Como funciona a Web
On Outubro 15, 2021 by adminA Web está em todo o lado!
Utilizamo-la mais do que nunca – também em muitos lugares onde você pode não a ver. Porque “a web” é mais do que apenas websites que você visita digitando uma URL no seu navegador.
Não importa se você verifica seus e-mails no seu celular ou se você está enviando um tweet – você está usando a internet (ou seja, “a web”).
Como tudo isso funciona? Que tecnologias estão envolvidas e o que você precisa aprender (e até que ponto) se quiser se tornar um desenvolvedor web?
Neste artigo e vídeo (veja acima), eu não vou mergulhar em todos os detalhes técnicos. Isto pretende ser uma boa visão geral da funcionalidade web.

CSS – The Complete Guide
Junte-se a este abrangente curso de 20h+ para dominar o CSS e aprender como criar belos sites.

JavaScript – O Guia Completo
Aprenda JavaScript do zero para construir websites altamente interativos e dinâmicos neste curso prático!
# Como funcionam os websites
Comecemos com a maneira mais óbvia de usar a internet: Você visita um site como academind.com.
No momento em que você digita este endereço no seu navegador e carrega no ENTER, muitas coisas diferentes acontecem:
- A URL é resolvida
- Um pedido é enviado ao servidor do site
- A resposta do servidor é analisado
- A página é renderizada e exibida

Atualmente, cada passo poderia ser dividido em vários outros passos, mas para uma boa visão geral de como tudo isso funciona, isso é algo que podemos ignorar aqui. Vamos dar uma olhada nos quatro passos.
Passo 1 – URL Gets Resolved
O código do site obviamente não é armazenado em sua máquina e, portanto, precisa ser obtido de outro computador onde ele está armazenado. Este “outro computador” é chamado de “servidor”. Porque serve para algum propósito, no nosso caso, serve o website.
Você entra em “academind.com”. (que é chamado “um domínio”), mas na verdade, o servidor que hospeda o código fonte de um website, é identificado através de endereços IP (= Internet Protocol). O navegador envia um “pedido” (ver passo 2) para o servidor com o endereço IP que você digitou (indiretamente – você, é claro, digitou “academind.com”).
Na realidade, você também entra frequentemente "academind.com/learn" ou algo parecido. "academind.com" é o domínio, "/learn" é o chamado caminho. Juntos, eles compõem o “URL” (“Uniform Resource Locator”).
Além disso, você pode visitar a maioria dos sites através de "www.academind.com" ou apenas "academind.com". Tecnicamente, "www" é um subdomínio, mas a maioria dos sites simplesmente redireciona o tráfego para "www" para a página principal.
Um endereço IP normalmente se parece com este: 172.56.180.5 (embora também exista uma forma mais “moderna” chamada IPv6 – mas vamos ignorar isso por enquanto). Você pode aprender mais sobre endereços IP na Wikipedia.
Como o domínio “academind.com” é traduzido para seu endereço IP?
Existe um tipo especial de servidor na Internet – não apenas um, mas muitos servidores desse tipo. Um chamado “servidor de nomes” ou “servidor DNS” (onde DNS = “Domain Name System”).
O trabalho desses servidores DNS é traduzir domínios para endereços IP. Você pode imaginar esses servidores como enormes dicionários que armazenam tabelas de tradução: Domínio => Endereço IP.
Quando você digita “academind.com”, o browser primeiro vai buscar o endereço IP de tal servidor DNS.
No caso de você estar se perguntando: O navegador sabe de cor os endereços desses servidores de domínio, eles são programados no navegador, por assim dizer.
Após o endereço IP ser conhecido, avançamos para o passo 2.
Passo 2 – Pedido é enviado
Com o endereço IP resolvido, o navegador vai em frente e faz um pedido ao servidor com esse endereço IP.
“Um pedido” não é apenas um termo. É realmente uma coisa técnica que acontece nos bastidores.
O browser reúne um monte de informações (Qual é a URL exata? Que tipo de pedido deve ser feito? Se metadados devem ser anexados) e envia esse pacote de dados para o endereço IP.
