřených smyček.
- Vytvořit kruhový odkaz (EmpId=10 bude řídit jeho nepřímý nadřízený , EmpId = 3)
- Rozšířit testovací dotaz použitý v předchozích příkladech, aby bylo možné analyzovat hierarchii prvků v uzavřené smyčce.
Rozšířený testovací dotaz naleznete zde.
Než budeme pokračovat v příkladu s kruhovým odkazem, podívejme se, jak funguje rozšířený testovací dotaz. Zakomentujte predikáty klauzule WHERE(poslední dva řádky) a spusťte dotaz proti původní tabulce dbo.Employee
 Obrázek 8, Zjišťování existence kruhových smyček v hierarchiích
Obrázek 8, Zjišťování existence kruhových smyček v hierarchiíchVýsledek rozšířeného dotazu je naprosto stejný jako výsledek prezentovaný v předchozím experimentu na obrázku 3. Výstup je rozšířen o následující sloupce
- pth – graficky znázorňuje aktuální hierarchii. Zpočátku v rámci kotevní části jednoduše přidá prvního podřízeného k MgrId=3, tedy manažerovi, od kterého začínáme. Nyní každý rekurzivní prvek přebírá předchozí hodnotu pth a přidává k ní dalšího podřízeného.
- recLvl – představuje aktuální úroveň rekurze. Provedení kotvy se počítá jako recLvl=0
- isCircRef – zjišťuje existenci kruhové reference v aktuální hierarchii(řádku). V rámci rekurzivního prvku hledá existenci EmpId, který byl dříve obsažen v řetězci pth.
i.e pokud předchozí pth vypadá jako 3->8->10 a aktuální rekurze přidá “ ->3 „, (3->8 >10 -> 3), což znamená, že EmpId=3 je nejen nepřímým nadřízeným EmpId=10, ale je také podřízeným EmpId=10 – situace typu já jsem šéf nebo tvůj šéf a ty jsi můj šéf 😐
Provedeme nyní potřebné změny na dbo.Employees, abychom viděli rozšířený testovací dotaz v akci.
Odstraňte omezení PK a FK, abyste umožnili kruhové odkazy, a přidejte do tabulky „zlobivý chlapec s kruhovým odkazem“.
Spusťte rozšířený testovací dotaz a analyzujte výsledky (nezapomeňte odkomentovat dříve zakomentovanou klauzuli WHERE na konci skriptu)
Skript provede 100 rekurzí, než bude přerušen výchozí MAXRECURSION. Konečný výsledek bude omezen na dvě rekurze .. AND cte1.recLvl <= 2; což je nutné pro vyřešení hierarchie EmpId=3.Obrázek 9 ukazuje hierarchii uzavřené smyčky, maximální povolený počet rekurzí vyčerpaných chyb a výstup, který ukazuje uzavřenou smyčku.

Obrázek 10, Zjištěna kruhová referenceNěkolik poznámek ke skriptu kruhové reference:
Skript je pouze představou, jak najít uzavřené smyčky v hierarchiích. Hlásí pouze první výskyt kruhové reference – zkuste odstranit klauzuli WHERE a pozorujte výsledek.
Dle mého názoru lze skript (nebo podobné verze skriptu) použít v produkčním prostředí mj. pro účely řešení problémů nebo jako prevenci před vytvářením kruhových referencí v existující hierarchii. Je však třeba jej zabezpečit vhodnou MAXRECURSION n, kde n je předpokládaná hloubka hierarchie.Tento skript není relační a spoléhá na techniku procházení. Vždy je nejlepší použít deklarativní omezení (PK, FK, CHECK..), aby se zabránilo jakýmkoli uzavřeným smyčkám v datech.
