Jak používat Tesseract v systému Windows
On 14 ledna, 2022 by admin
Tesseract je software pro optické rozpoznávání znaků, který vyvinula společnost Google. Jedná se o nástroj OCR s otevřeným zdrojovým kódem. Existuje mnoho verzí tesseractu, ale my budeme používat verzi 4.0.
Ve verzi 4 má tesseract implementován rozpoznávací engine založený na technologii LSTM (Long Short Term Memory). LSTM je druh rekurentní neuronové sítě (RNN). Rozpoznávání založené na LSTM funguje mnohem efektivněji než staré (na CNN založené) rozpoznávací procesy.
Díky tesseractu budeme moci ukládat obsah našich obrázků jako textové soubory.
Instalace
Isntalace závisí na vašem operačním systému. Nyní si projdeme okna. Nejprve si stáhneme a nainstalujeme tesseract prostřednictvím tohoto odkazu. (Stáhne se exe soubor.) Exe soubor snadno nastavíme.
Poté bychom měli přidat PATH do systémových proměnných windows. Je to vlastně snadný krok. Nejprve najdeme a zkopírujeme kořenovou složku instalace tesseractu. Bude vypadat takto :
C:\Program Files\Tesseract-OCR
A pak do vyhledávacího řádku windows Rozšířená systémová nastavení
Rozšířená systémová nastavení > Rozšířené > Proměnné prostředí > PATH > Nový
Vložíme zdrojovou cestu, kterou jsme zkopírovali, a tuto konfiguraci uložíme. Po tomto kroku musí být počítač restartován, aby se konfigurace použily.
Instalace tesseractu byla dokončena. Instalaci můžete potvrdit z příkazového řádku. Když na příkazovém řádku spustíme příkaz tesseract, měl by nám poskytnout informace o programu.
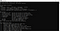
Nyní můžeme přejít k části python. Abychom mohli používat tesseract v jazyce python, měli bychom si stáhnout knihovnu pytesseract. Tuto knihovnu lze stáhnout pomocí pip do prostředí, které používáte.
pip install pytesseract
Nyní je tesseract připraven k použití!!!
Kódování
Používání tesseractu je opravdu jednoduché. Nejtěžší je optimalizace nastavení.
Protože pokud chcete provést úspěšný ocr, musíte být opatrní v kroku zpracování obrazu a nastavení ocr.
Použijeme OCR na účtenku.

Importování knihoven
import pytesseract
from PIL import Image
import cv2
import numpy as np
Nastavení hodnoty DPI obrázku
Hustota bodů na palec (DPI nebo dpi) je měřítkem hustoty bodů videa nebo obrazového skeneru. Hodnota DPI je důležitá pro spuštění OCR. Pokud je totiž hodnota DPI nižší než 300, může to snížit úspěšnost OCR.
file_path= 'receipt.jpg'
im = Image.open(file_path)
im.save('ocr.png', dpi=(300, 300))
Použití některých technik k vyčištění obrázku
Nejprve si obrázek škálujeme pomocí x2. Pokud jsou znaky malé, pak musíme obrázek zmenšit, abychom jej rozpoznali. Poté použijeme jednoduchou prahovou techniku. Její binární práh. Nejprve je třeba vyzkoušet hodnotu 127. Poté lze vyzkoušet různé proměnné. Thrashold změní pixel na černý, pokud je hodnota pixelu vyšší než prahová hodnota. Pokud vytvoříme obrázek ve stupních šedi, získáme černobílý obrázek.
Existují různé prahové techniky. Na zdrojové webové stránky se můžete podívat pomocí tohoto odkazu.

Spustit Tesseract
Nyní můžeme spustit tesseract. Má funkci image_to_string(). Ta nám jako výstup poskytne řetězec.
text = pytesseract.image_to_string(treshold)
Uložení výstupu
Výstup můžeme uložit pomocí následujícího kódu.
with open("Output.txt", "w",5 ,"utf-8") as text_file:
text_file.write(text)
Výstup OCR je následující:
Výsledek je velmi úspěšný. Pokud je požadována vyšší úspěšnost, lze na obrázek aplikovat různé operace.
Napsat komentář