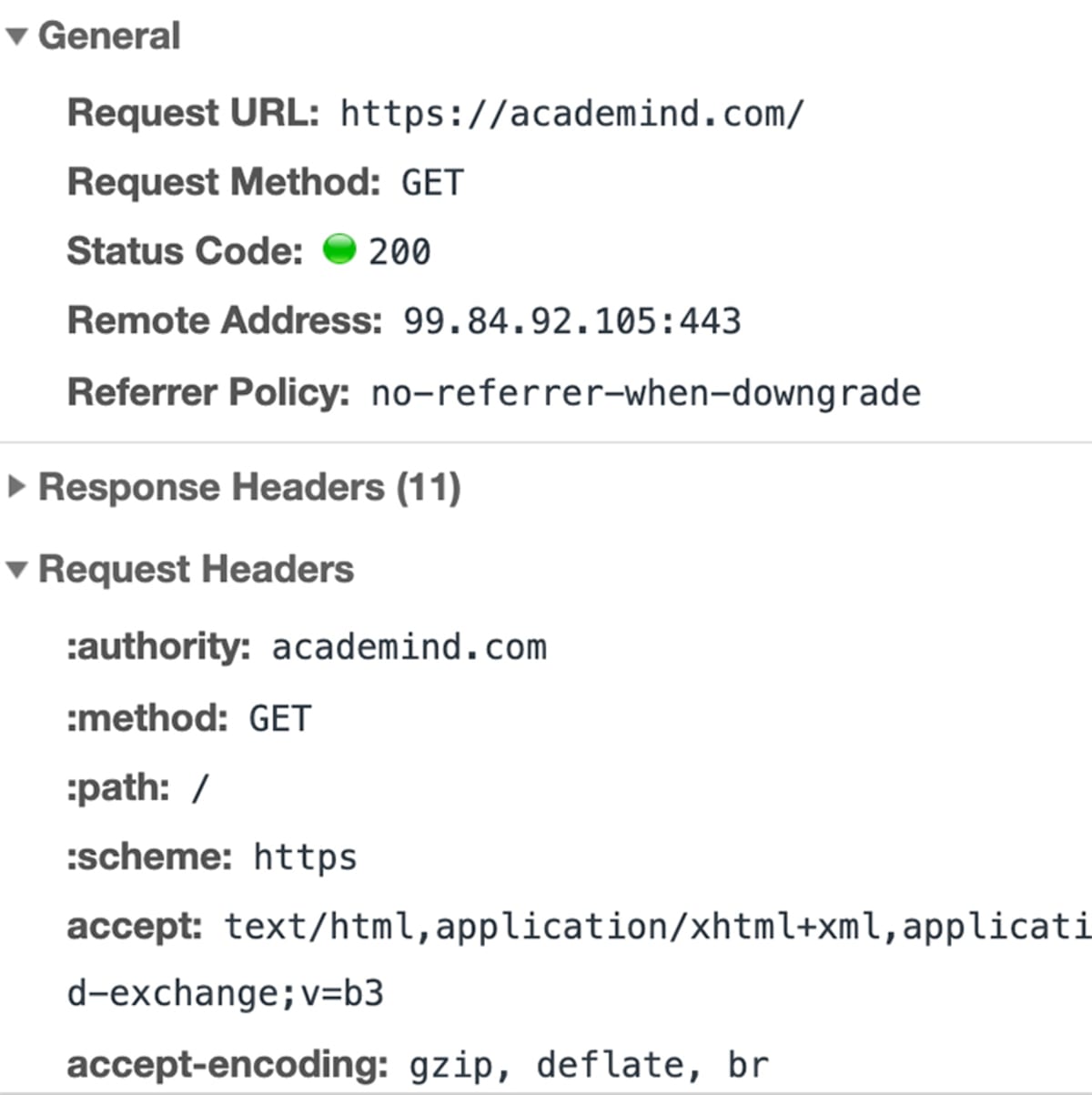
Os dados são enviados através do “HyperText Transfer Protocol” (conhecido como “HTTP”) – um protocolo padronizado que define como deve ser uma solicitação (e resposta), quais dados podem ser incluídos (e em que forma) e como a solicitação será submetida. Você pode aprender mais sobre HTTP aqui.
Porque o HTTP é usado, uma URL completa se parece realmente com isto: http://academind.com. O navegador a completa automaticamente para você.
E também há HTTPS – é como HTTP, mas criptografada. A maioria das páginas modernas (incluindo academind.com) usam isso em vez do HTTP. Uma URL completa torna-se então: https://academind.com.
Desde que todo o processo e formato seja padronizado, não há adivinhação sobre como essa requisição tem de ser lida pelo servidor.