Analýza plánu provedení
Tento segment vysvětluje, jak optimalizátor dotazů Sql Serveru(QO) implementuje rekurzivní CTE. Existuje společný vzor, který QO používá při konstrukci plánu provádění. Spusťte původní testovací dotaz a připojte aktuální plán provádění
Stejně jako testovací dotaz má plán provádění dvě větve: kotevní větev a rekurzivní větev. Operátor konkatenace, který implementuje operátor UNION ALL, spojuje výsledky z obou částí tvořících výsledek dotazu.
Pokusíme se sladit dříve uvedenou logickou posloupnost provádění a skutečné provedení procesu.
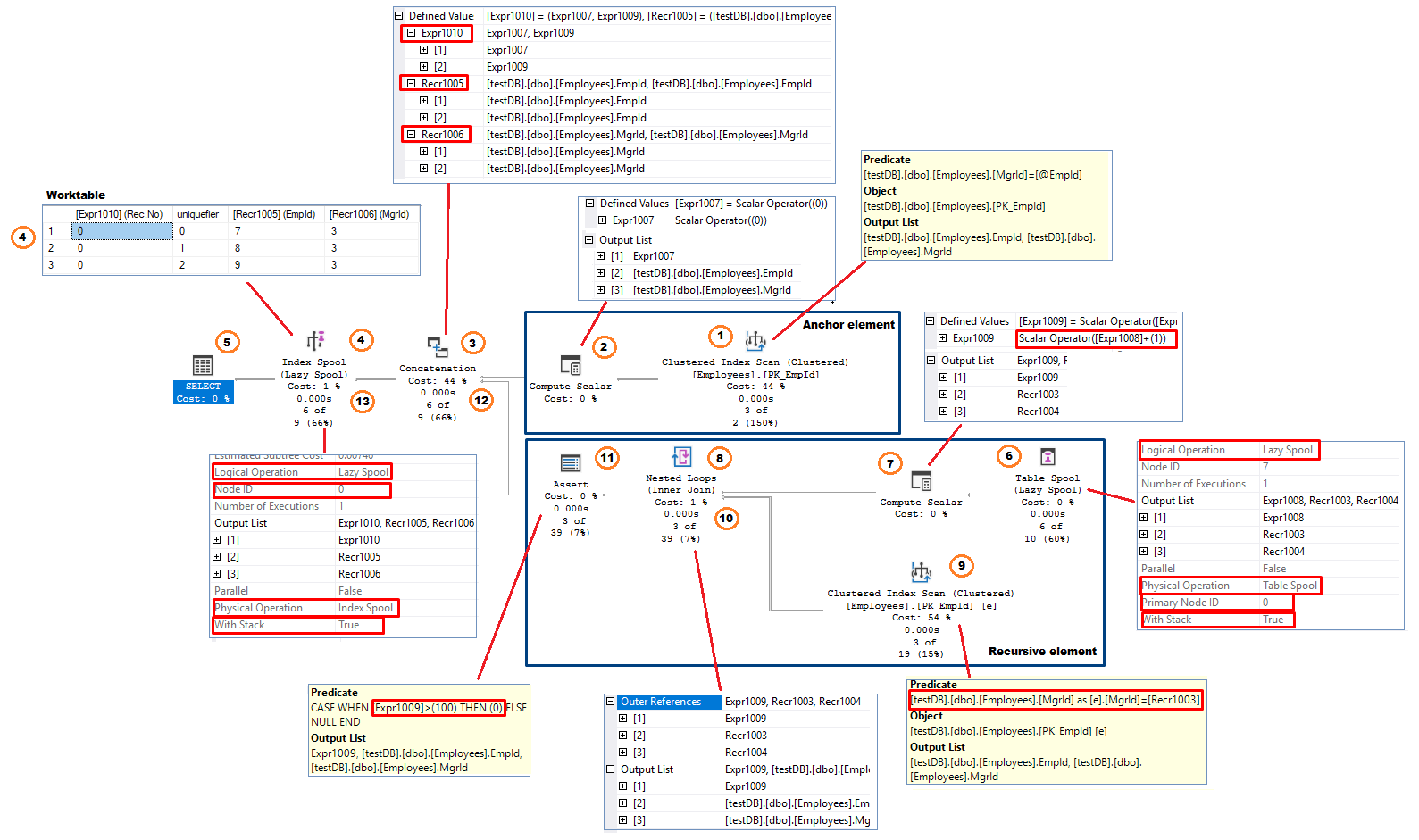
Obrázek 11, Plán provádění rekurzivního CTEPodle toku dat (směrem zprava doleva) vypadá proces takto:
Prvek ukotvení (provede se pouze jednou)
- Operátor Clustered Index Scan – systém provede skenování indexů. V tomto příkladu použije výraz MgrId = @EmpId jako zbytkový predikát. Vybrané řádky(sloupce EmpId a MgrId) jsou předány (řádek po řádku) zpět předchozímu operátoru.