O servidor então trata a requisição apropriadamente e retorna uma chamada “resposta”. Mais uma vez, uma “resposta” é uma coisa técnica e um pouco semelhante a uma “requisição”. Você poderia dizer que é basicamente uma “requisição” na direção oposta.
Como uma requisição, uma resposta pode conter dados, metadados, etc. Ao solicitar uma página como academind.com, a resposta conterá o código necessário para renderizar a página na tela.
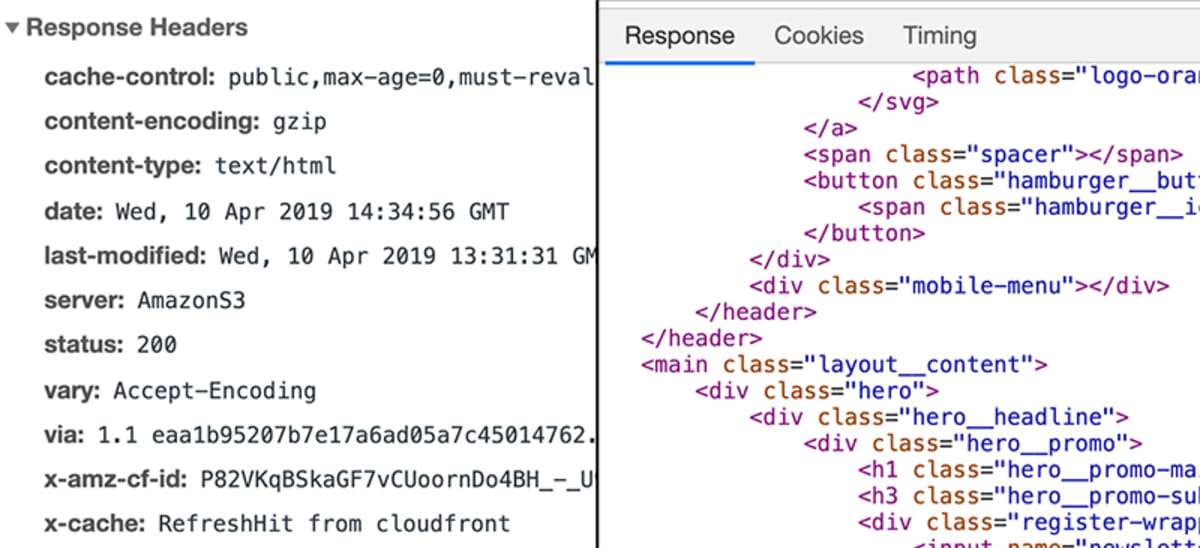
O que acontece no servidor?
Isso é definido pelos desenvolvedores web. No final, uma resposta tem de ser enviada. Essa resposta não tem que conter “um website”. Ela pode conter quaisquer dados – incluindo arquivos ou imagens.
Alguns servidores são programados para gerar websites dinamicamente com base no pedido (por exemplo, uma página de perfil que contém seus dados pessoais), outros servidores retornam páginas HTML pré-geradas (por exemplo, uma página de notícias). Ou ambos são feitos – para diferentes partes de uma página web. Existe também uma terceira alternativa: Websites que são pré-gerados mas que mudam sua aparência e dados no navegador.
Os diferentes tipos de websites não são realmente o foco deste artigo. Se você quiser saber mais sobre isso, veja este artigo + vídeo.
Para o nosso caso simples temos um servidor que retorna o código para exibir um site. Então vamos continuar com o passo 3.
Passo 3 – Resposta é Parsed
O browser recebe a resposta enviada pelo servidor. Isto por si só, não mostra nada na tela, no entanto.
Em vez disso, o próximo passo é que o navegador analisa a resposta. Assim como o servidor o fez com a requisição. Novamente, a padronização aplicada por HTTP ajuda, é claro.
O navegador verifica os dados e metadados que estão contidos na resposta. E com base nisso, ele decide o que fazer.
Você pode ter tido casos em que um PDF foi aberto no seu navegador. Isso aconteceu porque a resposta informou ao navegador que os dados não são um site, mas sim um documento PDF. E o navegador tenta escolher o melhor mecanismo de manipulação para qualquer tipo de dado que detecta.
Voltar ao cenário do nosso website.
Nesse caso, a resposta conteria um pedaço específico de metadados, que diz ao navegador que os dados da resposta são do tipo text/html.