- Výpočet skaláru Operátor přidá na výstup sloupec. V tomto příkladu je název přidaného sloupce . Ten představuje počet rekurzí. Sloupec má počáteční hodnotu 0; =0
- Konkatenace – spojí vstupy ze dvou větví. V první iteraci operátor přijímá řádky pouze z kotevní větve. Mění také názvy výstupních sloupců. V tomto příkladu jsou nová jména sloupců:
- = nebo * * drží počet rekurzí přiřazených v rekurzivní větvi. V první iteraci nemá hodnotu.
- = EmpId(z kotevní části) nebo EmpId(z rekurzivní části)
- = MgrId(z kotevní části) nebo MgrId (z rekurzivní části)
- Index Spool (Lazy Spool) Tento operátor ukládá výsledek získaný od operátoru Concatenation do pracovní tabulky. Má vlastnost „Logická operace“ nastavenou na „Lazy Spool“. To znamená, že operátor vrací své vstupní řádky okamžitě a nehromadí všechny řádky, dokud nezíská konečnou sadu výsledků (Eager Spool) . Pracovní tabulka je strukturována jako shlukový index s klíčovým sloupcem – rekurzivním číslem. Protože klíč indexu není jedinečný, přidává systém ke klíči indexu interní, čtyřbytový unikátor, aby zajistil, že všechny řádky v indexu jsou z hlediska fyzické implementace jednoznačně identifikovatelné. Operátor má také nastavenou vlastnost „With Stack“ na „True“, což z této verze operátoru spoolu dělá zásobníkový spool Operátor zásobníkového spoolu má vždy dvě součásti – indexový spool, který vytváří strukturu indexu, a tabulkový spool, který funguje jako konzument řádků uložených v pracovní tabulce, která byla vytvořena indexovým spoolem.
V této fázi operátor Index Spool vrací řádky operátoru SELECT a ukládá tytéž řádky do pracovní tabulky. - Operátor SELECT vrací EmpId a MgrId ( , ). Z výsledku vylučuje. Řádky jsou odesílány do síťové vyrovnávací paměti tak, jak přicházejí od operátorů za sebou
Po vyčerpání všech řádků od operátoru Index Scan přepne operátor Concatenation kontext na rekurzivní větev. Kotvící větev nebude v průběhu procesu znovu provedena.
Rekurzivní prvek
- Tabulkový zásobník (Lazy Spool). Operátor nemá žádné vstupy a, jak je uvedeno v (4), funguje jako konzument řádků vytvořených Index Spool a uložených ve sdružené pracovní tabulce. Má vlastnost „Primary Node“ nastavenou na 0, která ukazuje na ID uzlu Index Spool. To zvýrazňuje závislost obou operátorů. Operátor
- odstraní řádky, které načetl v předchozí rekurzi. Jedná se o první rekurzi a nejsou zde žádné dříve načtené řádky, které by bylo třeba odstranit. Pracovní tabulka obsahuje tři řádky (obrázek 4):
- Čtené řádky seřazené podle indexového klíče + unifikátoru v sestupném pořadí. V tomto příkladu je první načtený řádek EmpId=9, MgrId=3.