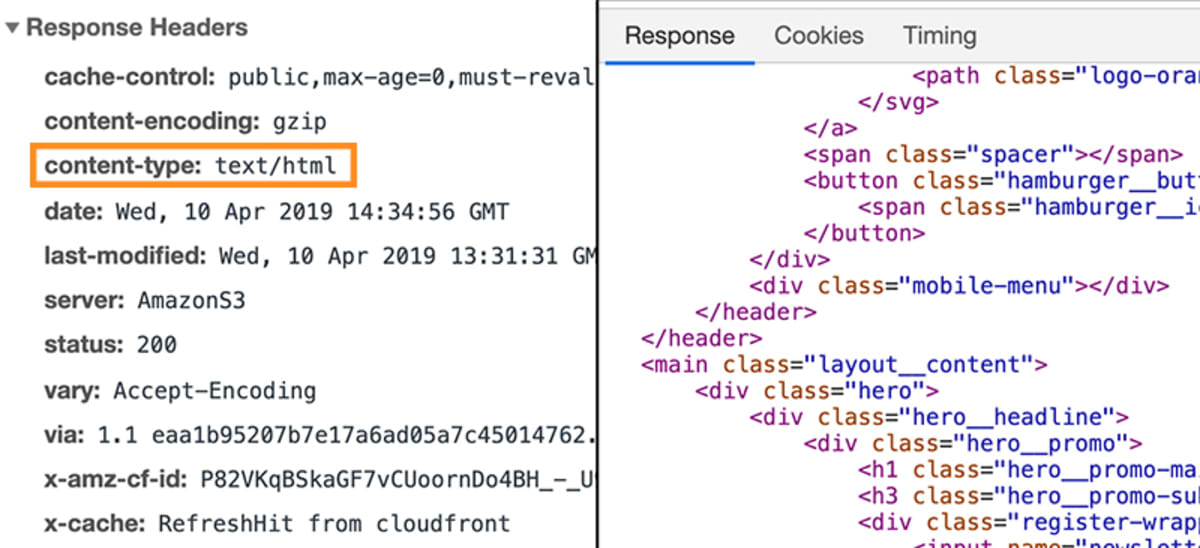
Isso permite que o navegador analise os dados reais que estão anexados à resposta como código HTML.
HTML é o núcleo da “linguagem de programação” (tecnicamente, não é uma linguagem de programação – você não pode escrever nenhuma lógica com ela) da web. HTML significa “Hyper Text Markup Language” e descreve a estrutura de uma página web.
O código é assim:
<h1>Breaking News!</h1><p>Websites work because browser understand HTML!</p><h1> e <p> são as chamadas “HTML tags” e se você quiser aprender mais sobre HTML, esta série é um ótimo lugar para ir.
Todas as tags HTML têm algum significado semântico que o navegador entende, porque HTML também é padronizado. Portanto, não há adivinhação sobre o significado de uma tag <h1>.
O navegador sabe como analisar o HTML e agora simplesmente passa por todos os dados de resposta (também chamados de “o corpo de resposta”) para renderizar o site.
Passo 4 – Página é exibida
Como mencionado, o navegador percorre os dados HTML retornados pelo servidor e constrói um site baseado nisso.
Embora seja importante saber, que HTML não inclui instruções sobre como o site deve ser (ou seja, como ele deve ser estilizado). Ele realmente apenas define a estrutura e diz ao navegador qual conteúdo é um cabeçalho, qual conteúdo é uma imagem, qual conteúdo é um parágrafo, etc. Isto é especialmente importante para a acessibilidade – leitores de tela obtêm todas as informações úteis da estrutura HTML.
Uma página que só inclui HTML ficaria assim:

Não tão bonito, certo?
Por isso existe outra tecnologia importante (outra “linguagem de programação”, que não é realmente uma linguagem de programação): CSS (“Cascading Style Sheets”).
CSS é tudo sobre adicionar estilo ao site. Isso é feito via “CSS rules”:
h1 { color: blue;}Esta regra coloriria todas <h1> tags blue.
Regras como essa podem ser adicionadas dentro do código HTML mas tipicamente, elas são parte de arquivos separados .css que são solicitados separadamente.
Sem mergulhar em muitos detalhes aqui, que guarda uma implicação importante: Um website pode ser composto de mais do que os dados da primeira resposta que obtemos.
Na prática, websites buscam muitos dados adicionais (através de pedidos e respostas adicionais) que são iniciados assim que a primeira resposta chega.
Como isso funciona?