Nakonec operátor přejmenuje názvy výstupních sloupců. =, = a stane se .
POZNÁMKA: Operátor tabulkového spoolu lze pozorovat jako výraz cte1 na pravé straně INNER JOIN (obrázek 4) - Výpočet Scalar Operátor přičte 1 k aktuálnímu počtu rekurzí dříve uložených ve sloupci . výsledek se uloží do nového sloupce, . = + 1 = 0 + 1 = 1. Výstupem operátoru jsou tři sloupce, dva z tabulkového zásobníku ( a ) a
- Operátor Nested Loop(I) obdrží řádky ze svého vnějšího vstupu, kterým je Compute Scalar z předchozího kroku, a poté použije – představuje EmpId z operátoru Table Spool, jako zbytkový predikát v operátoru Index Scan umístěném ve vnitřním vstupu smyčky. Vnitřní vstup se provede jednou pro každý řádek z vnějšího vstupu.
- Operátor Index Scan vrátí všechny kvalifikované řádky z tabulky dbo.Employees (dva sloupce; EmpId a MgrId) do operátoru vnořené smyčky.
- Vnořená smyčka(II):
- Operátor Assert slouží ke kontrole podmínek, které vyžadují přerušení dotazu s chybovou zprávou. V případě rekurzivních CTE , operátor assert implementuje možnost dotazu „MAXRECURSION n“. Kontroluje, zda rekurzivní část dosáhla povoleného (n) počtu rekurzí nebo ne. Pokud je aktuální počet rekurzí (viz krok 7) větší než (n), operátor vrátí 0 a způsobí chybu při běhu. V tomto příkladu používá Sql Server svou výchozí hodnotu MAXRECURSION 100. Výraz vypadá takto: CASE WHEN > 100 THEN 0 ELSE NULL Pokud se rozhodneme vyloučit failsafe přidáním MAXRECURSION 0, operátor assert nebude do plánu zahrnut. Tentokrát obdrží vstup pouze z rekurzivní části a výstupem jsou sloupce/řádky, jak je uvedeno v kroku 3.
- Index Spool (Lazy Spool) přidá výstup z operátoru concatenation do pracovní tabulky a poté jej předá operátoru SELECT. V tomto okamžiku obsahuje pracovní tabulka celkem 4 řádky: tři řádky z provedení kotvy a jeden z první rekurze. V návaznosti na shlukovou indexovou strukturu pracovní tabulky se nový řádek uloží na konec pracovní tabulky
-
Proces nyní pokračuje od kroku 6. Operátor spojování tabulek odstraní dříve načtené řádky (první tři řádky) z pracovní tabulky a načte poslední vložený řádek, čtvrtý řádek.
Závěr
CTE(Common table expressions) je typ tabulkových výrazů dostupných v systému Sql Server. CTE je nezávislý tabulkový výraz, který lze pojmenovat a odkazovat na něj jednou nebo vícekrát v hlavním dotazu.
Jedním z nejdůležitějších použití CTE je psaní rekurzivních dotazů. Rekurzivní CTE mají vždy stejnou strukturu – kotevní dotaz, vícenásobný operátor UNION ALL, rekurzivní člen a příkaz, který rekurzi vyvolává. Rekurzivní CTE je deklarativní rekurze a jako taková má jiné vlastnosti než její imperativní protějšek, např. kontrola ukončení deklarativní rekurze je implicitní povahy – proces rekurze se zastaví, když v předchozím cte nejsou vráceny žádné řádky. - Příkaz SELECT mimo výraz cte1 vyvolá rekurzi. Zakotvený dotaz se provede a vrátí virtuální tabulku s názvem cte1. Rekurzivní část vrátí prázdnou tabulku, protože nemá svůj předchozí výsledek. Nezapomeňte, že výrazy v přístupu založeném na množině se vyhodnocují všechny najednou.
Napsat komentář