Bem, o código HTML da primeira resposta simplesmente contém instruções para buscar mais dados através de novas solicitações – e o navegador entende estas instruções:
<link rel="stylesheet" href="/page-styles.css" />
Again, eu não vou mergulhar em mais detalhes aqui. Se você quiser saber mais sobre CSS, nosso Guia Completo será muito útil!
Convivendo com CSS, o navegador é capaz de exibir páginas web como esta:

Existe realmente outra linguagem de programação envolvida (desta vez, é realmente uma linguagem de programação!): JavaScript.
Nem sempre é visível, mas todo o conteúdo dinâmico que se encontra num website (por exemplo, separadores, sobreposições, etc.) só é de facto possível por causa do JavaScript. Ele permite que desenvolvedores web definam o código que roda no navegador (não no servidor), portanto o JavaScript pode ser usado para alterar o site enquanto o usuário o visualiza.
Como antes, se você quiser saber mais, confira nossos recursos de JavaScript, por exemplo, nosso curso completo.
Estes são os quatro passos que estão sempre envolvidos quando você digita um endereço de página como academind.com e depois você vê o conteúdo do site no seu navegador.
# Server-side vs Browser-side
Dos quatro passos acima, você aprendeu que podemos diferenciar dois “lados” centrais quando se fala sobre a web: Server-side e Browser-side (ou: Client-side já que também podemos acessar a internet sem navegador – veja abaixo!).
Se você está interessado em se tornar um desenvolvedor web, é importante saber que você usa diferentes tecnologias e linguagens de programação para esses lados.
Lado do servidor
Você precisa de linguagens de programação do lado do servidor – ou seja, linguagens que não funcionam no navegador mas que podem rodar em um computador normal (um servidor é, no final das contas, apenas um computador normal).
Exemplos seriam:
- Node.js
- PHP
- Python
Importante: Com exceção do PHP, você também pode usar estas linguagens de programação para outros propósitos que não o desenvolvimento web.
Whilst Node.js é de fato usado principalmente para programação do lado do servidor (embora tecnicamente não esteja limitado a isso), Python também é muito popular para ciência de dados e aprendizagem de máquinas.
Browser-side
No navegador, há exatamente três linguagens/tecnologias que você precisa aprender. Mas enquanto as linguagens do lado do servidor eram alternativas, estas três linguagens do lado do navegador são todas obrigatórias para conhecer e entender:
- HTML (para a estrutura)
- CSS (para o estilo)
- JavaScript (para conteúdo dinâmico)
# “Bastidores” Internet
Até aqui, discutimos websites. Ou seja, o caso em que você digita uma URL (por exemplo, “academind.com/learn”) no navegador e obtém um website em troca.
Mas a Internet é mais do que isso. De facto, você usa-a para mais do que isso todos os dias!
A ideia central dos pedidos e respostas é sempre a mesma. Mas nem todas as respostas são necessariamente um website. E nem todas as solicitações querem um website.
Os metadados que são anexados às solicitações e respostas controlam quais dados são desejados e retornados. Claro que ambas as partes envolvidas (ou seja, cliente e servidor) precisam suportar as solicitações e enviar dados.
Você não pode solicitar um PDF de "academind.com" por exemplo. Você poderia enviar tal pedido mas não receberia de volta um PDF – simplesmente porque não suportamos este tipo de dados solicitados para esta URL específica.
Mas existem muitos servidores especializados em fornecer URLs que retornam certos pedaços de dados. Tais serviços também são referidos como “APIs” (“Application Programming Interface”).
Por exemplo, aplicações móveis enviam solicitações HTTP “invisíveis” para tais APIs (para URLs específicas que são conhecidas por eles) para obter ou armazenar dados. Twitter está pegando o feed do tweet por exemplo.
E mesmo em páginas web, tais requisições “invisíveis” são enviadas. Se você assinar nossa newsletter (o que você deve, é claro!), nenhuma nova página será carregada. Porque os dados são trocados nos bastidores. Mesmo que o cliente seja o browser neste caso, o pedido que é enviado não quer nenhum site em troca. E a URL do servidor que a recebe não oferece nenhum website – em vez disso, o servidor sabe como lidar com o seu endereço de e-mail.
Podíamos entrar em muito mais detalhes aqui, mas este já é um longo artigo. Agora você deve ter um bom entendimento de como a web funciona e quais tecnologias centrais estão envolvidas.
Deixe uma resposta